结构图

接下来我们针对其中常用的容器进行分析:
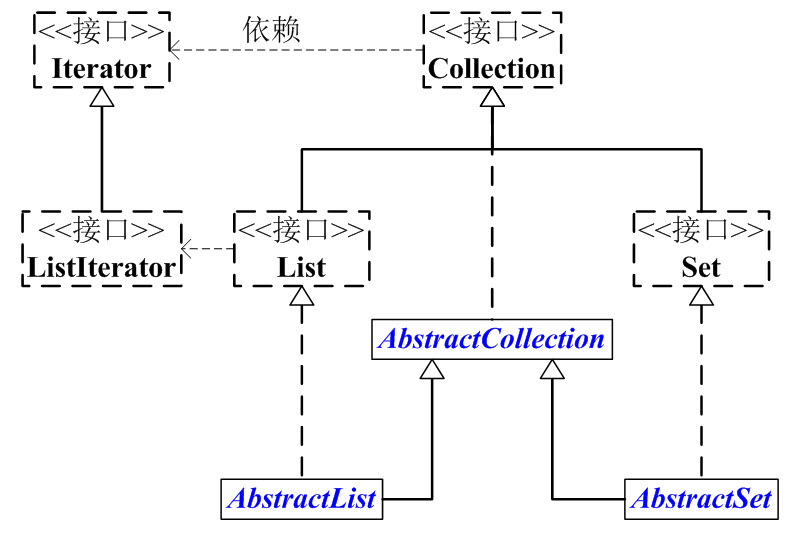
1、Collection
它是一个接口,是高度抽象出来的集合,它包含了集合的基本操作:添加、删除、清空、遍历(读取)、是否为空、获取大小、是否保护某元素等等。
Collection接口的所有子类(直接子类和间接子类)都必须实现2种构造函数:不带参数的构造函数 和 参数为Collection的构造函数。带参数的构造函数,可以用来转换Collection的类型。
2、ArrayList
该容器是一个数组,实现了Collection和List接口,非线程安全,相应的操作就是对数组的操作。
3、HashSet
(1)、HashSet不能重复存储equals相同的数据 。原因就是equals相同,数据的散列码也就相同(hashCode必须和equals兼容)。大量相同的数据将存放在同一个散列单元所指向的链表中,造成严重的散列冲突,对查找效率是灾难性的。
(2)、HashSet的存储是无序的 ,没有前后关系,他并不是线性结构的集合。
(3)、hashCode必须和equals必须兼容, 这也是为了第1点。
(4)、采用的是HashMap变量中的key
4、LinkedList
(01) LinkedList 实际上是通过双向链表去实现的。它包含一个非常重要的内部类:Entry。Entry是双向链表节点所对应的数据结构,它包括的属性有:当前节点所包含的值,上一个节点,下一个节点。
(02) 从LinkedList的实现方式中可以发现,它不存在LinkedList容量不足的问题。
(03) LinkedList的克隆函数,即是将全部元素克隆到一个新的LinkedList对象中。
(04) LinkedList实现java.io.Serializable。当写入到输出流时,先写入“容量”,再依次写入“每一个节点保护的值”;当读出输入流时,先读取“容量”,再依次读取“每一个元素”。
(05) 由于LinkedList实现了Deque,而Deque接口定义了在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false,具体取决于操作)。
5、各种类型的Map
HashMap
HashMap与Map关系如下图:
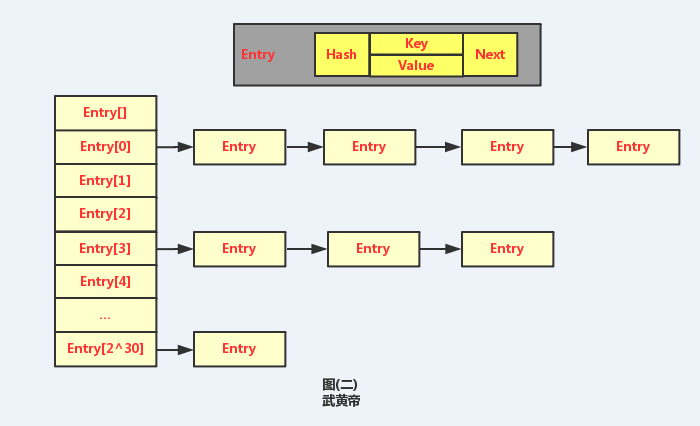

从图中可以看出:
(01) HashMap继承于AbstractMap类,实现了Map接口。Map是"key-value键值对"接口,AbstractMap实现了"键值对"的通用函数接口。
(02) HashMap是通过"拉链法"实现的哈希表。它包括几个重要的成员变量:table, size, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
size是HashMap的大小,它是HashMap保存的键值对的数量。
threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值="容量*加载因子",当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的。
TreeMap
内部采用的是红黑树详细请看


LinkedHashMap详细描述
(1)、能够保证插入元素的顺序。深入一点讲,有两种迭代元素的方式,一种是按照插入元素时的顺序迭代,比如,插入A,B,C,那么迭代也是A,B,C,另一种是按照访问顺序,比如,在迭代前,访问了B,那么迭代的顺序就是A,C,B,比如在迭代前,访问了B,接着又访问了A,那么迭代顺序为C,B,A,比如,在迭代前访问了B,接着又访问了B,然后在访问了A,迭代顺序还是C,B,A。要说明的意思就是不是近期访问的次数最多,就放最后面迭代,而是看迭代前被访问的时间长短决定。
(3)、内部存储的元素的模型。entry是下面这样的,相比HashMap,多了两个属性,一个before,一个after。next和after有时候会指向同一个entry,有时候next指向null,而after指向entry。这个具体后面分析。

(4)、linkedHashMap和HashMap在存储操作上是一样的,但是LinkedHashMap多的东西是会记住在此之前插入的元素,这些元素不一定是在一个桶中,画个图。
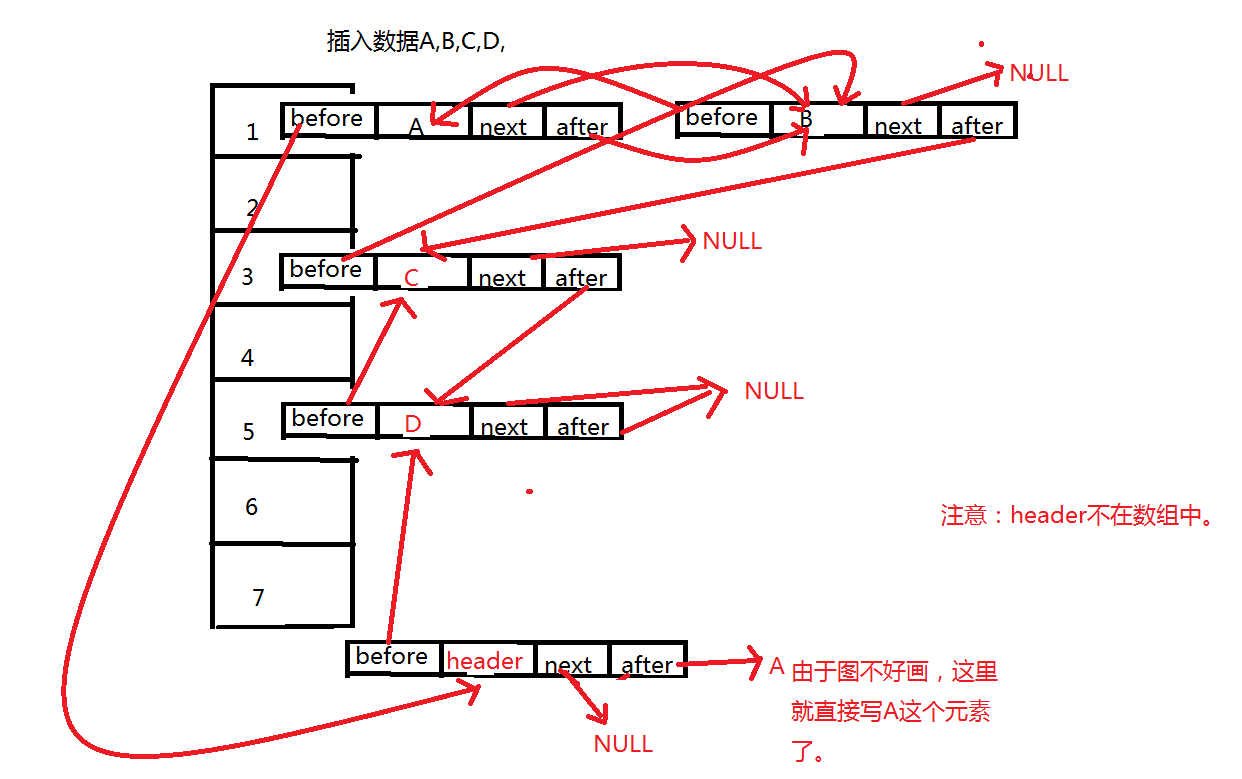
也就是说,对于linkedHashMap的基本操作还是和HashMap一样,在其上面加了两个属性,也就是为了记录前一个插入的元素和记录后一个插入的元素。也就是只要和hashmap一样进行操作之后把这两个属性的值设置好,就OK了。注意一点,会有一个header的实体,目的是为了记录第一个插入的元素是谁,在遍历的时候能够找到第一个元素。实际上存储的样子就像上面这个图一样,这里要分清楚哦。实际上的存储方式是和hashMap一样,但是同时增加了一个新的东西就是 双向循环链表。就是因为有了这个双向循环链表,LinkedHashMap才和HashMap不一样。
WeakHashMap
WeakHashMap 继承于AbstractMap,实现了Map接口。
和HashMap一样,WeakHashMap 也是一个散列表,它存储的内容也是键值对(key-value)映射,而且键和值都可以是null。
不过WeakHashMap的键是“弱键”。在 WeakHashMap 中,当某个键不再正常使用时,会被从WeakHashMap中被自动移除。更精确地说,对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。某个键被终止时,它对应的键值对也就从映射中有效地移除了。
这个“弱键”的原理呢?大致上就是,通过WeakReference和ReferenceQueue实现的。 WeakHashMap的key是“弱键”,即是WeakReference类型的;ReferenceQueue是一个队列,它会保存被GC回收的“弱键”。实现步骤是:
(01) 新建WeakHashMap,将“键值对”添加到WeakHashMap中。
实际上,WeakHashMap是通过数组table保存Entry(键值对);每一个Entry实际上是一个单向链表,即Entry是键值对链表。
(02) 当某“弱键”不再被其它对象引用,并被GC回收时。在GC回收该“弱键”时,这个“弱键”也同时会被添加到ReferenceQueue(queue)队列中。
(03) 当下一次我们需要操作WeakHashMap时,会先同步table和queue。table中保存了全部的键值对,而queue中保存被GC回收的键值对;同步它们,就是删除table中被GC回收的键值对。
这就是“弱键”如何被自动从WeakHashMap中删除的步骤了。
和HashMap一样,WeakHashMap是不同步的。可以使用 Collections.synchronizedMap 方法来构造同步的 WeakHashMap。
IdentityHashMap详见
在Java中,有一种key值可以重复的map,就是IdentityHashMap。在IdentityHashMap中,判断两个键值k1和 k2相等的条件是 k1 == k2 。在正常的Map 实现(如 HashMap)中,当且仅当满足下列条件时才认为两个键 k1 和 k2 相等:(k1==null ? k2==null : e1.equals(e2))。
IdentityHashMap类利用哈希表实现 Map 接口,比较键(和值)时使用引用相等性代替对象相等性。该类不是 通用 Map 实现!此类实现 Map 接口时,它有意违反 Map 的常规协定,该协定在比较对象时强制使用 equals 方法。此类设计仅用于其中需要引用相等性语义的罕见情况。