本人菜鸟一只,如果有什么说错的地方还请大家批评指出!!
这篇文章用来整理下gp的一些东西,不是概念搭建七七八八的东西,就是单纯的一些sql和使用。
1、gp是分布式的数据库,跟hadoop有点类似,也是有master和slave的架构关系
摘抄作者的话:Greenplum所有的并行任务都是在Segment数据节点上完成后,Master只负责生成和优化查询计划、派发任务、协调数据节点进行并行计算,Master上的资源消耗很少有超过20%情况发生,因为Segment才是计算和加载发生的场所(当然,在HA方面,Greenplum提供Standby Master机制进行保证)。
缺陷:他和hadoop一样不支持多并发,也就是说sql不多的时候,执行速度会很快,但是如果有多个sql一起运行,就会奇慢无比!
2、索引和压缩:
索引:GreenPlum是有索引的(但是实际上,我并没有多GP的索引有多少的测试),大概如下:
-1.如果是从超大结果集合中返回非常小的结果集(不超过5%),建议使用BTREE索引(非典型数据仓库操作)
-2.表记录的存储顺序最好与索引一致,可以进一步减少IO(好的index cluster)
-3.where条件中的列用or的方式进行join,可以考虑使用索引
-4.键值大量重复时,比较适合使用bitmap索引
压缩:其实压缩也是为了加快查询速度,概念如下:
-1.不需要对表进行更新和删除操作
-2.访问表的时候基本上是全表扫描,不需要建立索引
-3.不能经常对表添加字段或者修改字段类型
实际测试:
CREATE TABLE "数据库"."表" (
"字段1" varchar(20),
"字段2" int4,
"字段3" int8,
"字段4" numeric,
....
)
WITH (APPENDONLY=true, COMPRESSLEVEL=1, ORIENTATION=column, COMPRESSTYPE=rle_type)
DISTRIBUTED randomly;在我们的集群环境下,如下创建一张排名表,性能会比创建索引好很多(查询8s优化到1.5s),原因是因为服务器上磁盘IO经常跑满,但是cpu挺空闲的,所以把压力推到cpu让它去压缩和解压缩,缓解磁盘io的压力
3、分布键
个人觉得分布键是一个挺重要的东西,因为分布不均匀就会导致实现不了并行,从而影响查询的速度。
CREATE TABLE "数据库"."表" (
"字段1" varchar(50),
"字段2" varchar(500),
"字段3" varchar(500),
....
"时间" timestamp(6) DEFAULT now()
)
distributed by(字段1,字段2)
;
-1.distributed by(字段1, 字段2)
括号里面可以是一个字段,也可以是多个字段,一般来说都是通过用户id,设备mac,这种很随机的值来给定分布键。
如果在建表的时候不给定分布键,那么分布键就会是这张表的主键,或者是第一个字段。
也可以给定随机分布,把distributed by(字段1, 字段2)替换成DISTRIBUTED randomly
-2.修改分布键:alter table "数据库"."表名" set distributed randomly;
-3.查看分布情况:
select gp_segment_id,count(*) from "数据库"."表名" group by gp_segment_id;-4.举个例子,如果你设置一个分布键叫做flag,然后这个字段只有两个值0和1,你有一个20台机器组成的GreenPlum,那这张表只会分布到两台机器上,在计算的时候,也只会动用这两台机器运算能力,其他18台在围观,所以分布键要合理分配!
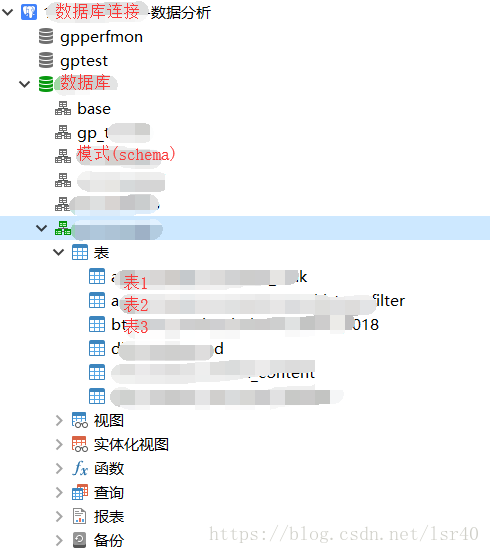
4、层级关系
-1.数据库连接
-2.创建数据库
-3.创建模式(也叫schema)
-4.创建表
所以它多了一层叫做模式的东西,如下图:
5、关于sql
-1.窗口函数很好用!
row_number() over(partition by XXX order by XXX desc)
max() over(partition by XXX order by XXX)
avg() over(partition by XXX order by XXX)
....
-2.行列互转
--列转行(GP)
SELECT uid,String_agg(DISTINCT tag) as tag FROM (SELECT uid,tag FROM 数据库.表
WHERE create_time BETWEEN '20180601' AND '20180701') tagtb GROUP BY uid;
--列转行(pg postgresql)
SELECT string_agg(name,',') from test;
--行转列(pg postgresql)
SELECT regexp_split_to_table(name,',') from test;
--行转列的去重(实际运用)
SELECT * FROM (SELECT
regexp_split_to_table(tag_name,',') as tag
FROM
表A )tb
WHERE
tag IS NOT NULL
GROUP BY
tag
ORDER BY
1 ASC;
使用的时候注意下,不同的sql行列互转的函数传参甚至名称可能不太一样,然后如果把列转成行最好要有个分隔符,方便后面的分词查询!
-3.update(b表计算出的某一个字段设置的想要更新字段的表中,通过uid来关联)
update 数据库.想要更新字段的表 tb set 想要更新的字段=b.另一张表的相同字段
from (SELECT uid,String_agg(DISTINCT tag) as tag
FROM (SELECT uid,tag FROM 数据库.另一张表 WHERE 条件) tagtb
GROUP BY uid) b
where tb.uid=b.uid;
--1、更新表中前10条数据(更新为固定值):
update BranchAccount
set AccountNumber = '10010'
from (select top 10 *from BranchAccountorder by ID)as t1
where BranchAccount.ID = t1.ID
--2、用一个表的字段值更新另一个表的某字段值:
update BranchAccount
set BranchAccount.AccountNumber = t1.AccountNumber
from TEMPBranchAccount as t1
where BranchAccount.ID = t1.ID
--3、更新表前10条数据(更新为另一个表的数据):
update BranchAccount
set BranchAccount.AccountNumber = t1.AccountNumber
from (select top 10 *from TEMPBranchAccount)as t1
where BranchAccount.ID = t1.ID
暂时写到这吧,感觉还没写完,如果以后想到什么再加进来吧,或者大家如果有什么想问的,可以给我留言!希望我能够帮上忙~
============================================================================
补充一:
记录几个关于日期的处理sql
--注:gmt_modified 这个字段是 default now()
--求当前5天的数据
select * from 库名.表明 WHERE gmt_modified >= (SELECT now() - interval '5 D')
--第二段是这样的,表A和表C中对应天的数据计算结束之后,并且确定表B中没有计算当天的数据之后,就返回要计算的日期,主要想说的是可以通过这种方式给定日期的范围to_char((SELECT now() - interval '5 D'),'yyyyMMdd') ,date_id是int类型
select *from (
select rc.date_id::VARCHAR as date_id,'${date_type}' as date_type from (
select date_id,status_flag from 表A where date_id>='${date_id}' and status_flag='Completed' ORDER BY date_id desc
limit 9999 ) rc
where not EXISTS (select date_id from 表B b where rc.date_id=b.date_id and rc.status_flag=b.status_flag)
and EXISTS (select date_id from 表C b where rc.date_id=b.date_id)
) tb
where tb.date_id <=(to_char((SELECT now() - interval '5 D'),'yyyyMMdd'))
ORDER BY date_id;
--第三段是求数据库中的最新日期的前几天
select count(1),gmt_modified,next_gmt_modified from (
select to_char(freshtime,'yyyyMMdd') as gmt_modified,(to_char(((select max(freshtime) from 表A) - interval '3 D'),'yyyyMMdd')) as next_gmt_modified from 表A
where freshtime is not null
) tb
where gmt_modified >= next_gmt_modified
GROUP BY gmt_modified,next_gmt_modified ORDER BY 2 desc;
--但是第三段有个缺点,缺点是gmt_modified更新时间一般来说不会做索引什么的,如果要求这个字段的最大值,很有可能查询速度奇慢无比,因此就需要用到其他方式来解决这个问题
--例如,如果该表有自增的主键id,那么我只要拿到id最大的那条数据的更新时间,就是最新的时间,而且实际运行,第三段sql在数据多的情况下,需要查询半小时。。。但是如下sql只需要不到1秒钟!!
select * from 表A where
freshtime >=
(
select next_gmt_modified::TIMESTAMP from (
select to_char(freshtime,'yyyyMMdd'),to_char((freshtime - interval '3 D'),'yyyyMMdd') as next_gmt_modified from 表A where 主键 in (select max(主键)from 表A )
) tb ) 补充二:
pg上的相关的元数据sql
--查询表占用空间大小
select pg_size_pretty(pg_relation_size('表名'));
--查询某张表,在某个schema上是否存在
select * from pg_class where relname='表名'::name and relkind='r' ) a INNER JOIN
pg_namespace b on a.relnamespace = b.oid
WHERE nspname = 'schema名'
--杀掉某个sql
select pg_terminate_backend(传入sqlid);
--查询当前正在执行的sql情况(可做成视图)
SELECT (( 'select pg_cancel_backend(' :: TEXT || pg_stat_activity.procpid ) || ');' :: TEXT
),
( now() - pg_stat_activity.query_start ) AS cost_time,
pg_stat_activity.datid,
pg_stat_activity.datname,
pg_stat_activity.procpid,
pg_stat_activity.sess_id,
pg_stat_activity.usesysid,
pg_stat_activity.usename,
pg_stat_activity.current_query,
pg_stat_activity.waiting,
pg_stat_activity.query_start,
pg_stat_activity.backend_start,
pg_stat_activity.client_addr,
pg_stat_activity.client_port,
pg_stat_activity.application_name,
pg_stat_activity.xact_start,
pg_stat_activity.waiting_reason,
pg_stat_activity.rsgid,
pg_stat_activity.rsgname,
pg_stat_activity.rsgqueueduration
FROM
pg_stat_activity
WHERE
(
pg_stat_activity.current_query <> ALL ( ARRAY [ '<IDLE>' :: TEXT, '<insufficient privilege>' :: TEXT ] ))
ORDER BY
( now() - pg_stat_activity.query_start ) DESC推荐的博客:https://blog.csdn.net/u010256965/article/details/50515954(关于gp的数值处理函数,作者:u010256965)