前言:
数据倾斜,一个在大数据处理中很常见的名词,经由前人总结,现已有不少数据倾斜的解决方案(而且会发现大数据的不同框架的数据倾斜解决思想是一致的,只是实现方法不同),本文重点记录这次遇到spark处理数据中的倾斜问题。
老话:
菜鸡一只,本人会对文中的结论负责,如果有说错的,还请各位批评指出!
起因:
事情是这样的:有一批数据在hive的表中(我们称它为表A,表A中有不同网站的域名),要对这批数据进行处理。有一张非常小的表(表B,这张表中有我们想关注的域名,而且域名并不唯一,意思就是:同一个域名可能会有多次操作),我相信说到这,大家已经有点蒙了,画个图举个例子!

经过:
以下是我的心路历程:
提一句为了增加shuffle的并行,我设置了1000的并行度.config("spark.sql.shuffle.partitions","1000")
1、直接join!不做其他的任何处理
结果:效果非常美!我没截图,大概情况是1000个task中有900多个贼快,就剩下20--30个左右,十分的慢,然后
ExecutorLostFailure (executor 65 exited caused by one of the running tasks)
Reason: Container marked as failed:
container_e61_1520995248034_27835_01_000066 on host: XXX(这里是主机名,我使用XXX代替). Exit status: 137.
Diagnostics: Container killed on request. Exit code is 137
Container exited with a non-zero exit code 137
Killed by external signal还有这种:
java.lang.OutOfMemoryError: Java heap spaceand:
ExecutorLostFailure (executor 147 exited caused by one of the running tasks)
Reason: Container marked as failed: container_e61_1520995248034_26149_01_000181 on host: XXX. Exit status: 1.
Diagnostics: Exception from container-launch.
Container id: container_e61_1520995248034_26149_01_000181
Exit code: 1
Stack trace: ExitCodeException exitCode=1:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:601)
at org.apache.hadoop.util.Shell.run(Shell.java:504)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:786)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:213)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Container exited with a non-zero exit code 1还有:
Container exited with a non-zero exit code 1
Current usage: 8.1 GB of 10 GB physical memory used;
9.9 GB of 10 GB virtual memory used. Killing container。
---嗯,大概类似这种,具体数字是多少我记不清了,反正就是超出yarn对于container的内存控制,然后被yarnkill了就上面这个错,我要吐槽下,网上很多人说:
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value></property>
关闭yarn的内存检查,这。。。显然是逃避问题,这样就有可能导致异常的container一直吃内存,吃到yarn上没有资源,如果是自己搭个玩玩的集群,修改这个参数,还行,但是如果是服务器,有点异想天开了。
总之就是一大堆乱七八糟的内存报错,程序根本运行不完,然后挂了!
解决内存问题:
-1.以上的问题,几乎都是内存不够,因此我首先考虑的是内存!
增加申请到的executor的内存
--executor-memory 10G
--conf spark.yarn.executor.memoryOverHead=2048
然后我发现,完全不可能解决这个问题,该报错还是报错
-2.调整executor的内存分配
因为我没有任何的cache,所以完全没必要保留内存空间给cache数据,应该让大部分内存都来支持shuffle操作
.config("spark.memory.storageFraction","0.2")
.config("spark.memory.fraction","0.8")
以上两个参数的含义我就不在这里赘言了,大家自行百度脑补
-3.总结:
在我各种设置内存大小和占比之后,代码确实是从不能运行到能够运行,但是事实上我发现有的分区才几M的数据,有的分区居然有50G+(该阶段总的流入数据是160G左右,1000个task)的数据流入并处理,该task内存中存不下,还溢写到磁盘9G+,然而大部分task在2分钟内都能运行完,唯独有几个task需要10分钟,甚至更多,因此当数据倾斜严重的时候,一味的调整内存,最多你只能让你的代码运行起来,但是性能还不如直接使用hive跑来得快。
去掉shuffle过程:
这个也很好理解,因为数据倾斜发生在shuffle阶段(对应到该问题就是join阶段),如果不调用join这个api那就直接避免了数据倾斜的问题。
-1.之前遇到过的场景是表A是域名,表B中是想要看到的域名(而且域名都是唯一的),因此我直接读取表B,将表B做成广播变量,然后在map表A的时候,保留我想看到的域名
//加载表B成为广播变量
List<String> domains = spark.table("hive库名.hive表B").map(new MapFunction<Row, String>() {
public String call(Row value) throws Exception {
//value.getString(1)是唯一的字符串类型的id,value.getString(0)这个是域名也是唯一的
return value.getString(1)+"_"+value.getString(0);
}
},Encoders.STRING()).collectAsList();
HashMap<String,List<String>> map = new HashMap<String,List<String>>();
//将刚刚的list做成map,key是id,value是一个list,list里面放了id相同的域名
for (String domain:domains ) {
String[] str = domain.split("_");
if(map.get(str[0])==null){
List list = new ArrayList();
list.add(str[1]);
map.put(str[0],list);
}else{
map.get(str[0]).add(str[1]);
}
}
//这一步是将HashMap这个每个executor都要使用到的对象,做成广播变量,减少内存的使用
ClassTag<HashMap<String,List<String>>> tag = (ClassTag) scala.reflect.ClassTag$.MODULE$.apply(HashMap.class);
final Broadcast<HashMap<String,List<String>>> bsmap = spark.sparkContext().broadcast(map,tag);
//遍历表A,保留有用的数据
Dataset<Row> 表A = spark.table("hive库名.hive表A")
.map(new MapFunction<Row, 表Adomain>() {
public 表Adomain call(Row value) throws Exception {
表Adomain A = new 表Adomain();
A.setXXX(value.getString(0));
A.setXXX(value.getString(1));
A.setXXX(value.getString(2));
...
return A;
}
},Encoders.bean(表Adomain.class)).filter(new FilterFunction<表Adomain>() {
public boolean call(表Adomain value) throws Exception {
//在这里判断该条数据的域名是否存在于广播变量表B的map中
//如果存在就保留该数据,否则就去掉
boolean flag = false;
String 域名 = value.getXXX();
String id = value.getXXX();
List<String> list = bsmap.value().get(id);
if(list == null){
return flag;
}else{
for(String str:list){
if(域名.equals(str)){
flag=true;
}
}
}
return flag;
}如上代码,其实也实现了如下这样的sql,并且没有触发shuffle阶段,亲测效果very gooooood!
select 字段X,字段XX...
from 表A inner join 表B
on 表A.id=表B.id and 表A.域名=表B.域名;缺点:这种方法在我现在的场景中用不了,如图1所示,我的表B域名并不唯一,有可能导致表A的一条数据变成多条,所以并不是简单的过滤(我觉得就是一定要join,把数据笛卡尔积然后再通过on字段去掉不符合的数据,这样才能增加表A的数据)!所以这种方法虽然好用,但是在当前的场景下用不了
数据散列:
-1.其实就是相同域名的数据分到了同一个task中,然后有部分的域名数据量大的变态
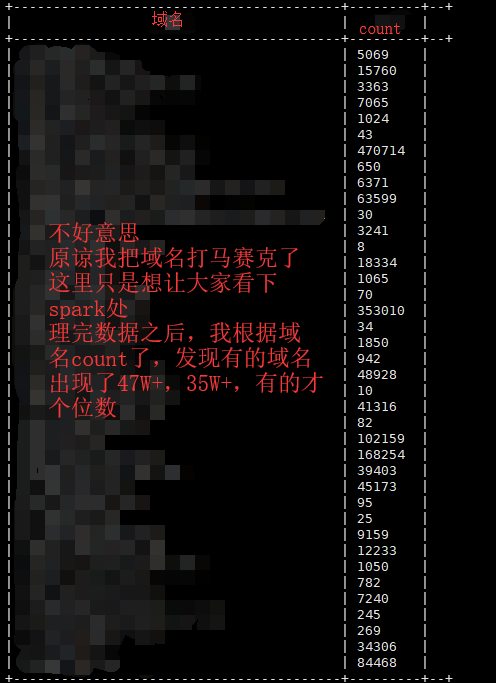
-2.处理方式(总体来说就是让相同域名的数据到不同的task上处理):
第一种:如果数据倾斜的域名较少,可以接着把这些域名filter出来,然后将正常的数据join,将异常的数据的域名加上一个随机值,例如:将表A的域名A---->域名A_1,域名A_2,将表B的数据扩容(就是一条数据扩容成10条甚至100条,确保表A的域名能和B表join)这样这两个域名就会在不同的task中聚合,然后聚合完在去掉拼接上的随机值即可
第二种:如果不确定数据倾斜的域名是哪些,可以先抽样count,然后order by count再top5或者top10等,这样就知道异常的是哪些了(但是这样的代码写起来还是比较麻烦的。。。)
第三种:比较暴力的方式,不管哪些正常哪些异常,直接表A的域名直接拼接上随机值,然后表B数据扩容(注意:是扩容,就是比如原来有10条数据,扩容10倍,就要变成100条数据),然后join,随机值可以先从10开始尝试慢慢增大(因为我表B的数据非常小,如果我扩容100倍,30K数据最多也就几M,而且我倾斜比较严重,所以我采用100倍)
上面的处理方式,思想上是一样的,只是处理的步骤有细微的区别使用哪种方法具体还要测试性能,但是第三种是比较简单通用的方法(代码量比较少,效果也差不多,通用,我就采用这种方式)
画图演示下:

这样就可以确保表A的每一条被打上随机值的数据都能在表B中找到对应的域名join上,就不会数据丢失了。
代码如下:
//把这张表的数据扩容10倍,等待接下来的join
Dataset<表Bdomain> tb2 = spark.sql("我是一条查询表B具体数据的sql")
//使用map打随机值,使用flatmap才能扩容,所以这里用flatmap
.flatMap(new FlatMapFunction<Row, 表Bdomain>() {
public Iterator<表Bdomain> call(Row row) throws Exception {
List<表Bdomain> list = new ArrayList<表Bdomain>();
//获得域名等参数
String 域名 = row.getString(0);
//...等参数
for (int i =1;i<=100;i++){
表Bdomain dominfo = new 表Bdomain(dm1+"_"+i,参数1,参数2);
list.add(dominfo);
}
return list.iterator();
}
},Encoders.bean(表Bdomain.class));
Dataset<表Adomain> tb1 = spark.sql("我是一条查询表A的sql")
.map(new MapFunction<Row, 表Adomain>() {
public 表Adomain call(Row value) throws Exception {
Random r = new Random();
//随机出1--100的数字
int num = r.nextInt(100)+1;
String 域名 = value.getString(0)+"_"+num;
//...设置相关参数
表Adomain esdmb = new 表Adomain(域名,参数1,参数2,参数3);
return esdmb;
}
},Encoders.bean(表Adomain.class));
Dataset<join结果domain> tmp = tb1.join(tb2,tb1.col("域名").equalTo(tb2.col("域名")))
//这里多做一次select,规范字段顺序,方便后面查询
.select("这里是字段1","字段2","字段3",.....)
.map(new MapFunction<Row, join结果domain>() {
public join结果domain call(Row value) throws Exception {
String 参数1, = value.getString(0);
String 参数2 = value.getString(1);
//去掉域名后面的随机数
String 域名 = value.getString(2).split("_")[0];
//.....
join结果domain sdmba = new join结果domain(参数1,参数2,参数3,...);
return sdmba;
}
},Encoders.bean(join结果domain.class));
//可以注册成一张临时视图(老版本叫临时表,其实一个意思)
tmp.createOrReplaceTempView("tmp");结论:
最后测试结果,调试内存后join过程在15分钟左右,采用散列过后情况得到非常大的改善,见下图:
只需要2.9min,因此遇到数据倾斜首先要知道是哪个阶段出了问题,不能一味的盯着某一个参数调优(比如单独调整内存),应该尝试从更多的角度全局的去思考问题。

顺带一提:
在解决此次问题中看了不少文章,在此记录下:
1、(岑玉海)https://www.cnblogs.com/cenyuhai/
看了他的(这篇也是其他人转载的)博客后,深表敬佩:https://blog.csdn.net/heyc861221/article/details/80122943
2、(ICE-Martina写的spark数据倾斜,非常的精辟和完整)https://blog.csdn.net/lw_ghy/article/details/51419877