版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012790503/article/details/82874731
一张图解释字符集
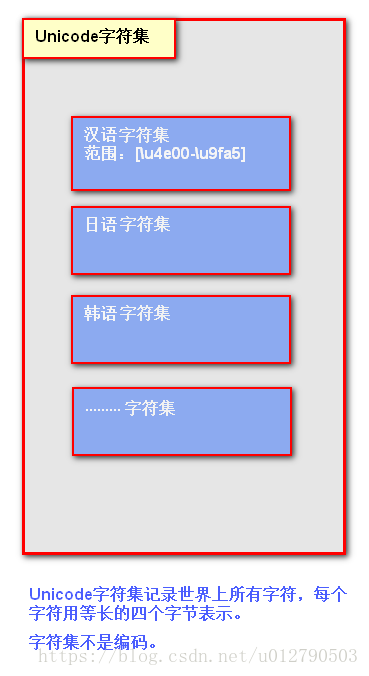
举例说明什么是编码:
UTF-8编码
等长编码对于英文来说浪费空间,所以出现了变长编码UTF系列,如UTF8,UTF16,UTF32。
UTF8的编码对象是整个Unicode字符集,所以可以表示所有国家的语言而不会乱码,所以叫“万国码”。所以网络传输文本一般使用UTF-8编码,如网页,这样可以在不同的电脑上看到相同的文本而不乱码。
GB2312编码
但是UTF8还是对于英文来说,还是单个字节,但是对于其他语言编码还是多个字节,占用空间仍然较大。
如果只针对中文进行编码,被编码文字只有几万字,那么会节省很多空间。常用的简体中文编码有GBK/GB2312,GB表示国家标准。虽然节省的存储空间,但是前提是需要知道文本的语言是什么。所以只在中文环境下使用。
- 完