树
树形结构是一种层级式的数据结构,由节点和连接它们的边组成, java语言编写的程序中常常用引用来表示边。根是树中顶端的节 点:它没有父节点。节点表示保存在树中的数据对象。非平衡树是 指根左边的后代比右边多,或者相反。 区分树和图的主要特征是树中不存在环路。
树的节点 Root,parent,child,leaf,sibling 。
树的主要类型 N元树 平衡树 二叉树 二叉搜索树 AVL树 红黑树 2-3树(多叉树比二叉树有更多的关键字和子节点)。
树通常结合了有序数组和链表两种数据结构的优点,在树中查找数 据项的速度和在有序数组中查找一样快,并且插入数据项和删除数 据项的速度也和链表一样。 其中,二叉树和二叉搜索树是常用的树。二叉树指树中每个节点 多只能有两个子节点,二叉搜索树指一个节点的左子节点的关键 字值小于这个节点,右子节点的关键字的值大于或等于这个父节 点。 查找节点需要比较要找的关键字值和节点的关键字值,插入需要找 到要插入新节点的位置并改变他父节点的子字段来指向它。如果一 个节点没有子节点,删除它只要把它的父节点的子字段置为null即 可,如果一个节点有一个子节点,把它父节点的子字段置为它的子 节点就可以删除它,如果一个节点有两个子节点,删除它要用他的 后继(该节点的右子节点为根的子树中关键值小的那个节点)来 代替他。可以用数组表示树,不过基于引用的方法更常用。
二叉树的效率:
树的大部分操作都需要从上到下一层一层的查找某个节点,因此常 见树的操作(查找,插入,删除)时间复杂度大约是O(logN),如 果树不满,分析起来很困难,不过,可以认为对给定层数的树,不 满的树的平均查找时间比满树要短,因为在它的较低的层上完成查 找的次数要比满树时少。 树对所有常用的数据存储操作都有很高的效率,遍历不如其他操作 快,但是,遍历在大型数据库中不是常用的操作。
B树是多叉树,每个节点可以有几十或上百个关键字和节点,B树中 子节点的个数总是比关键字的个数多1,为达到好的性能,B树通 常在一个节点中保存一块的数据。
实战
在控制台上输入一组数据,按照输入数据的格式来构造一棵二叉树,并打印出二叉树的高度。
输入的数据格式如下:
12
2 3
2 11
3 4
3 5
11 12
11 13
4 6
5 7
12 14
12 15
14 16
16 17
用二叉树表示如下:
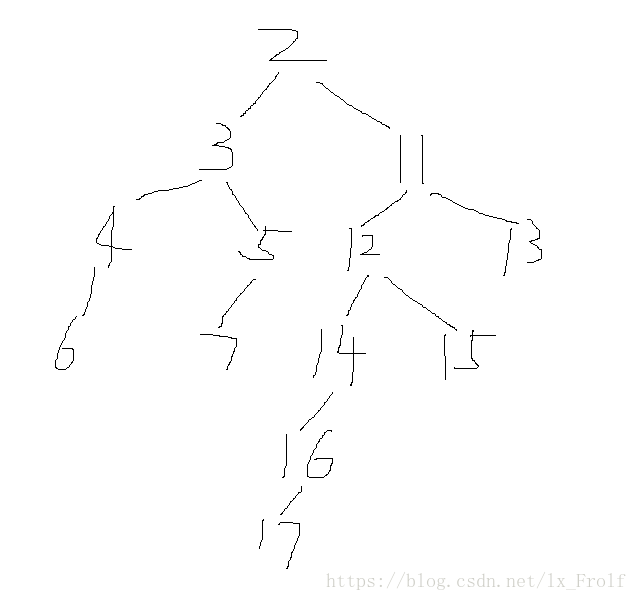
Java代码实现如下:
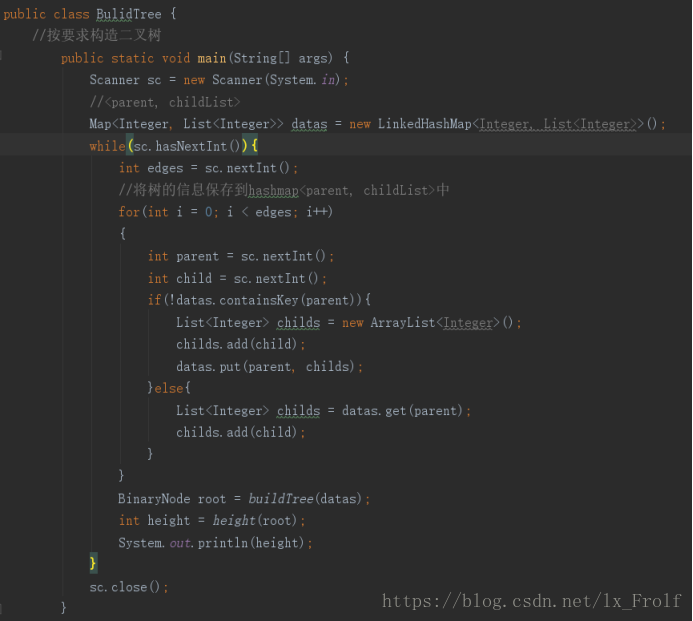

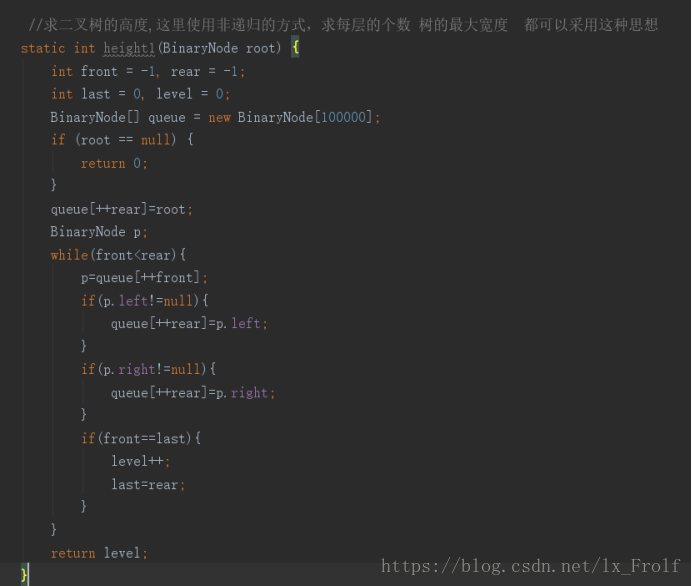
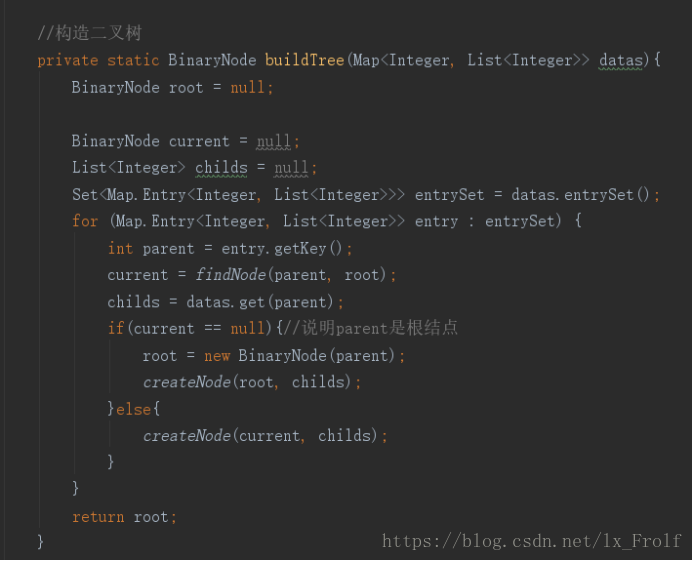
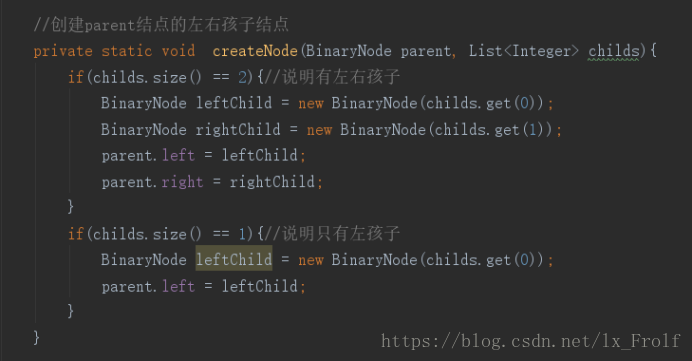
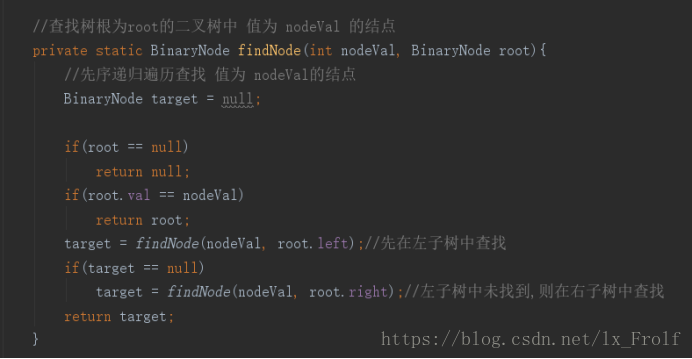

输出结果为:
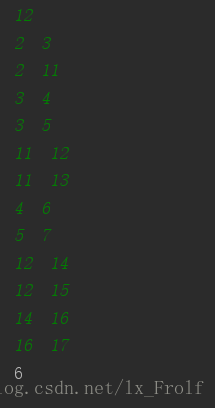

红黑树
普通的二叉搜索树可以快速的找到一个给定关键字的数据项,可以快速的插入和删除数据,如果二叉搜索树中插入的是随机数据,执行效果很好,但是如果插入的是有序的数据或逆序的数据,速度就会变得特别慢,因为插入的数值有序时,二叉树就是非平衡的了,而对于非平衡树,它的快速查找,插入,删除,指定数据项的能力就丧失了。红黑树是增加了某些特点(在红黑平衡的方法中,每个节点都有一个新的特征:它的颜色不是红的就是黑的)的二叉搜索树,它将解决这个问题。
效率:
在红黑树中的查找时间和在普通二叉树中的查找时间几乎完全一样,因为在查找的过程中并没有应用红黑树的特征,额外的开销只是每一个节点的存储空间都稍微增加了一点来存储红黑的颜色(一个boolean变量)。插入和删除的时间要增加一个常数因子,因为不得不在下行的路径上和插入点执行颜色变换和旋转。平均起来,一次插入大约需要一次旋转,但是比在普通的二叉搜索树中要慢。因为在大多数应用中,查找的次数比插入和删除的次数多,所以应用红黑树取代普通的二叉搜索树总体上不会增加太多的时间开销,红黑树的优点是对有些数据的操作不会慢到O(N)的时间复杂度。
总结:保持普通二叉树的平衡是非常重要的,这样可以使找到给定节点必需的时间尽可能短,在二叉树中加入红黑平衡对平均执行效率只有很小的负面影响,却避免了对有序的数据操作的最坏的性能。