背景信息
IRIS数据集是机器学习入门中最常用的数据集之一,但PaddlePaddle官方文档中并没有给出对该数据集分类的示例,因此本文进行了尝试,并通过两层全连接网络最终实现了该数据集的分类。
数据集说明
下载的数据集中类别标签是字符串,为方便使用将其替换为0、1、2,如下所示,前四列为特征值,最后一列为标签:
4.6,3.2,1.4,0.2,0 5.3,3.7,1.5,0.2,0 5.0,3.3,1.4,0.2,0 7.0,3.2,4.7,1.4,1 6.4,3.2,4.5,1.5,1 6.9,3.1,4.9,1.5,1 5.5,2.3,4.0,1.3,1
整理流程
实现的代码包括如下几个部分
- iris数据文件读取并切分为训练集和测试集两部分。
- 从训练集和测试集中分布提取标签和特征。
- 实现PaddlePaddle使用的reader函数。
- 定义模型并进行训练。
- 进行预测
详细代码
# 引入所需包 import paddle.v2 as paddle import numpy as np import random
#读取数据函数,输入为数据文件名和训练、测试切分比率,返回为list类型的训练数据集和测试数据集
def loadData(fileName,ratio):
trainingData=[]
testData=[]
with open(fileName) as txtData:
lines=txtData.readlines()
for line in lines:
lineData=line.strip().split(',') #去除空白和逗号“,”
if random.random()<ratio: #数据集分割比例
trainingData.append(lineData) #训练数据集列表
else:
testData.append(lineData) #测试数据集列表
return trainingData,testData
#输入为list类型数据,分割为特征和标签两部分,返回为np.narray类型的特征数组和标签数组
def splitData(dataSet):
character=[]
label=[]
for i in range(len(dataSet)):
character.append([float(tk) for tk in dataSet[i][:-1]])
label.append(dataSet[i][-1])
return np.array(character),np.array(label)
# 读取数据数组和标签数组,并将二者组合为PaddlePaddle中使用的reader
def paddle_reader(dataCharacter,dataLabel):
def reader():
for i in xrange(len(dataLabel)):
yield dataCharacter[i,:], int(dataLabel[i])
return reader
# 进行数据预处理工作 iris_file='/book/iris012.data' ratio=0.7 trainingData, testData=loadData(iris_file,ratio) ##加载文件,按一定比率切分为训练样本和测试样本 #a1=random.shuffle(trainingData) trainingCharacter,trainingLabel=splitData(trainingData) #将训练样本切分为数据和标签两个数组 testCharacter,testLabel=splitData(testData) #将测试样本切分为数据和标签两个数组
# 实现reader train_reader=paddle_reader(trainingCharacter,trainingLabel) test_reader=paddle_reader(testCharacter,testLabel)---------------------------------下面为模型定义以及训练过程------------------------
# 该模型运行在单个CPU上
paddle.init(use_gpu=False, trainer_count=1)
features = paddle.layer.data(
name='features', type=paddle.data_type.dense_vector(4))
label = paddle.layer.data(
name='label', type=paddle.data_type.integer_value(3))
# 使用两侧全连接网络
fc1 = paddle.layer.fc(input=features, size=10, act=paddle.activation.Linear())
predict = paddle.layer.fc(input=fc1, size=3,act=paddle.activation.Softmax())
cost = paddle.layer.classification_cost(input=predict, label=label)
parameters = paddle.parameters.create(cost)
optimizer = paddle.optimizer.Momentum(momentum=0)
trainer = paddle.trainer.SGD(cost=cost,
parameters=parameters,
update_equation=optimizer)
#feeding={'features': 0, 'label': 1}
from paddle.v2.plot import Ploter
train_title = "Train cost"
test_title = "Test cost"
cost_ploter = Ploter(train_title, test_title)
step = 0
# event_handler to plot a figure
def event_handler_plot(event):
global step
if isinstance(event, paddle.event.EndIteration):
if step % 10 == 0:
cost_ploter.append(train_title, step, event.cost)
cost_ploter.plot()
step += 1
if isinstance(event, paddle.event.EndPass):
# save parameters
with open('params_pass_%d.tar' % event.pass_id, 'w') as f:
trainer.save_parameter_to_tar(f)
result = trainer.test(reader=paddle.batch(
test_reader, batch_size=10))
cost_ploter.append(test_title, step, result.cost)
lists = []
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if event.batch_id % 10 == 0:
print "Pass %d, Batch %d, Cost %f, %s" % (
event.pass_id, event.batch_id, event.cost, event.metrics)
if isinstance(event, paddle.event.EndPass):
# save parameters
with open('params_pass_%d.tar' % event.pass_id, 'w') as f:
trainer.save_parameter_to_tar(f)
result = trainer.test(reader=paddle.batch(
test_reader, batch_size=10))
print "Test with Pass %d, Cost %f, %s\n" % (
event.pass_id, result.cost, result.metrics)
lists.append((event.pass_id, result.cost,
result.metrics['classification_error_evaluator']))
trainer.train(
reader=paddle.batch(
paddle.reader.shuffle(
train_reader, buf_size=100),
batch_size=10),
#feeding=feeding,
event_handler=event_handler_plot,
num_passes=50)
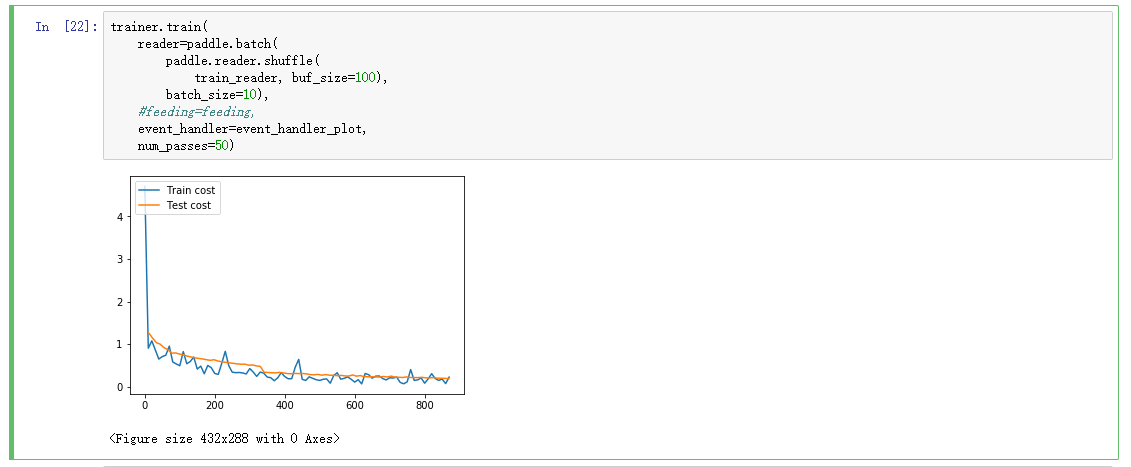
---------------------------------下面为模型验证过程------------------------
# 准备测试数据
test_data_creator = test_reader()
test_data = []
test_label = []
for item in test_data_creator:
test_data.append((item[0],))
test_label.append(item[1])
if len(test_data) == 100:
break
#进行预测
probs = paddle.infer(
output_layer=predict, parameters=parameters, input=test_data)
for i in xrange(len(probs)):
print "label=" + str(test_label[i]) + ", predict=" + str(np.argsort(-probs)[i][0])
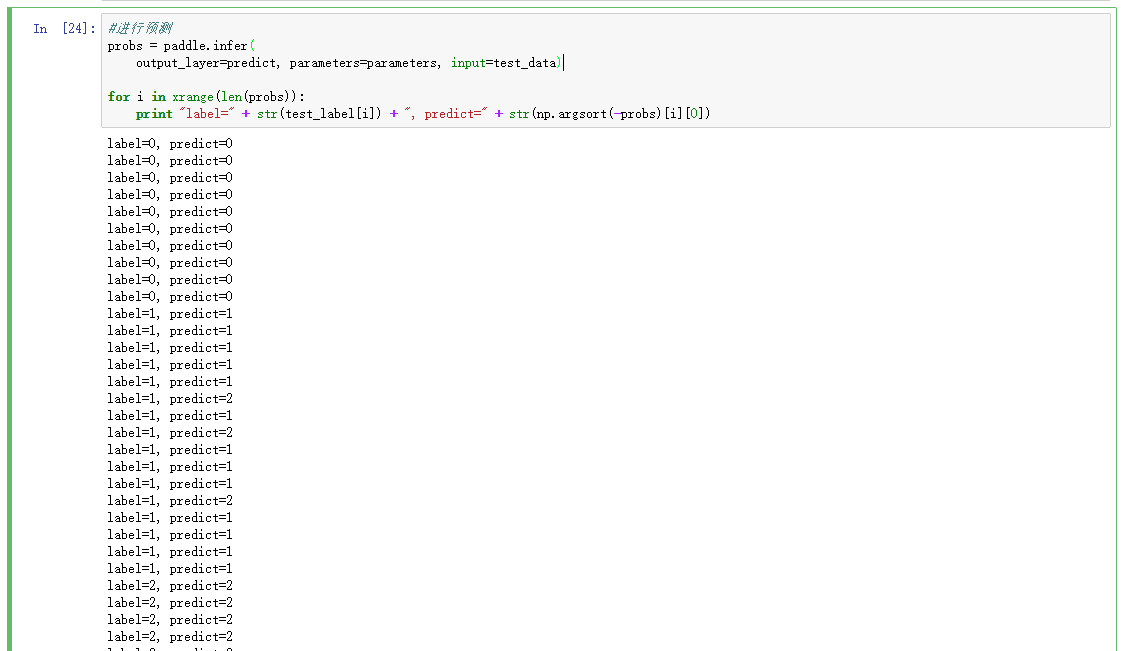
可以看出,有部分值预测错误,主要原因是Iris数据集比较小的缘故,可以通过增加训练轮数来改善,比如将轮数增加到300,将会得到非常好的预测效果。