版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/EverestRs/article/details/84181728
对销售数据进行分析:
读入数据
> mydata<-read.csv(file.choose())
> head(mydata)
Channel Region Fresh Milk Grocery Frozen Detergents_Paper Delicassen
1 2 3 12669 9656 7561 214 2674 1338
2 2 3 7057 9810 9568 1762 3293 1776
3 2 3 6353 8808 7684 2405 3516 7844
4 1 3 13265 1196 4221 6404 507 1788
5 2 3 22615 5410 7198 3915 1777 5185
6 2 3 9413 8259 5126 666 1795 1451
第一列数据并不需要,除去
> mydata<-mydata[,-1]
将数据进行标准化处理
> mydata1<-scale(mydata)
求欧氏距离
> mydist<-dist(mydatas,method="euclidean")
进行层次聚类
> mycluster<-hclust(mydist)
> mycluster
Call:
hclust(d = mydist)
Cluster method : complete
Distance : euclidean
Number of objects: 440
> plot(mycluster)
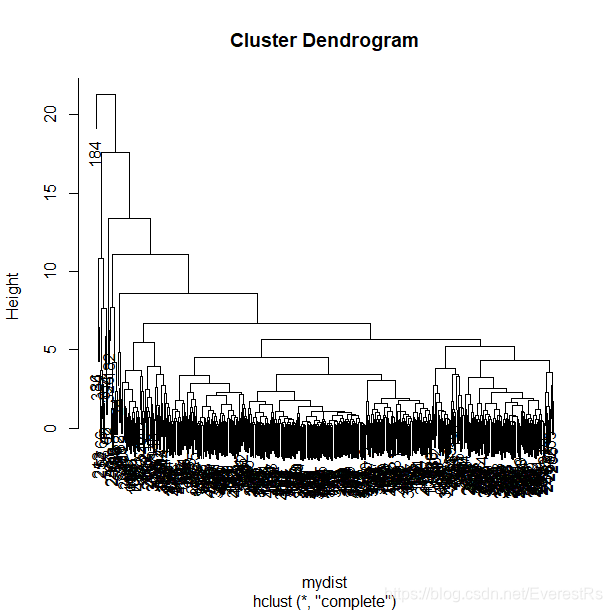
注:hclust()函数:层次聚类法分析
hclust(d, method = "complete", members = NULL)
#d为距离矩阵。
method表示类的合并方法:
single 最短距离法
complete 最长距离法
median 中间距离法
mcquitty 相似法
average 类平均法
centroid 重心法
ward 离差平方和法