1. kafka是什么?使用场景?
kafka是一个高吞吐的分布式消息队列系统。特点是生产者消费者模式,先进先出(FIFO)保证顺序,自己不丢数据,默认每隔7天清理数据。
消息列队常见场景:系统之间解耦合、峰值压力缓冲、异步通信。
2. kafka生产消息、存储消息、消费消息
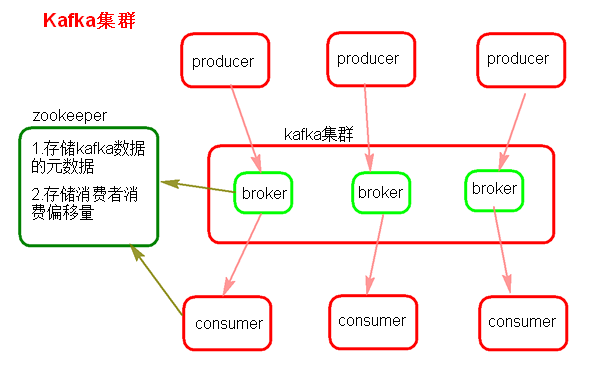
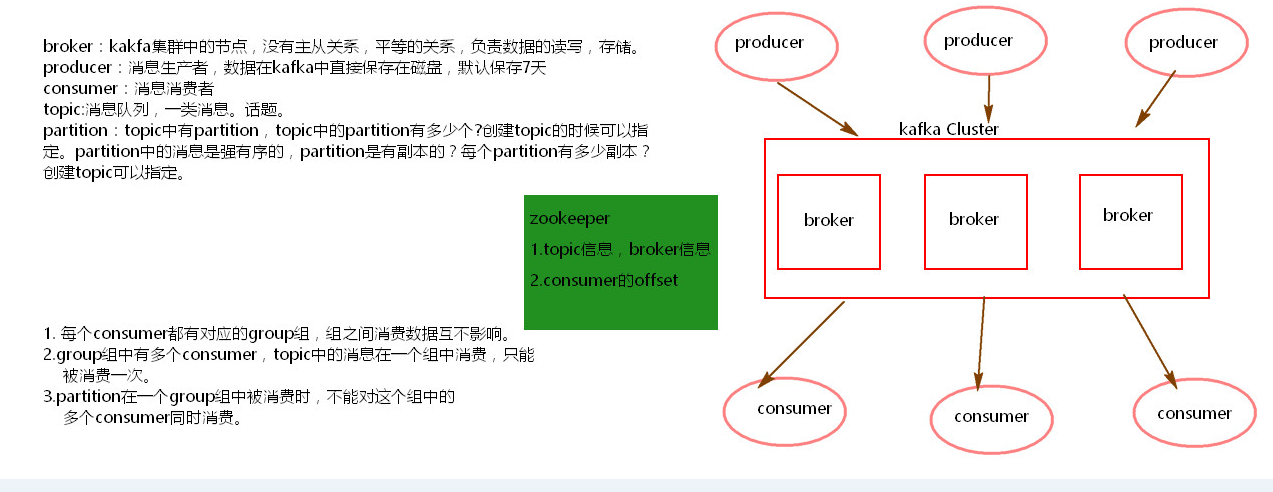
1)Kafka架构是由producer(消息生产者)、consumer(消息消费者)、borker(kafka集群的server,负责处理消息读、写请求,存储消息,在kafka cluster这一层这里,其实里面是有很多个broker)、topic(消息队列/分类相当于队列,里面有生产者和消费者模型)、zookeeper(元数据信息存在zookeeper中,包括:存储消费偏移量,topic话题信息,partition信息) 这些部分组成。
2)kafka里面的消息是有topic来组织的,简单的我们可以想象为一个队列,一个队列就是一个topic,然后它把每个topic又分为很多个partition,这个是为了做并行的,在每个partition内部 消息强有序,相当于有序的队列,其中每个消息都有个序号offset,比如0到12,从前面读往后面写。一个partition对应一个broker,一个broker可以管多个partition,比如说,topic有6个partition,有两个broker,那每个broker就管3个partition。这个partition可以很简单想象为一个文件,当数据发过来的时候它就往这个partition上面append,追加就行,消息不经过内存缓冲,直接写入文件,kafka和很多消息系统不一样,很多消息系统是消费完了我就把它删掉,而kafka是根据时间策略删除,而不是消费完就删除,在kafka里面没有一个消费完这么个概念,只有过期这样一个概念。
3)producer自己决定往哪个partition里面去写,这里有一些的策略,譬如如果hash,不用多个partition之间去join数据了。consumer自己维护消费到哪个offset
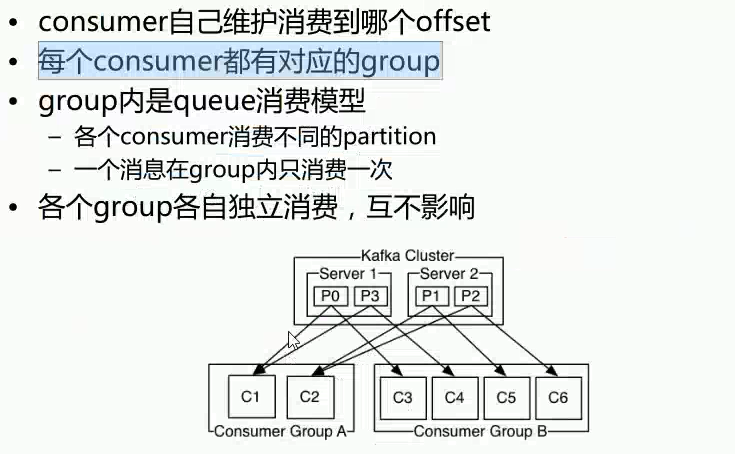
4)每个consumer都有对应的group,group内是queue消费模型(各个consumer消费不同的partition,因此一个消息在group内只消费一次),group间是publish-subscribe消费模型,各个group各自独立消费,互不影响,因此一个消息在同一个group中只消费一次。
3. kafka的特点
系统的特点:生存者消费者模型,FIFO
Partition内部是FIFO的,partition之间呢不是FIFO的,当然我们可以把topic设为一个partition,这样就是严格的FIFO。
高性能:单节点支持上千个客户端,百MB/s吞吐,接近网卡的极限
持久性:消息直接持久化在普通磁盘上且性能好
直接写到磁盘中去,就是直接append到磁盘里去,这样的好处是直接持久化,数据不会丢失,第二个好处是顺序写,然后消费数据也是顺序的读,所以持久化的同时还能保证顺序,比较好,因为磁盘顺序读比较好。
分布式:数据副本冗余、流量负载均衡、可扩展
分布式,数据副本,也就是同一份数据可以到不同的broker上面去,也就是当一份数据,磁盘坏掉的时候,数据不会丢失,比如3个副本,就是在3个机器磁盘都坏掉的情况下数据才会丢,在大量使用情况下看这样是非常好的,负载均衡,可扩展,在线扩展,不需要停服务。
很灵活:消息长时间持久化+Client维护消费状态
消费方式非常灵活,第一原因是消息持久化时间跨度比较长,一天或者一星期等,第二消费状态自己维护消费到哪个地方了可以自定义消费偏移量。
4. kafka集群搭建
1) 上传kafka_2.10-0.8.2.2.tgz包到三个不同节点上(weekend11,weekend12,weekend13),解压。
2) 配置../ kafka_2.10-0.8.2.2/config/server.properties文件
节点编号:(不同节点按0,1,2,3整数来配置)
broker.id=0
真实数据存储位置:
log.dirs=/kafkalog/kafka-logs
hostname=节点的ip
zookeeper的节点:
zookeeper.connect=weekend11:2181,weekend12:2181,weekend13:2181
3) 启动zookeeper集群。
4) 三个节点上,启动kafka
bin/kafka-server-start.sh /usr/local/kafka_2.10/config/server.properties
最好使用自己写的脚本启动,将启动命令写入到一个文件:
| nohup bin/kafka-server-start.sh config/server.properties > kafka.log 2>&1 & 脚本附件: (放在与bin同一级别下,注意创建后要修改权限:chmod 755 startkafka.sh) |
5) 相关命令:
创建topic:weekend11节点
bin/kafka-topics.sh --zookeeper weekend11:2181,weekend12:2181,weekend13:2181 --create --topic tysj1992 --partitions 3 --replication-factor 3
用一台节点控制台来当kafka的生产者:weekend11节点
| bin/kafka-console-producer.sh --broker-list weekend11:9092,weekend12:9092,weekend13:9092 --topic topic2017 |
用另一台节点控制台来当kafka的消费者: weekend12节点
| bin/kafka-console-consumer.sh --zookeeper weekend11:2181,weekend12:2181,weekend13:2181 --topic topic2017 |
查看kafka中topic列表:
| bin/kafka-topics.sh --list --zookeeper weekend11:2181,weekend12:2181,weekend13:2181 |
查看kafka中topic的描述:
| bin/kafka-topics.sh --describe --zookeeper weekend11:2181,weekend12:2181,weekend13:2181 --topic topic2017 注意:ISR是检查数据的完整性有哪些个节点。 |
查看zookeeper中topic相关信息:
| 启动zookeeper客户端: ./zkCli.sh 查看topic相关信息: ls /brokers/topics/ 查看消费者相关信息: ls /consumers |
6) kafka的leader的均衡机制
当一个broker停止或者crashes时,所有本来将它作为leader的分区将会把leader转移到其他broker上去,极端情况下,会导致同一个leader管理多个分区,导致负载不均衡,同时当这个broker重启时,如果这个broker不再是任何分区的leader,kafka的client也不会从这个broker来读取消息,从而导致资源的浪费。
kafka中有一个被称为优先副本(preferred replicas)的概念。如果一个分区有3个副本,且这3个副本的优先级别分别为0,1,2,根据优先副本的概念,0会作为leader 。当0节点的broker挂掉时,会启动1这个节点broker当做leader。当0节点的broker再次启动后,会自动恢复为此partition的leader。不会导致负载不均衡和资源浪费,这就是leader的均衡机制。
在配置文件conf/ server.properties中配置开启(默认就是开启):
| auto.leader.rebalance.enable true |
5.SparkStreaming与Kafka整合
1)receiver模式原理图
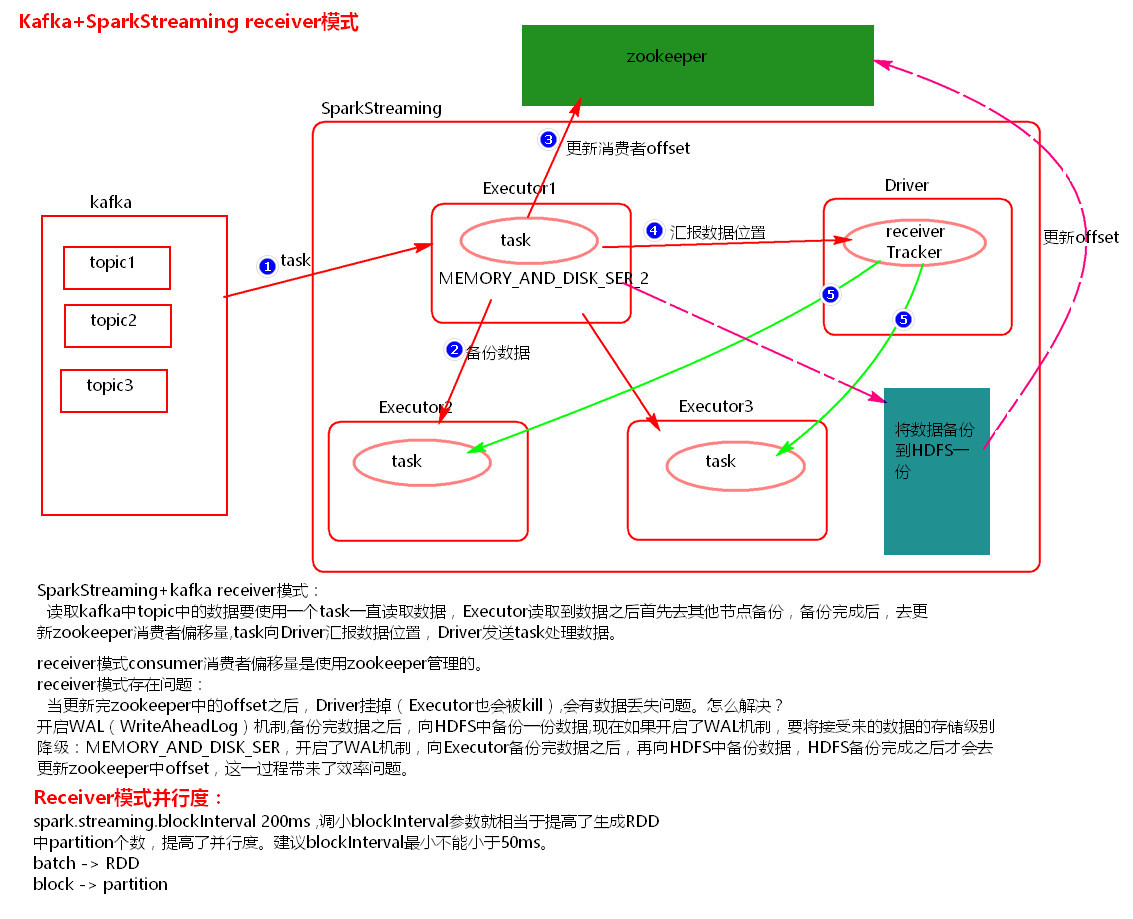
--receiver模式理解:
在SparkStreaming程序运行起来后,Executor中会有receiver tasks接收kafka推送过来的数据。数据会被持久化,默认级别为MEMORY_AND_DISK_SER_2,这个级别也可以修改。receiver task对接收过来的数据进行存储和备份,这个过程会有节点之间的数据传输。备份完成后去zookeeper中更新消费偏移量,然后向Driver中的receiver tracker汇报数据的位置。最后Driver根据数据本地化将task分发到不同节点上执行。
--receiver模式中存在的问题
当Driver进程挂掉后,Driver下的Executor都会被杀掉,当更新完zookeeper消费偏移量的时候,Driver如果挂掉了,就会存在找不到数据的问题,相当于丢失数据。
如何解决这个问题?
开启WAL(write ahead log)预写日志机制,在接受过来数据备份到其他节点的时候,同时备份到HDFS上一份(我们需要将接收来的数据的持久化级别降级到MEMORY_AND_DISK),这样就能保证数据的安全性。不过,因为写HDFS比较消耗性能,要在备份完数据之后才能进行更新zookeeper以及汇报位置等,这样会增加job的执行时间,这样对于任务的执行提高了延迟度。
--receiver模式代码(见代码)
weekend11节点创建topic
| bin/kafka-topics.sh --zookeeper weekend11:2181,weekend12:2181,weekend13:2181 --create --topic tysj1992 --partitions 3 --replication-factor 3 |
SparkStreamingDataManuallyProducerForKafka类向kafka中生产数据。
weekend12节点作为消费者
| bin/kafka-console-consumer.sh --zookeeper weekend11:2181,weekend12:2181,weekend13:2181 --topic tysj1992 |
SparkStreamingOnKafkaReceiver类作为消费者消费数据。
--receiver的并行度设置
receiver的并行度是由spark.streaming.blockInterval来决定的,默认为200ms,假设batchInterval为5s,那么每隔blockInterval就会产生一个block,这里就对应每批次产生RDD的partition,这样5秒产生的这个Dstream中的这个RDD的partition为25个,并行度就是25。如果想提高并行度可以减少blockInterval的数值,但是最好不要低于50ms。
2) Driect模式
--Direct模式理解
SparkStreaming+kafka 的Driect模式就是将kafka看成存数据的一方,不是被动接收数据,而是主动去取数据。消费者偏移量也不是用zookeeper来管理,而是SparkStreaming内部对消费者偏移量自动来维护,默认消费偏移量是在内存中,当然如果设置了checkpoint目录,那么消费偏移量也会保存在checkpoint中。当然也可以实现用zookeeper来管理。
Direct模式并行度设置
Direct模式的并行度是由读取的kafka中topic的partition数决定的。
Direct模式代码(见代码)
总结:
Receiver模式:
1、采用receiver接受器方式,需要一个task来接受数据。
2、Receiver的消费偏移量使用zookeeper管理。
3、Receiver模式的并行度 spark.streaming.blockInterval 200 blockInterval建议不小于50ms
4、会有数据丢失问题?
- 开启WAL要将接受来的数据级别降级"_2"去掉
- 开启WAL(WriteAheadLog)将数据存放在HDFS上一份
- 开启WAL会有执行效率问题,因为将数据在HDFS上备份完成之后才会汇报offset,发送task
Direct模式
1、不用单独一个task来接受数据
2、消费者偏移量Spark自己管理
3、默认在内存中
4、如果设置了checkpoint目录,在checkpoint目录中也有一份
5、Direct模式并行度设置:与读取kafka中topic中的partition个数相同