版权声明:本文为博主原创学习笔记,如需转载请注明来源。 https://blog.csdn.net/SHU15121856/article/details/83902626
学习《Python3爬虫、数据清洗与可视化实战》时自己的一些实践。
在去哪儿网PC端自由行页面,用户需要输入出发地和目的地,点击开始定制,然后就可以看到一系列相关的旅游产品。在这个旅游产品页换页不会改变URL,而是重新加载,这时页码没有体现在URL中,这种动态页面用传统的爬虫实现不了。
安装配置
Selenium本身用Anaconda安装,作为模拟用户行为的自动化测试工具,它另外还要使用浏览器驱动。在这篇里讲述了Chrome和其驱动ChromeDriver的兼容关系,驱动可以直接在官网下载,解压后直接放在系统环境变量目录下就可以,我放在Anaconda目录下了。
XPath的选取和使用
XPath使用路径表达式来选取XML文档中的节点或节点集,在Chrome中通过检查元素可以很方便的定位并获取HTML中某个或某些元素的XPath:
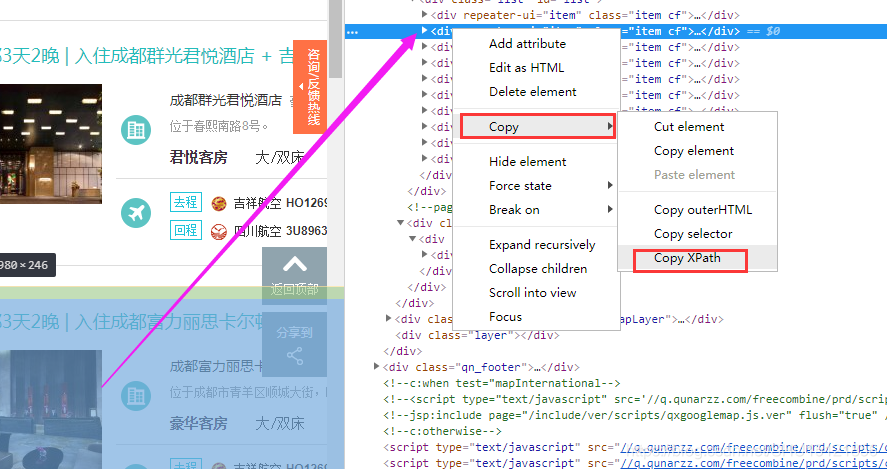 图中元素的XPath是
图中元素的XPath是//*[@id="list"]/div[2],这表示它是该列表中的第二个div,如果需要选取整个列表,在使用时XPath只要不指明下标就可以了,在这里也就是//*[@id="list"]/div。
在使用时,注意driver.find_element_by_xpath()返回的是一个WebElement对象,driver.find_elements_by_xpath()才能返回可迭代的一系列对象,两个函数仅有一个字母s之差,很容易弄混。
爬虫代码
import requests
import urllib.request
import time
import random
from selenium import webdriver
from selenium.webdriver.common.by import By # 用于指定HTML文件中的DOM元素
from selenium.webdriver.support.ui import WebDriverWait # 用于等待网页加载完成
from selenium.webdriver.support import expected_conditions as EC # 用于指定标志网页加载结束的条件
'''
去哪网PC端自由行 https://fh.dujia.qunar.com/?tf=package
ChromeDriver下载 https://npm.taobao.org/mirrors/chromedriver
'''
# 出发地城市列表
dep_citys = ['北京', '上海', '杭州', '南京', '深圳', '成都']
# 每次发送请求隔一会(模拟用户的输入和检查较慢)
def get_resp(url):
time.sleep(5)
return requests.get(url)
if __name__ == '__main__':
# 控制循环次数
j = k = 0
# 用驱动打开Chrome浏览器
driver = webdriver.Chrome()
# 对每个出发地
for dep in dep_citys:
url = 'https://touch.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(
urllib.request.quote(dep))
response = get_resp(url)
# 查询到的就是该出发地选定后供选择的若干目的地
arrv_dict = response.json()
for data_it in arrv_dict['data']: # 这里得到的是列表中的一项项dict
j += 1
if j > 4:
break
for subMod_it in data_it['subModules']: # 该dict里面subModules列表里的每一项
k += 1
if k > 6:
break
for item_it in subMod_it['items']: # 该项的item字段所示列表的每一项
# 通过浏览器打开网页
driver.get('https://fh.dujia.qunar.com/?tf=package')
# WebDriverWait(driver, 10)意思是使driver保持等待,最多10秒
# .until()里指定等待的是什么事件
# EC.presence_of_element_located()里面指定标志等待结束的DOM元素
# 里面传入元组(By.ID, "depCity")意思是等待id="depCity"的元素加载完成
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "depCity")))
# 在Chrome检查元素后,直接右键Copy XPath即可选择相应的元素!
# 将出发地清空
driver.find_element_by_xpath("//*[@id='depCity']").clear()
# 将出发地写进去
driver.find_element_by_xpath("//*[@id='depCity']").send_keys(dep)
# 将目的地写进去
driver.find_element_by_xpath("//*[@id='arrCity']").send_keys(item_it['query'])
# 点击[开始定制]按钮
driver.find_element_by_xpath("/html/body/div[2]/div[1]/div[2]/div[3]/div/div[2]/div/a").click()
print("dep:%s arrv:%s" % (dep, item_it['query']))
# 最多抓3页
for i in range(3):
time.sleep(random.uniform(5, 6)) # 随机等待5~6秒,模拟用户每页看个五六秒
# 关于[下一页]按钮:在不同的页上,下一页按钮的XPath是不一样的,比如下面两个
# // *[ @ id = "pager"] / div / a[8]
# // *[ @ id = "pager"] / div / a[7]
# 因此不能通过这种方式来实现点击下一页
# 可以用XPath获得翻页的整块元素,然后在其中找'下一页'按钮
page_btn_a_s = driver.find_elements_by_xpath('//*[@id="pager"]/div/a')
# 如果获取不到页码按钮,说明从出发地到目的地没有产品,直接跳出
if not page_btn_a_s:
break
# 旅行方案产品列表
routes = driver.find_elements_by_xpath('//*[@id="list"]/div')
# 如果第一页就没有旅行产品(如北京到泰国),那么后面的页也不会有
if not routes:
break
for route in routes:
result = {
'date': time.strftime('%Y-%m-%d', time.localtime(time.time())),
'dep': dep,
'arrv': item_it['query'],
'result': route.text
}
print(result) # 这里可以做存到数据库的操作
has = False # 记录是否找得到'下一页'
for a in page_btn_a_s:
if a.text == u"下一页":
has = True
a.click()
break
if not has: # 如果没找到下一页
break # 说明已经是最后一页,结束这一系产品的循环
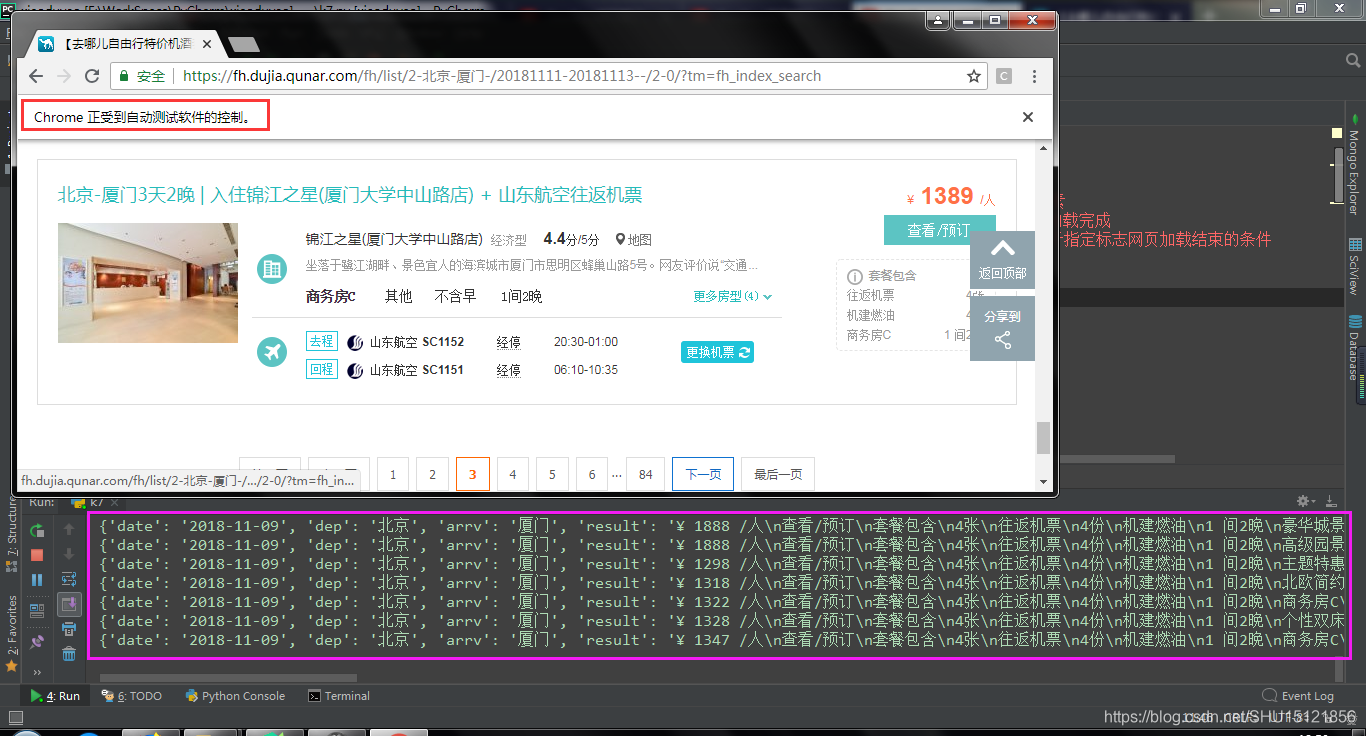
运行结果
善后处理
后台可能还存在chromedriver进程:
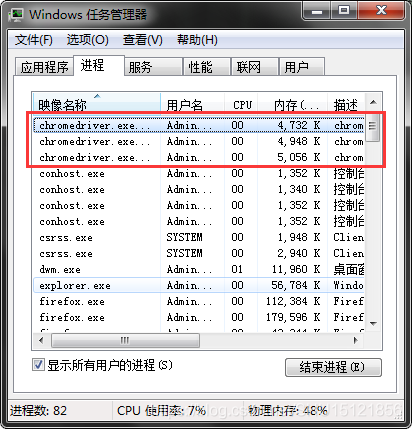
任务管理器里右键->结束进程树。