Motorola、Intel CAN DBC 布局
嵌入式软件开发中大多都与CAN打交道,但是不同项目CAN协议以及格式均会有一定的差异,软件如何处理才会更加便捷,更加模块化呢?本文主要描述不同模式下DBC的内部布局,后续会更新DBC文件解析;基于DBC文件自动生成代码。
一:Motorola 与Intel 格式浅析
1):Motorola 格式定义:
当一个信号的数据长度超过 1 个字节(8 位)或者数据长度不超过一个字节但是采用跨字节方式实
现时,该信号的高位(S_msb)将被放在低字节(MSB)的高位,信号的低位(S_lsb)将被放在高字节
(LSB)的低位。
2):Intel 格式定义:
当一个信号的数据长度超过1 个字节(8 位)或者数据长度不超过一个字节但是采用跨字节方式实
现时,该信号的高位(S_msb)将被放在高字节(MSB)的高位,信号的低位(S_lsb)将被放在低字节
(LSB)的低位。
分析如下:
- 定义A信号:起始位:3,长度12;大端格式
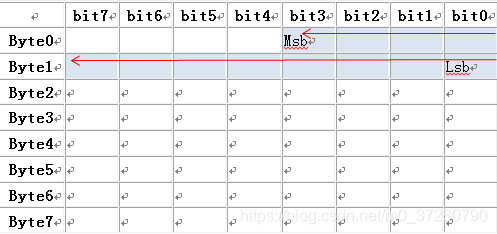
假设A信号数据为0x123,如何排布?【高字节对应Msb原则】
Byte 0: * * * * 0 0 0 1
Byte 1:0 0 1 0 0 0 1 1
- 定义B信号:起始位:12,长度8;小端:
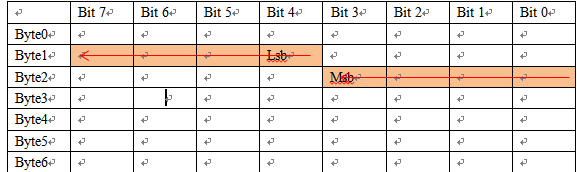
假设B信号数据为0x35,如何排布?【高字节对应Lsb原则】
Byte 1:0 1 0 1 * * * *
Byte 1:* * * * 0 0 1 1
总结:仅当信号存在跨字节的情况,才考虑这种大端小端问题;大端格式:高字节对应Msb;小端:高字节对应Lsb;
【大家可以看下Motorola、Intel CAN差异相关文档,这里不细述!】
个人觉得:作为开发人员仅仅知道大端小端差别是不够的,还要知道不同模式下CAN内部的布局,便于软件CAN解析及开发!
二:基于大端小端格式的CAN 布局
按照上述规则,如果要你定义一个信号 C【起始位 44;长度10】,分别以Motorola、Intel格式在DBC中布局:
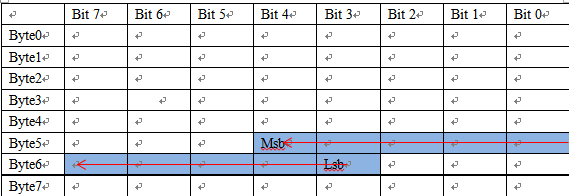
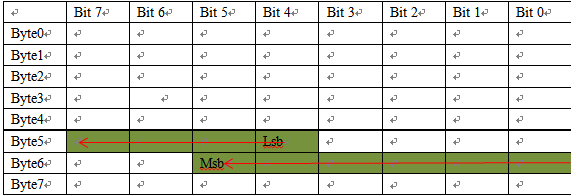
此时会发现大端,小端格式下CAN布局是不一致的,如此布局的原理是什么?我自己总结了一下,还是挺好用的,嘻嘻.
1):基于不同的模式定义起始位为Msb还是Lsb;【大端:定义为Msb;小端:定义为Lsb】
2):明确一个Byte里箭头走向“![]() ”
”
3):Intel格式:Lsb位可以理解为该Byte内最小的位,所以该信号只能占Lsb左边的位;当跨字节时,考虑上下箭头走向是否冲突,即跨字节时从右向左逐一分布位,直至信号长度符合预期;
4):Motorola格式:Msb位可以理解为该Byte内最大的位,所以该信号只能占Lsb右边的位;当跨字节时,考虑上下箭头走向是否冲突,即跨字节时从左向右逐一分布位,直至信号长度符合预期;