1. 正则表达式, Regular Expression 是对字符串操作的一种逻辑公式
优点: 灵活, 功能性强, 逻辑性强.
缺点: 上⼿难. ⼀旦上⼿, 会爱上这个东⻄
1. 元字符: [] 的内容会被匹配 例如:[abc] 匹配a或b或c
思考: [a-zA-Z0-9]匹配的是什么? 按照编码的顺序填写
2. 简单元字符 (单一字符)

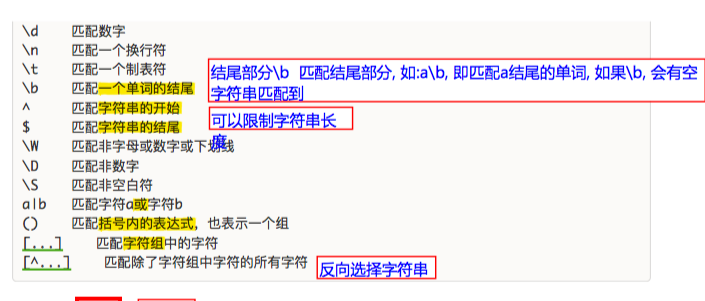
3. 量词 (限定符)

4. 惰性匹配和贪婪匹配
*, +, {} 属于贪婪匹配, .*? 属于惰性匹配
5. 分组 用来获取数据
()进行分组, 提高优先级,
6. 转义
正则表达式前面加上 r, 如果遇到需要转义的字符加上 \
练习:
1. 匹配邮箱
2. 匹配⼿机号
3. 匹配⽣⽇. ⽇期格式(yyyy-MM-dd)
4. 匹配电话号码
5. 匹配IP
2. re模块 关于处理正则表达式的模块, 核心功能有四个:\
1. findall 查找所有, 返回list, 结合for循环使用
2. search 匹配到第一个结果, 就返回这个结果, 如果匹配不到返回None
3. match 只能从字符串的开头进行匹配
4. finditer 和findall差不多, 但是返回是迭代器, 可以结合for循环使用
import re res = re.search("e", "alex and exp") # 搜索. 搜到结果就返回 print(res.group()) # e res = re.match("\w+", "alex is not a good man") # 从头匹配. 如果匹配到了。 就返回 print(res.group()) # alex lst = re.findall("\w+", "alex and exo") print(lst) # ['alex', 'and', 'exo'] it = re.finditer("\w+", "mai le fo leng") for el in it: print(el.group())
其他操作:
1. split 根据正则切割
# 加了括号。 split会保留你切的刀 lst = re.split("([ab])", "alex is not a sb, no he is a big sb") # 根据正则表达式进行切割 print(lst) # ['', 'a', 'lex is not ', 'a', ' s', 'b', ', no he is ', 'a', ' ', 'b', 'ig s', 'b', ''] # 不加括号, 是正常切割 lst = re.split("[ab]", "alex is not a sb, no he is a big sb") # 根据正则表达式进行切割 print(lst) #['', 'lex is not ', ' s', ', no he is ', ' ', 'ig s', '']
2. sub, subn 替换
# 替换 res = re.sub(r"\d+", "_sb_", "alex333wusir666taibai789ritian020feng") print(res) #alex_sb_wusir_sb_taibai_sb_ritian_sb_feng # 替换。 返回的结果带有次数 res = re.subn(r"\d+", "_sb_", "alex333wusir666taibai789ritian020feng") print(res) #('alex_sb_wusir_sb_taibai_sb_ritian_sb_feng', 4)
3. compile 正则表达式编译
obj = re.compile(r"alex(?P<name>\d+)and") # 把正则表达式预加载 res = obj.search("alex250andwusir38ritian2") print(res.group()) # alex250and print(res.group("name")) # 250
3. 简单爬虫
周末作业:
import re, json from urllib.request import urlopen def Item(url): url_ = urlopen(url).read().decode('gbk') obj1 = re.compile(r'<div id="Zoom">.*?◎译 名 (?P<yiming>.*?)<br />.*? <td style=.*?<a href="(?P<download>.*?)">ftp://', re.S) it = obj1.finditer(url_) for el in it: yield {"name": el.group("yiming"), "adress": el.group("download")} url = urlopen('https://www.dytt8.net').read().decode('gbk') obj2 = re.compile(r"<td width=.*?最新电影下载.*?<a href='(?P<download>.*?)'>.*?</a><br/>", re.S) lst = obj2.findall(url) f = open('movie.json', 'a', encoding="utf-8") for i in lst: add = 'https://www.dytt8.net' + i ret = Item(add) for el in ret: s = json.dumps(el, ensure_ascii=False) f.write(s + "\n") f.close()