soup.select以及爬取信息出现空列表的情况
举例
以爬取csdn首页为例 https://www.csdn.net/

一、先说soup.select()中的填写
方法一
直接 检查 右键 copy–>selector
有些网站做有反爬取,(例如58同城),用这个方法不行。只能用方法二。

会出现一下错误 nth-of-type

修改改正方法:

代码如下:
注意如果运行不成功,请更改headers,下方有修改方法。
import requests
from bs4 import BeautifulSoup
URL = 'https://www.csdn.net/'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' }
wb_data = requests.get(URL, headers=headers)
soup = BeautifulSoup(wb_data.content, 'lxml')
#print(soup)
#namelist = soup.select('#feedlist_id > li:nth-child(1) > div > div.title > h2 > a')
#有时候将nth-child(1)修改为nth-of-type也是可以的
#namelist = soup.select('#feedlist_id > li:nth-of-type > div > div.title > h2 > a')
namelist = soup.select('#feedlist_id > li > div > div.title > h2 > a')
print(namelist[0].text.strip())
#.text作用是得到文本,.strip()作用是去掉字符串两边的空格及换行
结果:

方法二
观察法,可以看到标题 检查 出来的索引位置在 a标签 下,而a标签在 h2标签 下,h2又在 div标签下的class=‘title’ 下,(知道定位的最近的class为止,如果这样定位,爬取结果有多条的话,可以继续找父节点)
即应该写 soup.select(‘div.title > h2 > a’)
注意:将class写成 点 ‘.’ ,每个>符号两边都要有 空格 。


代码如下:
如果运行错误,注意修改headers,具体我也没在别的电脑上试。
import requests
from bs4 import BeautifulSoup
URL = 'https://www.csdn.net/'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' }
wb_data = requests.get(URL, headers=headers)
soup = BeautifulSoup(wb_data.content, 'lxml')
#print(soup)
namelist = soup.select('div.title > h2 > a')
print(namelist[0].text.strip())
#.text作用是得到文本,.strip()作用是去掉字符串两边的空格及换行
结果:

方法三

定位到div.title > h2 > a就可以了。
headers的修改方法,以及伪造假登陆。
修改headers
headers是我本机的一个信息,你们运行应该会报错,解决方法进入浏览器,右键检查,按照步骤来,之后复制,替换 headers字典 中内容:
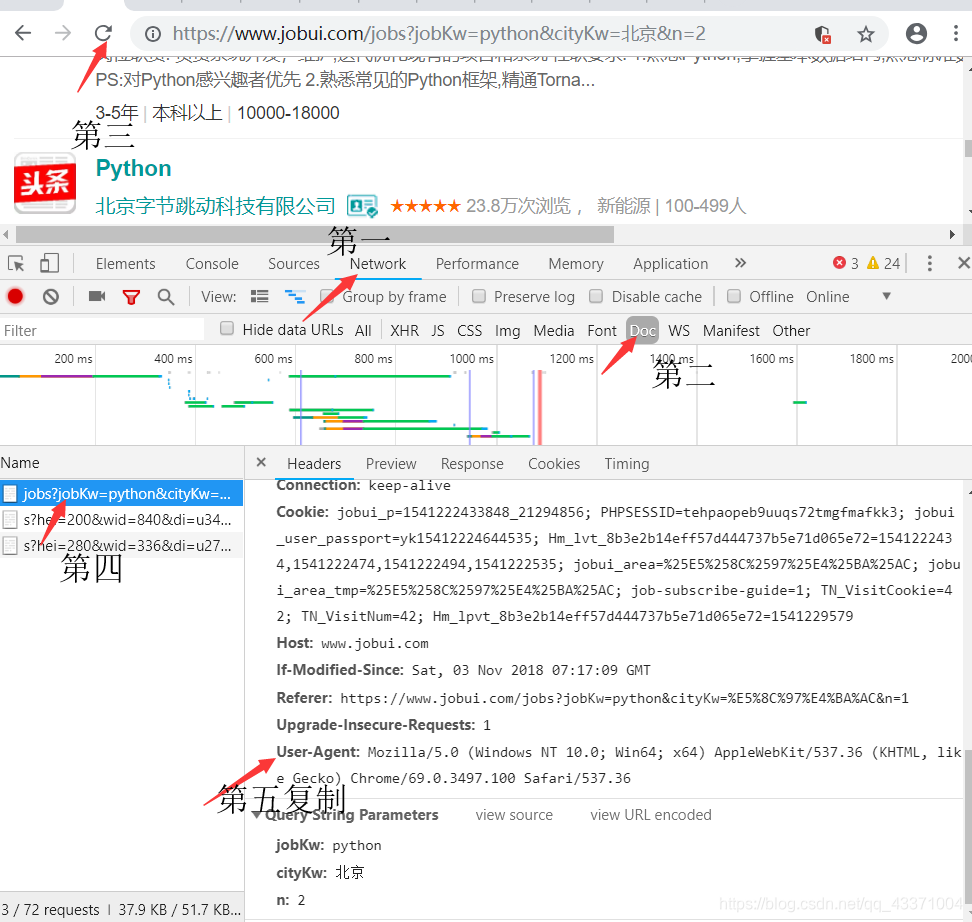
headers相当于模拟你的电脑浏览器在访问,如果不写headers,网页就会反爬取,会出现你被限制,需要你输入验证码之类的,此时你继续运行代码也会出现 空列表 的情况。

伪造假登陆
一样按照headers的方法,将Cookie添加到headers字典中

例如代码部分:
import requests
from bs4 import BeautifulSoup
URL = 'https://www.csdn.net/'
#在字典headers中添加Cookie这一项。
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Cookie': 'ADHOC_MEMBERSHIP_CLIENT_ID1.0 = 850d4feb - 21e9 太长了,我删除了,你写自己的就可以了。'}
wb_data = requests.get(URL, headers=headers)
soup = BeautifulSoup(wb_data.content, 'lxml')
#print(soup)
--------------------------------------------------------------------------------------------------------
谢谢支持。本人学习经验交流。大佬牛逼方法,请留言共享谢谢。