1.Sklearn篇
# load_iris是机器学习库自带研究算法的数据 鸢尾花
from sklearn.datasets import load_iris
# 获取训练数据
iris=load_iris()
# iris
# 获取数据
data=iris.data
target=iris.target
target_names=iris.target_names
feature_names=iris.feature_names
from pandas import Series,DataFrame
features=DataFrame(data=data,columns=feature_names)
features.head()
features.iloc[:,0].std()
features.iloc[:,1].std()
features.iloc[:,2].std()
features.iloc[:,3].std()
# 训练数据取130条 总数据150条
X_train=features.iloc[0:130,2:4]
# X_train
y_train=target[:130]
# print(y_train)
# 测试数据取20条 总数据150条
x_test=features.iloc[130:,2:4]
y_test=target[130:]
display(X_train.shape,y_train.shape,x_test.shape,y_test.shape)
import matplotlib.pyplot as plt
%matplotlib inline
samples=features.iloc[:,2:4]
# display(samples)
# 横坐标花瓣的长度 纵坐标花瓣的宽度 颜色不同代表花瓣种类不同
plt.scatter(samples.iloc[:,0],samples.iloc[:,1],c=target)
# 训练数据
knnclf.fit(X_train,y_train)
# 计算精确度
knnclf.score(x_test[:20],y_test[:20])
# 预测
y_=knnclf.predict(x_test)
# 模型准确度的评估 y_test真实的鸢尾花分类
y_test
# 预测的鸢尾花分类
y_
上述代码对比展示预测分类与真实分类并计算精确度
图形化代码
from matplotlib.colors import ListedColormap
cmap=ListedColormap(['#FF0000','#00FF00','#0000FF'])
# 花瓣的长度最小值到最大值范围
xmin,xmax=samples.iloc[:,0].min(),samples.iloc[:,0].max()
# 花瓣的宽度最小值到最大值范围
ymin,ymax=samples.iloc[:,1].min(),samples.iloc[:,1].max()
display(xmin,xmax,ymin,ymax)
x=np.linspace(xmin,xmax,100)
y=np.linspace(ymin,ymax,100)
display(x,y)
xx,yy=np.meshgrid(x,y)
display(xx,yy)
x_test=np.c_[xx.ravel(),yy.ravel()]
display(x_test,x_test.shape)
# 预测
y_=knnclf.predict(x_test)
y_test
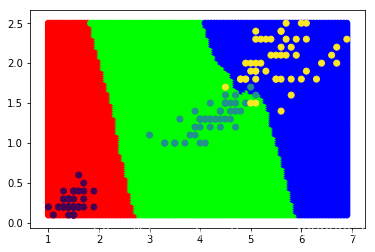
#绘制图形
plt.scatter(x_test[:,0],x_test[:,1],c=y_,cmap=cmap)
plt.scatter(samples.iloc[:,0],samples.iloc[:,1],c=target)
图形化分类展示结果