一. LinkedHashMap 概述
HashMap 是 Java Collection Framework 的重要成员,也是Map族(如下图所示)中我们最为常用的一种。不过遗憾的是,HashMap是无序的,也就是说,迭代HashMap所得到的元素顺序并不是它们最初放置到HashMap的顺序。HashMap的这一缺点往往会造成诸多不便,因为在有些场景中,我们确需要用到一个可以保持插入顺序的Map。庆幸的是,JDK为我们解决了这个问题,它为HashMap提供了一个子类 —— LinkedHashMap。虽然LinkedHashMap增加了时间和空间上的开销,但是它通过维护一个额外的双向链表保证了迭代顺序。特别地,该迭代顺序可以是插入顺序,也可以是访问顺序。因此,根据链表中元素的顺序可以将LinkedHashMap分为:保持插入顺序的LinkedHashMap 和 保持访问顺序的LinkedHashMap,其中LinkedHashMap的默认实现是按插入顺序排序的。
所谓LinkedHashMap,其落脚点在HashMap,因此更准确地说,它是一个将所有Entry节点链入一个双向链表双向链表的HashMap。在LinkedHashMapMap中,所有put进来的Entry都保存在如下面第一个图所示的哈希表中,但由于它又额外定义了一个以head为头结点的双向链表(如下面第二个图所示),因此对于每次put进来Entry,除了将其保存到哈希表中对应的位置上之外,还会将其插入到双向链表的尾部。
![![哈希表.png-10.2kB][4]](https://img-blog.csdn.net/20170317181650025?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvanVzdGxvdmV5b3Vf/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
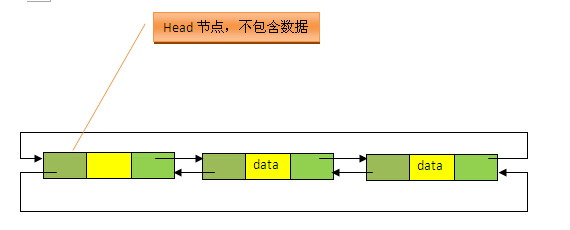
由于LinkedHashMap是HashMap的子类,所以LinkedHashMap自然会拥有HashMap的所有特性。比如,LinkedHashMap也最多只允许一条Entry的键为Null(多条会覆盖),但允许多条Entry的值为Null。此外,LinkedHashMap 也是 Map 的一个非同步的实现。此外,LinkedHashMap还可以用来实现LRU (Least recently used, 最近最少使用)算法,这个问题会在下文的特别谈到。
二. LinkedHashMap 在 JDK 中的定义
1、类结构定义
LinkedHashMap继承于HashMap,其在JDK中的定义为:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V> {
...
}2、成员变量定义
与HashMap相比,LinkedHashMap增加了两个属性用于保证迭代顺序,分别是 双向链表头结点header 和 标志位accessOrder (值为true时,表示按照访问顺序迭代;值为false时,表示按照插入顺序迭代)。
private transient Entry<K,V> header; // 双向链表的表头元素
private final boolean accessOrder; //true表示按照访问顺序迭代,false时表示按照插入顺序 3、成员方法定义
从下图我们可以看出,LinkedHashMap中并增加没有额外方法。也就是说,LinkedHashMap与HashMap在操作上大致相同,只是在实现细节上略有不同罢了。

4、基本元素 Entry
LinkedHashMap采用的hash算法和HashMap相同,但是它重新定义了Entry。LinkedHashMap中的Entry增加了两个指针 before 和 after,它们分别用于维护双向链接列表。特别需要注意的是,next用于维护HashMap各个桶中Entry的连接顺序,before、after用于维护Entry插入的先后顺序的,源代码如下:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}三. LinkedHashMap 的构造函数
LinkedHashMap 一共提供了五个构造函数,它们都是在HashMap的构造函数的基础上实现的
LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
该构造函数意在构造一个指定初始容量和指定负载因子的具有指定迭代顺序的LinkedHashMap,其源码如下:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor); // 调用HashMap对应的构造函数
this.accessOrder = accessOrder; // 迭代顺序的默认值
}正如我们在《刨根问底——Map——HashMap》一文中提到的那样,初始容量 和负载因子是影响HashMap性能的两个重要参数。同样地,它们也是影响LinkedHashMap性能的两个重要参数。此外,LinkedHashMap 增加了双向链表头结点 header和标志位 accessOrder两个属性用于保证迭代顺序。
四. LinkedHashMap 的数据结构
1.本质上,LinkedHashMap = HashMap + 双向链表,也就是说,HashMap和双向链表合二为一即是LinkedHashMap。也可以这样理解,LinkedHashMap 在不对HashMap做任何改变的基础上,给HashMap的任意两个节点间加了两条连线(before指针和after指针),使这些节点形成一个双向链表。在LinkedHashMapMap中,所有put进来的Entry都保存在HashMap中,但由于它又额外定义了一个以head为头结点的空的双向链表,因此对于每次put进来Entry还会将其插入到双向链表的尾部。
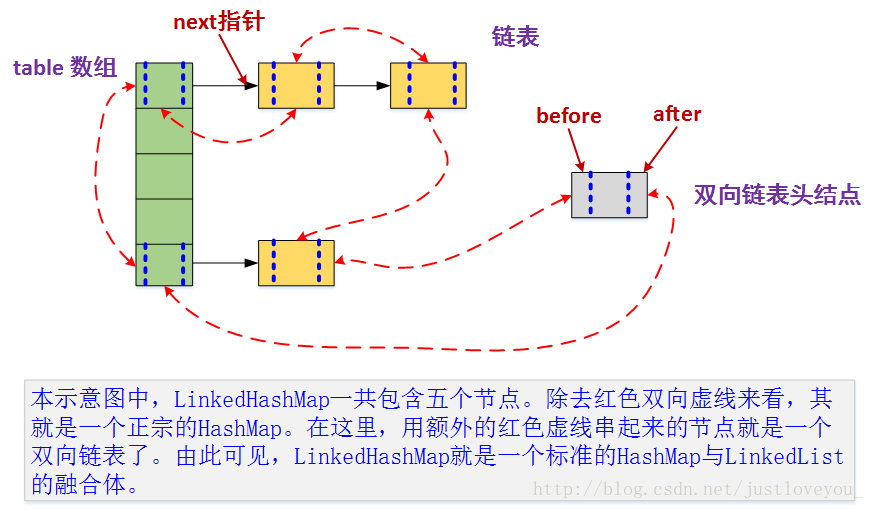
Map扩容操作的核心在于重哈希。所谓重哈希是指重新计算原HashMap中的元素在新table数组中的位置并进行复制处理的过程。鉴于性能和LinkedHashMap自身特点的考量,LinkedHashMap对重哈希过程(transfer方法)进行了重写,源码如下:
void transfer(HashMap.Entry[] newTable) {
int newCapacity = newTable.length;
// 与HashMap相比,借助于双向链表的特点进行重哈希使得代码更加简洁
for (Entry<K,V> e = header.after; e != header; e = e.after) {
int index = indexFor(e.hash, newCapacity); // 计算每个Entry所在的桶
// 将其链入桶中的链表
e.next = newTable[index];
newTable[index] = e;
}
}3.LinkedHashMap 的存取过程基本与HashMap基本类似,只是在细节实现上稍有不同,这是由LinkedHashMap本身的特性所决定的,因为它要额外维护一个双向链表用于保持迭代顺序。在put操作上,虽然LinkedHashMap完全继承了HashMap的put操作,但是在细节上还是做了一定的调整,比如,在LinkedHashMap中向哈希表中插入新Entry的同时,还会通过Entry的addBefore方法将其链入到双向链表中。在扩容操作上,虽然LinkedHashMap完全继承了HashMap的resize操作,但是鉴于性能和LinkedHashMap自身特点的考量,LinkedHashMap对其中的重哈希过程(transfer方法)进行了重写。在读取操作上,LinkedHashMap中重写了HashMap中的get方法,通过HashMap中的getEntry方法获取Entry对象。在此基础上,进一步获取指定键对应的值。
五. LinkedHashMap 与 LRU(Least recently used,最近最少使用)算法
到此为止,我们已经分析完了LinkedHashMap的存取实现,这与HashMap大体相同。LinkedHashMap区别于HashMap最大的一个不同点是,前者是有序的,而后者是无序的。为此,LinkedHashMap增加了两个属性用于保证顺序,分别是双向链表头结点header和标志位accessOrder。我们知道,header是LinkedHashMap所维护的双向链表的头结点,而accessOrder用于决定具体的迭代顺序。实际上,accessOrder标志位的作用可不像我们描述的这样简单,我们接下来仔细分析一波~
我们知道,当accessOrder标志位为true时,表示双向链表中的元素按照访问的先后顺序排列,可以看到,虽然Entry插入链表的顺序依然是按照其put到LinkedHashMap中的顺序,但put和get方法均有调用recordAccess方法(put方法在key相同时会调用)。recordAccess方法判断accessOrder是否为true,如果是,则将当前访问的Entry(put进来的Entry或get出来的Entry)移到双向链表的尾部(key不相同时,put新Entry时,会调用addEntry,它会调用createEntry,该方法同样将新插入的元素放入到双向链表的尾部,既符合插入的先后顺序,又符合访问的先后顺序,因为这时该Entry也被访问了);当标志位accessOrder的值为false时,表示双向链表中的元素按照Entry插入LinkedHashMap到中的先后顺序排序,即每次put到LinkedHashMap中的Entry都放在双向链表的尾部,这样遍历双向链表时,Entry的输出顺序便和插入的顺序一致,这也是默认的双向链表的存储顺序。因此,当标志位accessOrder的值为false时,虽然也会调用recordAccess方法,但不做任何操作。注意到我们在前面介绍的LinkedHashMap的五种构造方法,前四个构造方法都将accessOrder设为false,说明默认是按照插入顺序排序的;而第五个构造方法可以自定义传入的accessOrder的值,因此可以指定双向循环链表中元素的排序规则。特别地,当我们要用LinkedHashMap实现LRU算法时,就需要调用该构造方法并将accessOrder置为true。
六. LinkedHashMap 有序性原理分析
如前文所述,LinkedHashMap 增加了双向链表头结点header 和 标志位accessOrder两个属性用于保证迭代顺序。但是要想真正实现其有序性,还差临门一脚,那就是重写HashMap 的迭代器,其源码实现如下:
private abstract class LinkedHashIterator<T> implements Iterator<T> {
Entry<K,V> nextEntry = header.after;
Entry<K,V> lastReturned = null;
/**
* The modCount value that the iterator believes that the backing
* List should have. If this expectation is violated, the iterator
* has detected concurrent modification.
*/
int expectedModCount = modCount;
public boolean hasNext() { // 根据双向列表判断
return nextEntry != header;
}
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}
Entry<K,V> nextEntry() { // 迭代输出双向链表各节点
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
Entry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
// Key 迭代器,KeySet
private class KeyIterator extends LinkedHashIterator<K> {
public K next() { return nextEntry().getKey(); }
}
// Value 迭代器,Values(Collection)
private class ValueIterator extends LinkedHashIterator<V> {
public V next() { return nextEntry().value; }
}
// Entry 迭代器,EntrySet
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() { return nextEntry(); }
}从上述代码中我们可以知道,LinkedHashMap重写了HashMap 的迭代器,它使用其维护的双向链表进行迭代输出。
引用