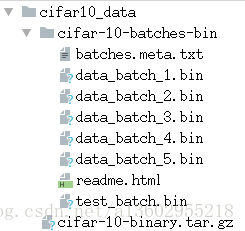
cifar10数据集文件结构如图所示,其中data_batch_1~5.bin是训练集,每个文件包含10000个样本,test_batch.bin是测试集,包含10000个样本。
打开任意一个文件,发现是一堆二进制数据,
其中一个样本由3037个字节组成,其中第一个字节是label,剩余3036(32*32*3)个字节是image,每个文件由连续的10000个样本组成,具体的读取过程参考下面代码及注释。
#获取image和label
def get_input():
#文件名队列
filenames = tf.train.match_filenames_once(DATA_DIR+'/data_batch_*')
filename_queue = tf.train.string_input_producer(filenames)
#cifar10的数据格式:
#一个样本由3037个字节组成,其中第一个字节是label,剩余3036(32*32*3)个字节是image
#每个文件由连续的10000个样本组成,共5个文件
image_bytes = IMAGE_SIZE * IMAGE_SIZE * IMAGE_DEPTH
record_bytes = image_bytes + LABEL_BYTES
#使用FixedLengthRecordReader读取样本,每次读取一个
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes)
#获取样本的值
_,value = reader.read(filename_queue)
#读出来的样本为二进制的字符串格式,转化为uint8的格式
raw_value = tf.decode_raw(value,tf.uint8)
#划分label和image
labels = tf.cast(tf.strided_slice(raw_value,[0],[1]),tf.int32)
#由于image是按照(depth,height,width)的格式存储的,因此读出来后还要将其转化为(height,width,depth)的格式
images = tf.reshape(
tf.strided_slice(raw_value,[LABEL_BYTES],[LABEL_BYTES+image_bytes]),
[IMAGE_DEPTH,IMAGE_SIZE,IMAGE_SIZE]
)
images = tf.transpose(images,[1,2,0])
images = tf.cast(images,tf.float32)
#数据类型:label是int32,image是范围为0-1的float32
#标准化处理:减去平均值并除以方差,使得样本均值为0,方差为1
standard_images = tf.image.per_image_standardization(images)
#官方bug,得加上
standard_images.set_shape([RESIZE_SIZE,RESIZE_SIZE,3])
labels.set_shape([1])
return standard_images,labels