Python实现
交并比(Intersection over Union)和非极大值抑制是(Non-Maximum Suppression)是目标检测任务中非常重要的两个概念。例如在用训练好的模型进行测试时,网络会预测出一系列的候选框。这时候我们会用NMS来移除一些多余的候选框。即移除一些IOU值大于某个阈值的框。然后在剩下的候选框中,分别计算与ground truth的IOU值,通常会规定当候选框和ground truth的IOU值大于0.5时,认为检测正确。下面我们分别用python实现IOU和NMS。
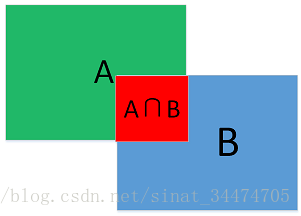
交并比IOU
如上图所示,IOU值定位为两个矩形框面积的交集和并集的比值。即:
IOU=A∩BA∪B
import numpy as np
def compute_iou(box1, box2, wh=False):
"""
compute the iou of two boxes.
Args:
box1, box2: [xmin, ymin, xmax, ymax] (wh=False) or [xcenter, ycenter, w, h] (wh=True)
wh: the format of coordinate.
Return:
iou: iou of box1 and box2.
"""
if wh == False:
xmin1, ymin1, xmax1, ymax1 = box1
xmin2, ymin2, xmax2, ymax2 = box2
else:
xmin1, ymin1 = int(box1[0]-box1[2]/2.0), int(box1[1]-box1[3]/2.0)
xmax1, ymax1 = int(box1[0]+box1[2]/2.0), int(box1[1]+box1[3]/2.0)
xmin2, ymin2 = int(box2[0]-box2[2]/2.0), int(box2[1]-box2[3]/2.0)
xmax2, ymax2 = int(box2[0]+box2[2]/2.0), int(box2[1]+box2[3]/2.0)
## 获取矩形框交集对应的左上角和右下角的坐标(intersection)
xx1 = np.max([xmin1, xmin2])
yy1 = np.max([ymin1, ymin2])
xx2 = np.min([xmax1, xmax2])
yy2 = np.min([ymax1, ymax2])
## 计算两个矩形框面积
area1 = (xmax1-xmin1) * (ymax1-ymin1)
area2 = (xmax2-xmin2) * (ymax2-ymin2)
inter_area = (np.max([0, xx2-xx1])) * (np.max([0, yy2-yy1])) #计算交集面积
iou = inter_area / (area1+area2-inter_area+1e-6) #计算交并比
return iou
非极大值抑制(NMS)
NMS的算法步骤如下:
# INPUT:所有预测出的bounding box (bbx)信息(坐标和置信度confidence), IOU阈值(大于该阈值的bbx将被移除)
for object in all objects:
(1) 获取当前目标类别下所有bbx的信息
(2) 将bbx按照confidence从高到低排序,并记录当前confidence最大的bbx
(3) 计算最大confidence对应的bbx与剩下所有的bbx的IOU,移除所有大于IOU阈值的bbx
(4) 对剩下的bbx,循环执行(2)和(3)直到所有的bbx均满足要求(即不能再移除bbx)
需要注意的是,NMS是对所有的类别分别执行的。举个栗子,假设最后预测出的矩形框有2类(分别为cup, pen),在NMS之前,每个类别可能都会有不只一个bbx被预测出来,这个时候我们需要对这两个类别分别执行一次NMS过程。
我们用python编写NMS代码,假设对于一张图片,所有的bbx信息已经保存在一个字典中,保存形式如下:
predicts_dict: {"cup": [[x1_1, y1_1, x2_1, y2_1, scores1], [x1_2, y1_2, x2_2, y2_2, scores2], ...], "pen": [[x1_1, y1_1, x2_1, y2_1, scores1], [x1_2, y1_2, x2_2, y2_2, scores2], ...]}.
即目标的位置和置信度用列表储存,每个列表中的一个子列表代表一个bbx信息。详细的代码如下:
def non_max_suppress(predicts_dict, threshold=0.2):
"""
implement non-maximum supression on predict bounding boxes.
Args:
predicts_dict: {"stick": [[x1, y1, x2, y2, scores1], [...]]}.
threshhold: iou threshold
Return:
predicts_dict processed by non-maximum suppression
"""
for object_name, bbox in predicts_dict.items(): #对每一个类别的目标分别进行NMS
bbox_array = np.array(bbox, dtype=np.float)
## 获取当前目标类别下所有矩形框(bounding box,下面简称bbx)的坐标和confidence,并计算所有bbx的面积
x1, y1, x2, y2, scores = bbox_array[:,0], bbox_array[:,1], bbox_array[:,2], bbox_array[:,3], bbox_array[:,4]
areas = (x2-x1+1) * (y2-y1+1)
#print "areas shape = ", areas.shape
## 对当前类别下所有的bbx的confidence进行从高到低排序(order保存索引信息)
order = scores.argsort()[::-1]
print "order = ", order
keep = [] #用来存放最终保留的bbx的索引信息
## 依次从按confidence从高到低遍历bbx,移除所有与该矩形框的IOU值大于threshold的矩形框
while order.size > 0:
i = order[0]
keep.append(i) #保留当前最大confidence对应的bbx索引
## 获取所有与当前bbx的交集对应的左上角和右下角坐标,并计算IOU(注意这里是同时计算一个bbx与其他所有bbx的IOU)
xx1 = np.maximum(x1[i], x1[order[1:]]) #当order.size=1时,下面的计算结果都为np.array([]),不影响最终结果
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
inter = np.maximum(0.0, xx2-xx1+1) * np.maximum(0.0, yy2-yy1+1)
iou = inter/(areas[i]+areas[order[1:]]-inter)
print "iou =", iou
print np.where(iou<=threshold) #输出没有被移除的bbx索引(相对于iou向量的索引)
indexs = np.where(iou<=threshold)[0] + 1 #获取保留下来的索引(因为没有计算与自身的IOU,所以索引相差1,需要加上)
print "indexs = ", type(indexs)
order = order[indexs] #更新保留下来的索引
print "order = ", order
bbox = bbox_array[keep]
predicts_dict[object_name] = bbox.tolist()
predicts_dict = predicts_dict
return predicts_dict
---------------------
原文:https://blog.csdn.net/sinat_34474705/article/details/80045294
========分割线==========
IOU&NMS C++实现
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
typedef struct Bbox
{
int x;
int y;
int w;
int h;
float score;
}Bbox;
bool sort_score(Bbox box1,Bbox box2)
{
return (box1.score > box2.score);
}
float iou(Bbox box1,Bbox box2)
{
int x1 = std::max(box1.x,box2.x);
int y1 = std::max(box1.y,box2.y);
int x2 = std::min((box1.x + box1.w),(box2.x + box2.w));
int y2 = std::min((box1.y + box1.h),(box2.y + box2.h));
float over_area = (x2 - x1) * (y2 - y1);
float iou = over_area/(box1.w * box1.h + box2.w * box2.h-over_area);
return iou;
}
//方法1
vector<Bbox> nms(std::vector<Bbox>&vec_boxs,float threshold)
{
std::sort(vec_boxs.begin(),vec_boxs.end(),sort_score);
std::vector<Bbox>del(vec_boxs.size(),false);
for(int i =0; i<vec_boxs.size();i++)
{
for (int j =0;j<vec_boxs.size();j++)
{
float iou_value =iou(vec_boxs[i],vec_boxs[j]);
if(iou_value>threshold)
{
del[j]=true;
}
}
}
std::vector<Bbox>results;
for(const auto i :del)
{
if(!del[i]) results.push_back(vec_box[i]);
}
return results;
}
//方法2 这种执行效率更高
vector<Bbox> nms(std::vector<Bbox>&vec_boxs,float threshold)
{
vector<Bbox>results;
while(vec_boxs.size() > 0)
{
std::sort(vec_boxs.begin(),vec_boxs.end(),sort_score);
results.push_back(vec_boxs[0]);
for(int i =0;i <vec_boxs.size()-1;i++)
{
float iou_value =iou(vec_boxs[0],vec_boxs[i+1]);
if (iou_value >threshold)
{
vec_boxs.erase(vec_boxs[i+1]);
}
}
vec_boxs.erase(vec_boxs[0]);
}
}
---------------------
原文:https://blog.csdn.net/qq_32582681/article/details/81352758
原理:
对于Bounding Box的列表B及其对应的置信度S,选择具有最大score的检测框M,将其从B集合中移除并加入到最终的检测结果D中.通常将B中剩余检测框中与M的IoU大于阈值Nt的框从B中移除.重复这个过程,直到B为空
实现过程:


就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。
非极大值抑制:先假设有6个候选框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。
1、从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
2、假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
3、从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
4、一直重复这个过程,找到所有曾经被保留下来的矩形框。
//升序排列
bool cmpScore(Bbox lsh, Bbox rsh) {
if (lsh.score < rsh.score)
return true;
else
return false;
}
void nms(vector<Bbox> &boundingBox_, const float overlap_threshold, string modelname = "Union"){
if(boundingBox_.empty()){
return;
}
//对各个候选框根据score的大小进行升序排列
sort(boundingBox_.begin(), boundingBox_.end(), cmpScore);
float IOU = 0;
float maxX = 0;
float maxY = 0;
float minX = 0;
float minY = 0;
vector<int> vPick;
int nPick = 0;
multimap<float, int> vScores; //存放升序排列后的score和对应的序号
const int num_boxes = boundingBox_.size();
vPick.resize(num_boxes);
for (int i = 0; i < num_boxes; ++i){
vScores.insert(pair<float, int>(boundingBox_[i].score, i));
}
while(vScores.size() > 0){
int last = vScores.rbegin()->second; //反向迭代器,获得vScores序列的最后那个序列号
vPick[nPick] = last;
nPick += 1;
for (multimap<float, int>::iterator it = vScores.begin(); it != vScores.end();){
int it_idx = it->second;
maxX = max(boundingBox_.at(it_idx).x1, boundingBox_.at(last).x1);
maxY = max(boundingBox_.at(it_idx).y1, boundingBox_.at(last).y1);
minX = min(boundingBox_.at(it_idx).x2, boundingBox_.at(last).x2);
minY = min(boundingBox_.at(it_idx).y2, boundingBox_.at(last).y2);
//转换成了两个边界框相交区域的边长
maxX = ((minX-maxX+1)>0)? (minX-maxX+1) : 0;
maxY = ((minY-maxY+1)>0)? (minY-maxY+1) : 0;
//求交并比IOU
IOU = (maxX * maxY)/(boundingBox_.at(it_idx).area + boundingBox_.at(last).area - IOU);
if(IOU > overlap_threshold){
it = vScores.erase(it); //删除交并比大于阈值的候选框,erase返回删除元素的下一个元素
}else{
it++;
}
}
}
vPick.resize(nPick);
vector<Bbox> tmp_;
tmp_.resize(nPick);
for(int i = 0; i < nPick; i++){
tmp_[i] = boundingBox_[vPick[i]];
}
boundingBox_ = tmp_;
}
其中代码中有一个地方的设计很巧妙值得注意,while循环中,先确定最大的score后,让所有候选框都跟这个候选框计算交并比(包括自己),这样删除了交并比大于阈值的所有候选框,包括自己,这样就可以重复进行循环获得最终的候选框。
对于Bounding Box的列表B及其对应的置信度S,采用下面的计算方式.选择具有最大score的检测框M,将其从B集合中移除并加入到最终的检测结果D中.通常将B中剩余检测框中与M的IoU大于阈值Nt的框从B中移除.重复这个过程,直到B为空。
---------------------
原文:https://blog.csdn.net/krais_wk/article/details/80938752