最近看了吴恩达老师的深度学习课程,又看了python深度学习这本书,对深度学习有了大概的了解,但是在实战的时候,
还是会有一些细枝末节没有完全弄懂,这篇文章就用来总结一下用keras实现深度学习算法的时候一些我自己很容易搞错的点。
一、与序列文本有关
1.keras的Embedding层【Embedding层只能作为模型的第一层】
keras.layers.embeddings.Embedding( input_dim, #大或等于0的整数,字典长度,即输入数据最大下标+1 output_dim, #大于0的整数,代表全连接嵌入的维度 embeddings_initializer='uniform', #嵌入矩阵的初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
embeddings_regularizer=None, #嵌入矩阵的正则项,为Regularizer对象
activity_regularizer=None,
embeddings_constraint=None, #嵌入矩阵的约束项,为Constraints对象
mask_zero=False, #布尔值,确定是否将输入中的‘0’看作是应该被忽略的‘填充’(padding)值,该参数在使用递归层处理变长输入时有用。设置为True的话,
模型中后续的层必须都支持masking,否则会抛出异常。如果该值为True,则下标0在字典中不可用,input_dim应设置为|vocabulary| + 2。 input_length=None #当输入序列的长度固定时,该值为其长度。如果要在该层后接Flatten层,然后接Dense层,
则必须指定该参数,否则Dense层的输出维度无法自动推断。
)
输入 (samples,sequence_length)的2D张量
输出 (samples, sequence_length, output_dim)的3D张量
嵌入层将正整数(下标)转换为具有固定大小的向量,如[[4],[20]]->[[0.25,0.1],[0.6,-0.2]]
[[4],[20]]表示一句话由两个单词组成,第一个单词在词向量的位置为4,第二个单词位置为20
而位置为4的单词,对应的二维词向量就是[0.25,0.1];类似,位置为20的单词的词向量为[0.6,-0.2]
下面简单描述一下:
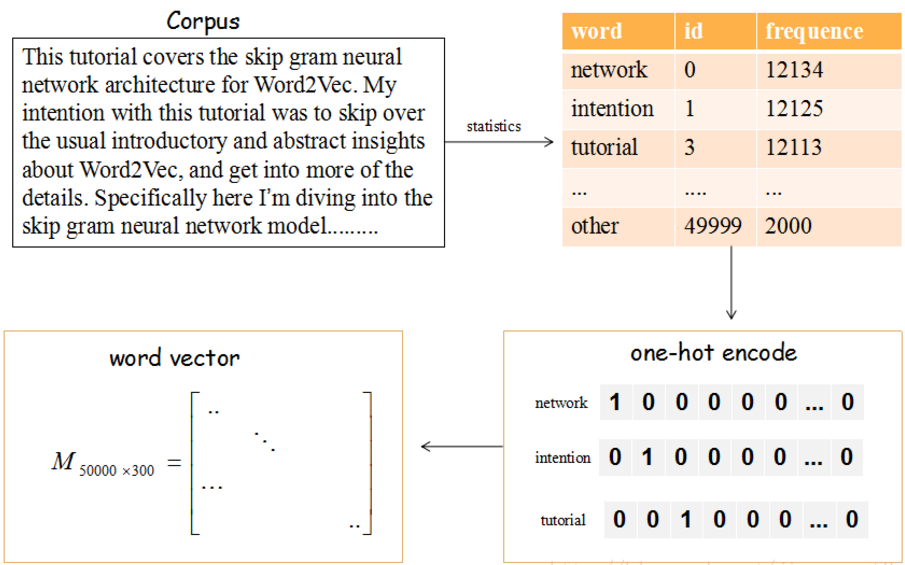
上图的流程是把文章的单词使用词向量来表示。
(1)提取文章所有的单词,把其按其出现的次数降序(这里只取前50000个),比如单词‘network’出现的次数最多,编号ID为0,依次类推…
(2)每个编号ID都可以使用50000维的二进制(one-hot)表示
(3)最后,我们会生产一个矩阵M,行大小为词的个数50000,列大小为词向量的维度(通常取128或300),比如矩阵的第一行就是编号ID=0,即network对应的词向量。
那这个矩阵M怎么获得呢?在Skip-Gram 模型中,我们会随机初始化它,然后使用神经网络来训练这个权重矩阵
2.在Keras模型中使用预训练的词向量
首先拿到一段文本,要想通过该文本完成分类或其他的任务,就必须要把这个文本转成词向量的形式。
先对训练集进行按行切分(或者,已经有一个所有句子的列表了),然后找到单词数最大的那行作为max_len,这个待会要输入模型中的
对于没达到max_len的句子,可以通过把句子给扩充为max_len长度
import keras.preprocessing.sequence import pad_sequences pad_sequences(sequences,maxlen=max_len)
然后得到每行单词对应的词向量,现在所有行的维度应该是(行数,单词数最多的那行对应的单词个数,每个单词词向量的维度)
模型的输入是(一批多少序列batch,输入长度input_length)
word index不超过999,词向量的个数上限值10000
输出是(None,10,64) None表示batch的维度(个数),64是每个单词的词向量的维度
model = Sequential() model.add(Embedding(1000, 64, input_length=10))
input_array = np.random.randint(1000, size=(32, 10))#32句话,每句话10个单词
model.compile('rmsprop', 'mse')
output_array = model.predict(input_array)
assert output_array.shape == (32, 10, 64) #32句话,每句话10个单词,每个单词有64维的词向量
二、与图片数据有关
参考文献