近日在写一个统计项目中C/CPP/H/CC/HPP文件(C/C++代码文件后缀名)的小程序。目标是给定一个项目代码所在文件夹,统计出总代码行数、有效代码行数、注释行数、空白行数。
其中:总代码行数 =(有效代码行数+注释行数+空白行数)
每找到一个目标代码文件,就创建任务投进线程池里,运行速度很快,不过统计结果偶有不准。程序跟踪下来,碰到类似下面的多种注释风格混用以及嵌套注释的代码很难正确处理。
1 std::string comment_test = R"({ 2 // comment /* with nested comment */ 3 "a": 1, 4 // comment 5 // continued 6 "b": "text", 7 /* multi 8 line 9 comment 10 // line-comment-inside-multiline-comment 11 */ 12 // and single-line comment 13 // and single-line comment /* multiline inside single line */ 14 "c": [1, 2, 3] 15 // and single-line comment at end of object 16 })";
conmment_test里存的是原始字符串,实际上存放的内容是
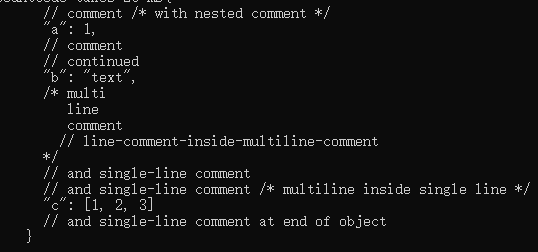
就是说里面的// 和/* */注释符号不能被当成注释符号纳入统计。但如何识别出原始字符串,找出字符串头尾,比较困难。有人会问了,这不是很明显嘛,R"()",括号里放的就是原始字符串内容。问题在于这段代码是单独拿出来的,一旦放在代码文件复杂的上下文中,就不容易识别了。
以前看过一篇文章,讲注释只能用//,而不要用/* */,更不要用嵌套的/* */,这会让文本分析程序无从下手,总算是有体会了! 如果注释用//开头,非常容易就识别该行代码就是注释了。
写这个小程序时,遇到几个坑,在这里记下来
1. windows 控制台程序输入路径时,路径不能包含空格,不然cmd被把空格前后内容当作不同的参数,解决办法路径用双引号包含起来
2.windows控制台程序中文乱码问题,工程设置是unicode,程序打印的文件路径含中文,而控制台默认代码页是936,GBK,开发环境和输出环境编码不一致,所以会乱码。
解决方法使用就是setlocale(LC_CTYPE, "");