不久将要参加个什么大数据比赛。 于是将相关的内容练习了几遍。 其中各自的关键及相关的理解均写成了笔记,分别是zookeeper分布式集群环境的搭建,hadoop集群环境的搭建,分布式非关系型数据库hbase环境搭建,基于hive的数据仓库的构建 以及于此同时回顾的计算机网络的相关知识。 短期来看,似乎有点浪费时间,做了一些无用功。 无论参加比赛获奖与否。 但是长期来看,还是很有益处的,不说大数据这种对普通开发人员不着调的话题,单单是计算机网络的相关理论知识,足够抵过很多的所谓实践了。 不管怎样,既然做了,那就尽量做好吧,希望能够做到问心无愧就好。 因此还是决定将知识总体拉通在复习一遍,并且将数据仓库中的数据分析部分给补上(笔记已经整理在电脑中,为防止误删数据,还是滕到博客上比较好! 上次清理桌面莫名其妙将自己数个月起早贪黑整理的笔记,以及整理的英语笔记都给弄丢了。 还好其中重要的都给写到了博客里,丢失了部分劳动成果,马勒戈壁的)。
先看看各个组件的启动方式,以及启动成功后,各自启动了哪些进程:(这实际上是最容易理解的,比很多的理论知识要来的直接的多):



当在集群环境下,这些进程都启动正常的话,那么基本可以判定这个集群是正确可用的了。
接着是hive的相关操作:
1.创建数据库:
![]() 、
、

2.建立数据表

Or


语法规则:



注意为了正确的装载,需要将爬取到的内容中的 ,(逗号)以及 \n(换行符号转义)
修改mysql 的默认编码:
![]()

![]()
修改配置,使得centos支持显示中文:

若没有,则要下载:
![]()



注意,以上的所有设置对centos的默认字符界面是不会生效的,只能用外置的命令行。。。
将需要检索的结果进行分表:



统计:




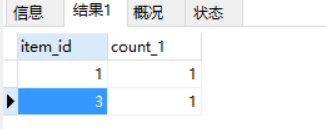
继续统计:
![]()
转换率计算:


针对竞赛的解决方案:(统计总帖子数)
![]()
![]()

2,统计总用户数:
![]()