6.1 获取社交网络数据的途径
6.1.1 电子邮件
我们可以通过分析用户的联系人列表了解用户的好友信息,而且可以进一步通过研究两个用户之间的邮件往来频繁程度度量两个用户的熟悉程度。
如果我们获得了用户的邮箱,也可以通过邮箱后缀得到一定的社交关系信息。很多社交网站都在用户注册时提供了让用户从电子邮件联系人中导入好友关系的功能,用以解决社交网络的冷启动问题。
6.1.2 用户注册信息
有些网站需要用户在注册时填写一些诸如公司、学校等信息。这也是一种隐性的社交网络数据。
6.1.3 用户的位置数据
在网页上最容易拿到的用户位置信息就是IP地址。对于手机等移动设备,我们可以拿到更详细的GPS数据。位置信息也是一种反映用户社交关系的数据。
6.1.4 论坛和讨论组
如果两个用户同时加入了很多不同的小组,我们可以认为这两个用户很可能互相了解或者具有相似的兴趣。如果两个用户在讨论组中曾经就某一个帖子共同进行过讨论,那就更加说明他们之间的熟悉程度或兴趣相似度很高。
6.1.5 即时聊天工具
和电子邮件系统一样,用户在即时聊天工具上也会有一个联系人列表,而且往往还会给联系人进行分组。通过这个列表和分组信息,我们就可以知道用户的社交网络关系,而通过统计用户之间聊天的频繁程度,可以度量出用户之间的熟悉程度。
6.1.6 社交网站
个性化推荐系统可以利用社交网站公开的用户社交网络和行为数据,辅助用户更好地完成信息过滤的任务,更好地找到和自己兴趣相似的好友,更快地找到自己感兴趣的内容。
1. 社会图谱和兴趣图谱
Facebook和Twitter作为社交网站中的两个代表,它们其实代表了不同的社交网络结构。在Facebook里,人们的好友一般都是自己在现实社会中认识的人,而且Facebook中的好友关系是需要双方确认的。在Twitter里,人们的好友往往都是现实中自己不认识的,而只是出于对对方言论的兴趣而建立好友关系,好友关系也是单向的关注关系。以Facebook为代表的社交网络称为社交图谱(social graph),而以Twitter为代表的社交网络称为兴趣图谱(interest graph)。
但是,每个社会化网站都不是单纯的社交图谱或者兴趣图谱。
6.2 社交网络数据简介
社交网络定义了用户之间的联系,因此可以用图定义社交网络。我们用图G(V,E,w)定义一个社交网络,其中V是顶点集合,每个顶点代表一个用户,E是边集合,如果用户和
有社交网络关系,那么就有一条边
连接这两个用户,而
定义了边的权重。业界有两种著名的社交网络。一种以Facebook为代表,它的朋友关系是需要双向确认的,因此在这种社交网络上可以用无向边连接有社交网络关系的用户。另一种以Twitter为代表,它的朋友关系是单向的,因此可以用有向边代表这种社交网络上的用户关系。
此外,对图G中的用户顶点u,定义out(u)为顶点u指向的顶点集合(如果套用微博中的术语,out(u)就是用户u关注的用户集合),定义in(u)为指向顶点u的顶点集合(也就是关注用户u的用户集合)。那么,在Facebook这种无向社交网络中显然有out(u)=in(u)。
一般来说,有3种不同的社交网络数据。
双向确认的社交网络数据,这种社交网络一般可以通过无向图表示。
单向关注的社交网络数据,这种社交网络中的用户关系是单向的,可以通过有向图表示。
基于社区的社交网络数据,这种社交网络数据,用户之间并没有明确的关系,但是这种数据包含了用户属于不同社区的数据。
社交网络数据中的长尾分布
社交网络中用户的入度(in degree)和出度(out degree)的分布也是满足长尾分布的。
用户的入度反映了用户的社会影响力。用户的入度近似长尾分布,这说明在一个社交网络中影响力大的用户总是占少数。
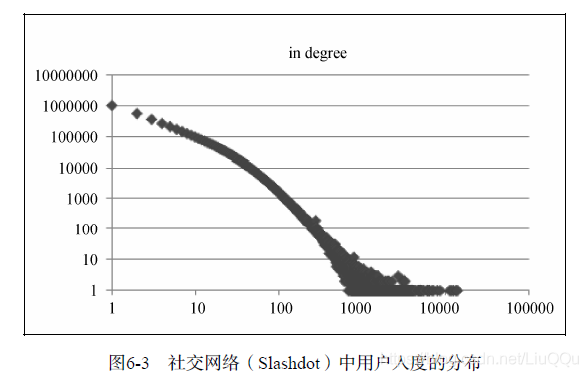
出度代表了一个用户关注的用户数,该图说明在一个社交网络中,关注很多人的用户占少数,而绝大多数用户只关注很少的人。

6.3 基于社交网络的推荐
很多网站都利用Facebook的社交网络数据给用户提供社会化推荐。
社会化推荐之所以受到很多网站的重视,是缘于如下优点。
(1)好友推荐可以增加推荐的信任度
(2)社交网络可以解决冷启动问题
社会化推荐也有一些缺点,其中最主要的就是很多时候并不一定能提高推荐算法的离线精度(准确率和召回率)。特别是在基于社交图谱数据的推荐系统中,因为用户的好友关系不是基于共同兴趣产生的,所以用户好友的兴趣往往和用户的兴趣并不一致。
6.3.1 基于邻域的社会化推荐算法
如果给定一个社交网络和一份用户行为数据集。其中社交网络定义了用户之间的好友关系,而用户行为数据集定义了不同用户的历史行为和兴趣数据。那么我们想到的最简单算法是给用户推荐好友喜欢的物品集合。即用户u对物品i的兴趣pui可以通过如下公式计算。
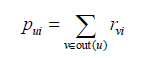 ,其中out(u)是用户u的好友集合,如果用户v喜欢物品i,则
,其中out(u)是用户u的好友集合,如果用户v喜欢物品i,则=1,否则
=0。
不过,即使都是用户u的好友,不同的好友和用户u的熟悉程度和兴趣相似度也是不同的。因此,我们应该在推荐算法中考虑好友和用户的熟悉程度以及兴趣相似度:
![]() ,这里,
,这里, 由两部分相似度构成,一部分是用户u和用户v的熟悉程度,另一部分是用户u和用户v的兴趣相似度。
用户u和用户v的熟悉程度(familiarity)描述了用户u和用户v在现实社会中的熟悉程度。熟悉度可以用用户之间的共同好友比例来度量。

在度量用户相似度时还需要考虑兴趣相似度(similarity),而兴趣相似度可以通过和UserCF类似的方法度量,即如果两个用户喜欢的物品集合重合度很高,两个用户的兴趣相似度很高。
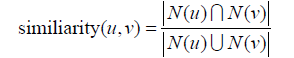 ,其中N(u)是用户u喜欢的物品集合。
,其中N(u)是用户u喜欢的物品集合。
def Recommend(uid, familiarity, similarity, train):
rank = dict()
interacted_items = train[uid]
for fid,fw in familiarity[uid]:
for item,pw in train[fid]:
# if user has already know the item
# do not recommend it
if item in interacted_items:
continue
addToDict(rank, item, fw * pw)
for vid,sw in similarity[uid]:
for item,pw in train[vid]:
if item in interacted_items:
continue
addToDict(rank, item, sw * pw)
return rank6.3.2 基于图的社会化推荐算法
用户的社交网络可以表示为社交网络图,用户对物品的行为可以表示为用户物品二分图,而这两种图可以结合成一个图。图上
有用户顶点(圆圈)和物品顶点(方块)两种顶点。如果用户u对物品i产生过行为,那么两个节点之间就有边相连。比如该图中用户A对物品a、e产生过行为。如果用户u和用户v是好友,那么也会有一条边连接这两个用户,比如该图中用户A就和用户B、D是好友。

在定义完图中的顶点和边后,需要定义边的权重。其中用户和用户之间边的权重可以定义为用户之间相似度的倍(包括熟悉程度和兴趣相似度),而用户和物品之间的权重可以定义为用户对物品喜欢程度的
倍。
和
需要根据应用的需求确定。如果我们希望用户好友的行为对推荐结果产生比较大的影响,那么就可以选择比较大的
。相反,如果我们希望用户的历史行为对推荐结果产生比较大的影响,就可以选择比较大的
。
在定义完图中的顶点、边和边的权重后,我们就可以利用前面几章提到的PersonalRank图排序算法给每个用户生成推荐结果。
在社交网络中,除了常见的、用户和用户之间直接的社交网络关系(friendship),还有一种关系,即两个用户属于同一个社群(membership)。如果要在前面提到的基于邻域的社会化推荐算法中考虑membership的社交关系,可以利用两个用户加入的社区重合度计算用户相似度,然后给用户推荐和他相似的用户喜欢的物品。但是,如果利用图模型,我们就很容易同时对friendship和membership建模。如图6-8所示,可以加入一种节点表示社群(最左边一列的节点),而如果用户属于某一社群,图中就有一条边联系用户对应的节点和社群对应的节点。在建立完图模型后,我们就可以通过前面提到的基于图的推荐算法(比PersonalRank)给用户推荐物品。

6.3.3 实际系统中的社会化推荐算法
6.3.1节提出的基于邻域的社会化推荐算法看起来非常简单,但在实际系统中却是很难操作的,这主要是因为该算法需要拿到用户所有好友的历史行为数据,而这一操作在实际系统中是比较重的操作。
我们可以从几个方面改进基于邻域的社会化推荐算法,让它能够具有比较快的响应时间。改进的方向有两种,一种是可以做两处截断。第一处截断就是在拿用户好友集合时并不拿出用户所有的好友,而是只拿出和用户相似度最高的N个好友。这里N可以取一个比较小的数。从而给该用户做推荐时可以只查询N次用户历史行为接口。此外,在查询每个用户的历史行为时,可以只返回用户最近1个月的行为,这样就可以在用户行为缓存中缓存更多用户的历史行为数据,从而加快查询用户历史行为接口的速度。此外,还可以牺牲一定的实时性,降低缓存中用户行为列表过期的频率。
而第二种解决方案需要重新设计数据库。
首先,为每个用户维护一个消息队列,用于存储他的推荐列表;
当一个用户喜欢一个物品时,就将(物品ID、用户ID和时间)这条记录写入关注该用户的推荐列表消息队列中;
当用户访问推荐系统时,读出他的推荐列表消息队列,对于这个消息队列中的每个物品,重新计算该物品的权重。计算权重时需要考虑物品在队列中出现的次数,物品对应的用户和当前用户的熟悉程度、物品的时间戳。同时,计算出每个物品被哪些好友喜欢过,用这些好友作为物品的推荐解释。
6.3.4 社会化推荐系统和协同过滤推荐系统
关于社会化推荐系统的离线评测可以参考Georg Groh和Christian Ehmig的工作成果(参见“Recommendations in Taste Related Domains: Collaborative Filtering vs. Social Filtering”,http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.165.3679&rep=rep1&type=pdf)。不过社会化推荐系统的效果往往很难通过离线实验评测,因为社会化推荐的优势不在于增加预测准确度,而是在于通过用户的好友增加用户对推荐结果的信任度,从而让用户单击那些很冷门的推荐结果。此外,很多社交网站(特别是基于社交图谱的社交网站)中具有好友关系的用户并不一定有相似的兴趣。因此,利用好友关系有时并不能增加离线评测的准确率和召回率。因此,很多研究人员利用用户调查和在线实验的方式评测社会化推荐系统。
对社会化推荐系统进行用户调查的代表性工作成果是Rashmi Sinha和Kirsten Swearingen对比社会化推荐系统和协同过滤推荐系统的论文(参见“Comparing Recommendations Made by Online Systems and Friends”,https://pdfs.semanticscholar.org/a239/9a7a0b39ade27f9edf605075f3fa3877e2c9.pdf)。
作者通过分析用户实验的过程和最终回答的调查问卷证明,社会化推荐系统推荐结果的用户满意度明显高于主要基于协同过滤算法的几个真实推荐系统。
6.3.5 信息流推荐
信息流推荐是社会化推荐领域的新兴话题,它主要针对Twitter和Facebook这两种社交网站。信息流的个性化推荐要解决的问题就是如何进一步帮助用户从信息墙上挑选有用的信息。
目前最流行的信息流推荐算法是Facebook的EdgeRank,该算法综合考虑了信息流中每个会话的时间、长度与用户兴趣的相似度。EdgeRank的主要思想参见“EdgeRank: The Secret Sauce That Makes Facebook’s News Feed Tick”,地址为http://techcrunch.com/2010/04/22/facebook-edgerank/。
Facebook将其他用户对当前用户信息流中的会话产生过行为的行为称为edge,而一条会话的权重定义为:

其中:
指产生行为的用户和当前用户的相似度,这里的相似度主要是在社交网络图中的熟悉度;
指行为的权重,这里的行为包括创建、评论、like(喜欢)、打标签等,不同的行为有不同的权重。
指时间衰减参数,越早的行为对权重的影响越低。
如果一个会话被你熟悉的好友最近产生过重要的行为,它就会有比较高的权重。
不过,EdgeRank算法的个性化因素仅仅是好友的熟悉度,它并没有考虑帖子内容和用户兴趣的相似度。所以EdgeRank仅仅考虑了“我”周围用户的社会化兴趣,而没有重视“我”个人的个性化兴趣。为此,GroupLens的研究人员Jilin Chen深入研究了信息流推荐中社会兴趣和个性化兴趣之间的关系。(参见“Speak Little and Well: Recommending Conversations in Online Social Streams”,https://dl.acm.org/citation.cfm?id=1978974)他们的排名算法考虑了如下因素。
会话的长度:越长的会话包括越多的信息。
话题相关性:度量了会话中主要话题和用户兴趣之间的相关性。这里Jilin Chen用了简单的TF-IDF建立用户历史兴趣的关键词向量和当前会话的关键词向量,然后用这两个向量的相似度度量话题相关性。
用户熟悉程度:主要度量了会话中涉及的用户(比如会话的创建者、讨论者等)和当前用户的熟悉程度。计算熟悉度的主要思想是考虑用户之间的共同好友数等。
他们设计了用户调查,让用户对如下5种算法的推荐结果给出1~5分的评分:
Random 给用户随机推荐会话。
Length 给用户推荐比较长的会话。
Topic 给用户推荐和他兴趣相关的会话。
Tie 给用户推荐和他熟悉的好友参与的会话。
Topic+Tie 综合考虑会话和用户的兴趣相关度以及用户好友参与会话的程度。
结果发现:
对于所有用户不同算法的平均得分是:Topic+Tie > Tie > Topic > Length > Random
而对于主要目的是寻找信息的用户,不同算法的得分是:Topic+Tie ≥ Topic > Length > Tie > Random
对于主要目的是交友的用户,不同算法的得分是:Topic+Tie > Tie > Topic > Length > Random
实验结果说明,综合考虑用户的社会兴趣和个人兴趣对于提高用户满意度是有帮助的。因此,当我们在一个社交网站中设计推荐系统时,可以综合考虑这两个因素,找到最合适的融合参数来融合用户的社会兴趣和个人兴趣,从而给用户提供最令他们满意的推荐结果。
6.4 给用户推荐好友
好友推荐系统的目的是根据用户现有的好友、用户的行为记录给用户推荐新的好友,从而增加整个社交网络的稠密程度和社交网站用户的活跃度。
好友推荐算法在社交网络上被称为链接预测(link prediction)。关于链接预测算法研究的代表文章是Jon Kleinberg的“Link Prediction in Social Network”(https://www.cs.cornell.edu/home/kleinber/link-pred.pdf)。
6.4.1 基于内容的匹配
我们可以给用户推荐和他们有相似内容属性的用户作为好友。下面给出了常用的内容属性。
用户人口统计学属性,包括年龄、性别、职业、毕业学校和工作单位等。
用户的兴趣,包括用户喜欢的物品和发布过的言论等。
用户的位置信息,包括用户的住址、IP地址和邮编等。
利用内容信息计算用户的相似度和我们前面讨论的利用内容信息计算物品的相似度类似。
6.4.2 基于共同兴趣的好友推荐
如果用户喜欢相同的物品,则说明他们具有相似的兴趣。
此外,也可以根据用户在社交网络中的发言提取用户的兴趣标签,来计算用户的兴趣相似度。
6.4.3 基于社交网络图的好友推荐
最简单的好友推荐算法是给用户推荐好友的好友。
基于好友的好友推荐算法可以用来给用户推荐他们在现实社会中互相熟悉,而在当前社交网络中没有联系的其他用户。
对于用户u和用户v,我们可以用共同好友比例计算他们的相似度:
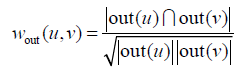
公式中out(u)是在社交网络图中用户u指向的其他好友的集合。我们也可以定义in(u)是在社交网络图中指向用户u的用户的集合。在无向社交网络图中,out(u)和in(u)是相同的集合。但在微博这种有向社交网络中,这两个集合就不同了,因此也可以通过in(u)定义另一种相似度:

越大表示用户u和v关注的用户集合重合度越大,而
越大表示关注用户u和关注用户v的用户的集合重合度越大。
同时,我们还可以定义第三种有向的相似度:
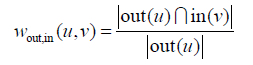
这个相似度的含义是用户u关注的用户中,有多大比例也关注了用户v。但是,这个相似度有一个缺点,就是在该相似度的定义下所有人都和名人有很大的相似度。这是因为这个相似度在分母的部分没有考虑|in(v)|的大小。因此,我们可以用如下公式改进上面的相似度:

离线实验
斯坦福大学的大规模网络数据集(http://snap.stanford.edu/data/),该数据集包含很多链接结构数据集,包括社交网络数据集、互联网超级链接数据集、道路交通网络、用户行为网络、论文引用网络等。这里,我们使用该集合中提供的Slashdot社交网络数据集。该数据集是一个有向图,包含82 168个顶点和948 464条边。
为了测试不同好友推荐算法的性能,本节将数据集按照9:1分成训练集和测试集。然后,给定用户u,我们会利用训练集中的社交网络给用户生成长度为10的好友推荐列表R(u),其中R(u)中的用户不包含用户u在训练集中的好友。

不同数据集上不同算法的性能并不相同。所以,在实际系统中我们需要在自己的数据集上对比不同的算法,找到最适合自己数据集的好友推荐算法。
6.4.4 基于用户调查的好友推荐算法对比
通过用户调查对比了不同算法的用户满意度(参见“‘Make New Friends, but Keep the Old’ - Recommending People on Social Networking Site”),其中算法如下。
InterestBased 给用户推荐和他兴趣相似的其他用户作为好友。
SocialBased 基于社交网络给用户推荐他好友的好友作为好友。
Interest+Social 将InterestBased算法推荐的好友和SocialBased算法推荐的好友按照一定权重融合。
SONA SONA是IBM内部的推荐算法,该算法利用大量用户信息建立了IBM员工之间的社交网络。这些信息包括所在的部门、共同发表的文章、共同写的Wiki、IBM的内部社交网络信息、共同合作的专利等。
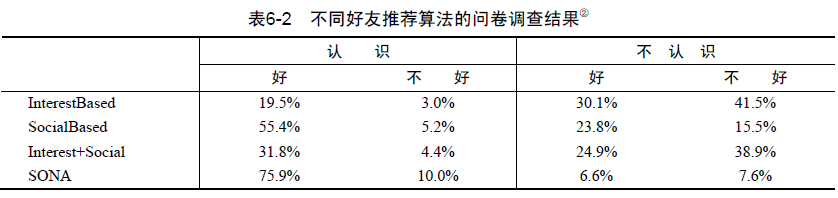
从结果可以发现,对推荐结果的新颖性不同算法的排名如下:InterestBased > Interest+Social > SocialBased > SONA
其次,结果表明如果用户认识推荐结果中的人,那么绝大部分用户都会觉得这是一个好的推荐结果,而如果用户不认识推荐结果中的人,绝大多数人都觉得推荐结果不好。
从用户认为推荐结果是否好的比例看,不同算法的排名如下:SONA > SocialBased > Interest+Social > InterestBased
6.5 扩展阅读
关于社交网络最让人耳熟能详的结论就是六度原理。六度原理讲的是社会中任意两个人都可以通过不超过6个人的路径相互认识,如果转化为图的术语,就是社交网络图的直径为6。六度原理在均匀随机图上已经得到了完美证明,对此感兴趣的读者可以参考《Random Graph》一书。很多对社交网络的研究都是基于随机图理论的,因此深入研究社交网络必须掌握随机图理论的相关知识。
社交网络研究中有两个最著名的问题。第一个是如何度量人的重要性,也就是社交网络顶点的中心度(centrality),第二个问题是如何度量社交网络中人和人之间的关系,也就是链接预测。对这两个问题感兴趣的读者可以参考社交网络分析方面的书,比如《Social Network Analysis: Methods and Applications》和《Social Network Analysis: A Handbook》。