学习一项技术最重要的是要理解它能解决什么问题,那么学习大数据可以解决什么问题呢?
一、大数据可以解决什么问题?
-
场景一:电商网站要把过去一个月或一年卖的好的商品放到首页推荐给用户。
问题1:过去一个月或者一年的订单数量是巨大的,如何存储?
问题2:假设已经找到存储的方案了,那么大量的订单如何计算? -
场景二:天气预报需要根据过去一年或者十年的天气状况预测明天或者下个周的天气状况。
问题1:过去一年或者十年的天气状况信息是巨大的,如何存储?
问题2:假设已经解决了存储的问题,那么近十年的天气状况数据要如何计算?
没错,大数据可以解决海量数据的存储和计算这两个问题。
- 海量数据的存储是使用分布式存储(HDFS)
- 海量数据的计算是使用分布式计算(MapReduce)
Hadoop则是集成了分布式存储和分布式计算这两种功能的一种大数据的解决方案。
二、Hadoop
-
Hadoop 的 HDFS(Hadoop Distributed File System ,Hadoop分布式文件系统)解决了数据的分布式存储。
-
Hadoop 的 MapReduce 计算模型解决了数据的分布式计算。
-
Hadoop也可以看成是数据仓库的一种实现方式。
数据库:服务于业务功能,主要用于增删改查。
数据仓库:服务于系统分析师,主要用于查询。 -
Hadoop (数据仓库)中的数据来自于哪里呢?
关系型数据库,日志,其他数据…
-
那么我们如何将这么多不同类型的数据存储到 Hadoop 的 HDFS 中呢?
通过ETL(Extract-抽取,Transfer-转换,Load-加载)的方式,就像我们在一些招聘网站上看到的一样:

-
ETL还只是一个概念,那么具体要用什么技术进行数据的采集,清洗呢?
需要用到数据采集引擎,如下两种:
Sqoop:主要用来采集关系型数据库。
Flume:主要用来采集日志。 -
采集到的数据存储到Hadoop的哪一部分呢?
- 可以是上面提到的HDFS
- 也可以是HBase(基于Hadoop的一个No-SQL数据库)
- 当然也可以是Hive(一个数据分析引擎,另外一个比较常见的数据分析引擎是Pig)
-
那么如何处理这些海量的数据呢?
- 使用 Hadoop 中的 MapReduce 程序。
- 使用另一个类似Hadoop的大数据处理框架Spark。
-
当然处理后的数据仍然是存储在HDFS,HBase,Hive中。
-
这么多的组件,如何协调它们的运行呢?
使用 ZooKeeper、HUE。 -
最终将不同类型的数据提供给不同的人使用。
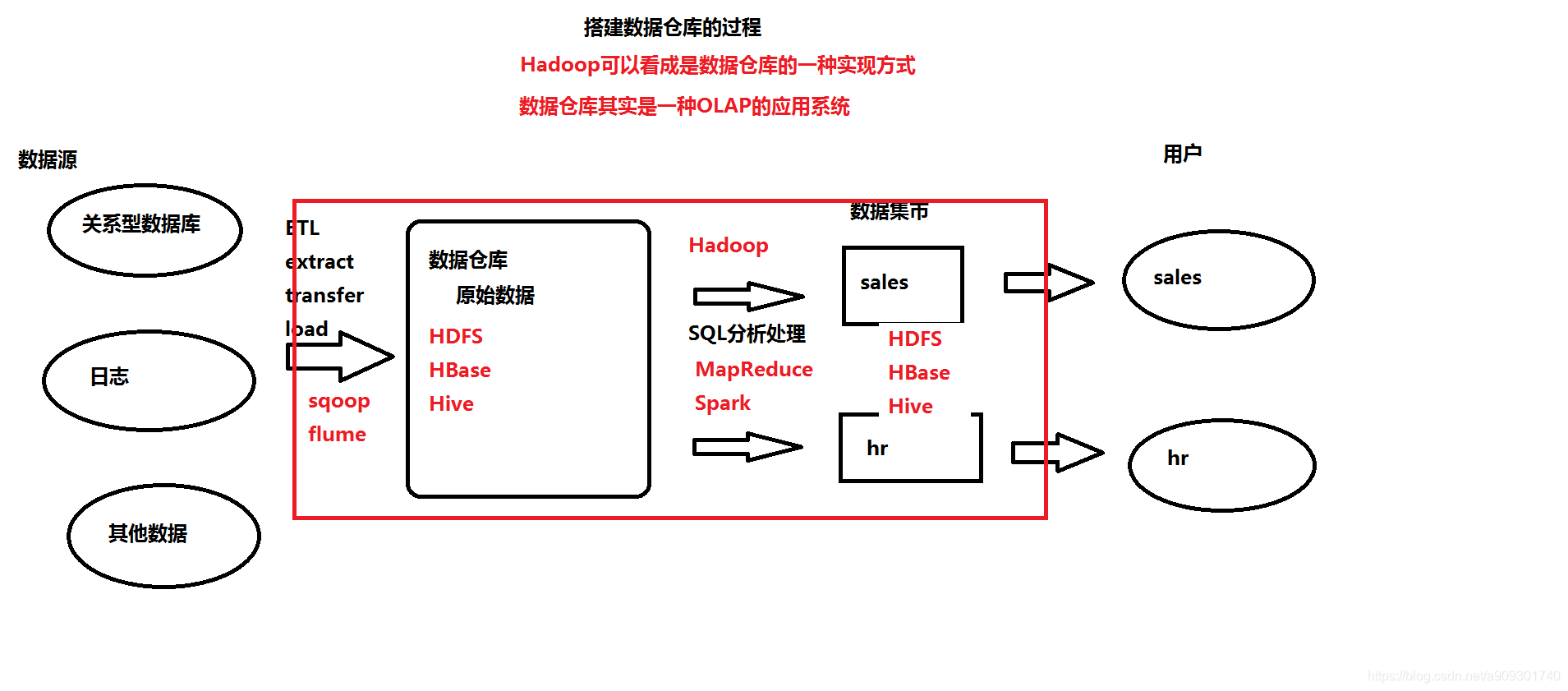
红框框住的部分就是Hadoop的一些组件(Spark除外)。- HDFS:Hadoop分布式文件系统
- MapReduce:Java程序,用于分布式计算,并且是运行在 Yarn 平台。
- Yarn:就像 Tomcat 一样,也是一个运行程序的容器,不同的是 Yarn 中运行的是 MapReduce 程序,Tomcat 中运行的是 servlet 程序。
- Hbase:一个NoSQL数据库。
- Sqoop、Flume:数据采集引擎。
- Hive、Pig:数据分析引擎。
- ZooKeeper、HUE:是协调管理工具,管理图中不同组件之间的调度。
三、Storm
实时计算框架,用来处理流式数据。
- NoSQL数据库:Redis
- Apache Storm
四、Spark
类似 Hadoop 的一个基于内存的大数据处理框架。
- Sclala编程语言(基于Java)
- Spark Core:内核(最重要的内容) ----> 相当于 Hadoop 的MapReduce
- Spark SQL:相当于 Hadoop 的 Hive、Pig 是数据分析引擎,支持SQL
- Spark Streaming:相当于 Storm,也是一个实时计算框架,用来处理流式数据。