
1相似度分析
相似性度量准则是聚类分析用来度量数据之间差异化的一个重要标准。聚类分析中数
据之间相似程度较大,需要按照某种聚类准则进行分离数据。在这样的一个过程中,需要
使用相似性度量来衡量数据之间的相似及不同。在相似性度量中,距离度量是最常使用的
一个准则,用来衡量数据之间的差异性,一般而言,距离越近的数据相似性越高,距离越
远的数据相似性越低。
(1)绝对值距离

(2)欧氏距离
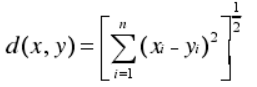
(3)明科夫斯基距离
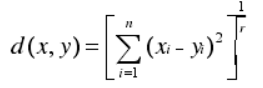
(4)余弦距离
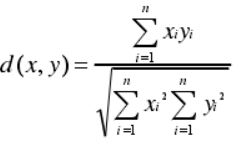

2聚类算法的分类
不同的问题我们可以尝试一种或几种不同的聚类算法来处理数据集,并观察数据集的处理结果,可以分析出不用的聚类算法的优点以及缺陷。主要的聚类算法可以大致划分成如下几类:基于层次聚类、基于划分聚类、基于密度聚类、基于模糊聚类、基于网格聚类。

(1)划分聚类的方法
基于划分聚类的方法,简单来说,大量的数据在一起,你需要将这里混合在一起的数
据分离开来,让其达到聚类效果。首先你需要明确划分成几类数据集,然后需要在这些杂
乱的数据中选取初始中心点,依据事先规定好的算法,将数据按照一定规则,聚集在中心
点附近。一个好的划分聚类算法有如下判断方式:“类内的点都足够近,类间的点都足够远”,
简单意思就是同类的数据他么之间的距离尽可能的近,不同类的数据它们之间的距离尽可
能的远。也可以用阐述成,同类中的数据尽可能的相似,而不同的的数据之间有较大的差
异。
最常用的,K-means算法流程如下:
基于划分聚类算法中,K-means 算法算是比较经典的算法,这也是本文在后续实验部
分所采用的算法。由于该算法简单、收敛速度快、效率高,被广泛的应用于各个领域中,
并且许多算法也是围绕该聚类算法改进和优化。
对于给定的 n 个对象的数据集,K-means 算法会以 k 为参数,将其划分成 k 个簇,聚
类后的结果为k 个聚类中心。相同簇内数据集相似度较高,不同簇之间的数据相似度较低。
该算法的流程过程如下:
1)给定指定的样本数据集,从数据集中随机的选择k 个初始点作为聚类中心,求解聚
类中心公式如下所示:

上述公式中Ci 为第i 个簇,ni 为Ci 中含的样本个数,x 为Ci 中的样本。
2)计算剩余数据到聚类中心的距离,如若满足距离公式要求的标准,则将该数据归于
此聚类簇中。求解距离公式如下:


3)根据划分后的数据集点重新计算新的聚类中心。
4)判断新的聚类中心和上一个聚类中心是否有差距,如果有,则继续操作步骤三,没
有,输出聚类划分结果。
(2)层次聚类的方法
基于层次聚类的方式是对数据集合进行层次上的分解。其原理是对数据点中最为相似
的两个数据点进行分组,并且反复这一操作,最终会形成一个层次分明的聚类树。层次聚
类方法可以分为自下而上合并(凝聚)方法,自下而上分裂方法。凝聚方法原理为将数据
集中的每个对象作为一个簇,然后合并这些簇成为一个新的簇,周而复始,直到达到终止
条件,形成一个自下而上的聚类树。分裂方法原理是数据集中的所有对象为一个簇,然后
细分化成一个个新的簇,直到满足终止条件,形成一个自上而下的聚类树。采用层次聚类
的算法主要有自下而上聚类AGNES 算法,自上而下聚类DIANA 算法。
凝聚层次聚类算法 :
基于层次聚类的方式是对数据集合进行层次上的分解。其原理是对数据集中最为相似
的两个数据点进行分组,并且反复这一操作,最终会形成一个层次分明的聚类树。层次聚
类方法可以分为自下而上合并方法,自下而上分裂方法。这里介绍凝聚层次聚类算法。
该算法的原理是将将所有数据中的对象作为一个簇,紧接着,合并相似的簇,成为一
个新的簇,直到满足条件,终止操作。大多数的层次聚类算法都是属于凝聚型的,只不过
在定义簇间相似度上有所不同。有如下几种被广泛采用度量簇间距离的公式: 
凝聚层次聚类算法流程如下所示:
1) 将数据集中每个对象看作一类,计算两两对象之间的最小距离;
2) 合并距离最小的两个对象成为一个新的类;
3) 在重新计算合并后新类之间的距离。
4) 直到所有类最后合并成一类或达到终止条件,否则重复(2)、(3)过程,
(3)密度聚类
密度聚类方法的核心思想是某个点附近区域的数据超过一定的阈值,则可以表示该点
是一个核心区域点,位于簇的内部。例如,通过卫星地图我们可以发现,夜晚的地球是存
在许许多多的灯光源,有的灯光源密度大,灯源亮,有的灯光源密度小,灯源较暗。因此,
我们可以通过灯源的亮暗来区分城市和乡村,也可以灯源的密度大小来区分城市的大小。
经典的密度聚类算法则是 DBSCAN 算法,该算法可以将高密度的数据集划分为簇,并且
可以在有噪声的情况下发现任意形状的簇类,可以理解为对噪声不敏感。
(4)网格聚类方法
基于网格聚类方法原理是采用空间驱动,将空间中的数据划分成一个个小的网格,从
而形成一个网格结构。因为其网格的特性,所有的聚类都在网格上进行,加快了聚类操作
的速度,但由于每个网格的操作可能都不同,所以也会导致准确度的下降。
SOM 聚类算法
SOM(Self Organizing Maps)是一种基于神经网络的聚类算法,是一种无监督式的学习算
法。该算法的特点是隐藏的节点是具有拓扑关系的,而这些拓扑关系需要我们去确定,如
果想到一维模型,需要将这些节点连在一起,成为一条线。如果想要二维的拓扑关系图,
则需要将这些节点映射称一个平面[30]。
SOM 聚类算法包含输入和输出层。输入层用于接受外界的消息,输出层则是由二维网
格中的节点构成,而输入层和输出层通过权重向量连接。训练时,采用竞争学习方式,找
出节点之间的最短距离输出单元。
SOM 聚类算法流程如下:
1) 初始化网络,对输入层的节点初始化参数;
2) 从输入样本中随机挑选输入向量,找到与之相匹配的节点,距离函可采用欧几里德
距离公式;
3) 定义获胜单元,跟新临近节点;
4) 提供新样本、进行训练;
5) 更新节点参数、重复,直到满足终止条件,输出聚类结果。
(5)模糊聚类方法:
实际上,并不是所有的数据都有一个特定的界限,有些数据之间的关系本就是模糊不
清的。例如对于冷热的描述,不同的人对冷热有着不同的看法,数据关系也是一样。因此,
模糊聚类主要为了解决此种类型的数据。其核心原理是使用模糊数学语言对数据进行一个
模糊量化,让数据按照这样的准则进行聚类,使得类之间数据的差异尽可能的大,类中的
数据差异尽可能的小。基于模糊聚类的方法主要是FCM 算法。
FCM 聚类算法
FCM聚类算法属于模糊集聚类算法,于1965年美国教授扎德提出模糊集合概念,经过
几十年的发展,模糊集合受到了广泛的应用。而FCM聚类算法也是建立在模糊集合而来,
是一种以隶属度来确定每个数据点,属于某个聚类程度的算法。
FCM聚类算法流程:
1)随机初始化数据矩阵A,初始化聚类中心,及距离;
2)计算聚类中心;
3)更新数据矩阵A;
4)查看是否满足结果,满足结束,没有重复步骤2;
5)根据结果,确定数据所属聚类中心,显示聚类结果。
来源: 吴雷明. 基于优化遗传算法的聚类分析研究[D].安徽理工大学,2018.