Map-side joins 是最有效的技术,前面的两种 map-side 策略都要求其中有一个数据集可被加载到内存。但是,如果两个数据集都很大且无法”瘦身”而无法做到这一点时,该怎么办?在这种情况下,如果满足以下条件,则可以使用复合的 map-side join:
-
两个数据集都无法整体加载到内存中.
-
两个数据集都按 join key 排好了序
-
每个数据集都有相同的文件数.
-
在每个数据集中的 File N 都包含相同的 join key K.
-
每个文件的大小都小于一个 HDFS block,这样分区时不会被 split者,或者用于该数据的 input split不会切分该文件。
下图显示了一个排序的和分区的文件的例子,这些文件可以用于复合连接。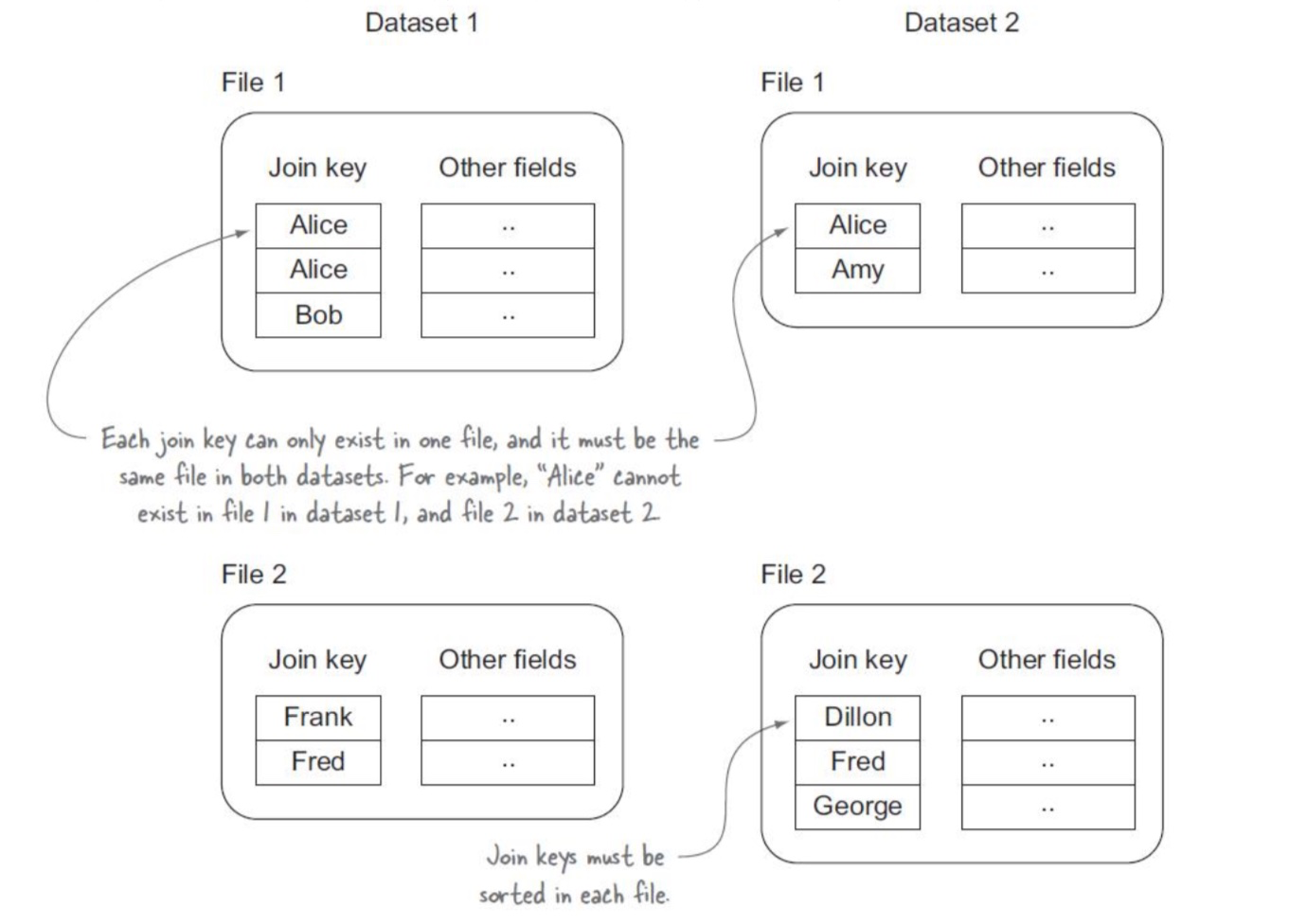
应用场景:
想要在排序的、分区的数据上执行一个 map-side join。解决方案:
使用 MapReduce 自带的 CompositeInputFormat。CompositeInputFormat 功能相当强大,并且支持内连接和外连接。