1 引言
scrapy处理爬取静态页面,可以说是很好的工具,但是随着技术的发展,现在很多页面都不再是静态页面了,都是通过AJAX异步加载数据动态生成的,我们如何去解决问题呢?今天给大家介绍一种方法:scrapy-splash
2 准备工作
首先需要安装一下几个工具
(1)docker
(2)scrapy-splash
因为这里我的操作系统是window,所以只给出window安装docker过程(Linux自行百度,安装很方便的)
1)下载docker toolbox并解压安装即可(下载地址:https://download.csdn.net/download/qq_38003892/10391403)
在这个过程中需要注意一下几个问题:
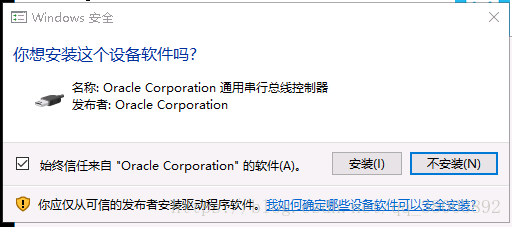
弹出这样的对话框点击安装即可
2)找到桌面上的Docker Quickstart Terminal打开,它会自动安装一些东西
3)修改pull源
注意:这里默认的pull源不是国内的,所以下载速度特别慢,这里可以通过国内的阿里云镜像库去下载,具体做法如下:
1 打开阿里云官网:https://www.aliyun.com/
2 登录->进入管理控制台
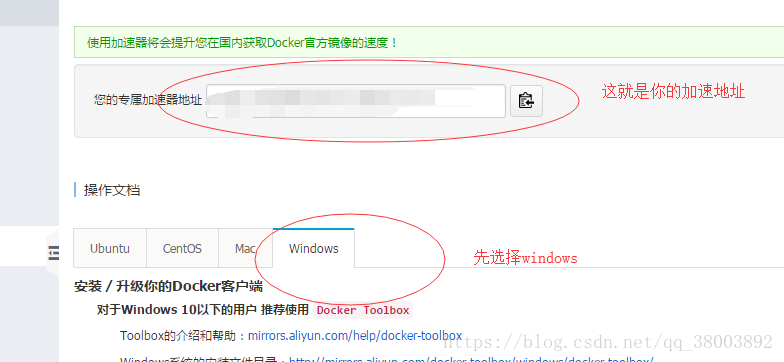
3 然后在docker 中输入 docker pull xxxxxx.mirror.aliyuncs.com/scrapinghub/splash
4 下载好之后开启splash 命令:docker run -p 8050:8050 scrapinghub/splash
5 然后在浏览器中输入
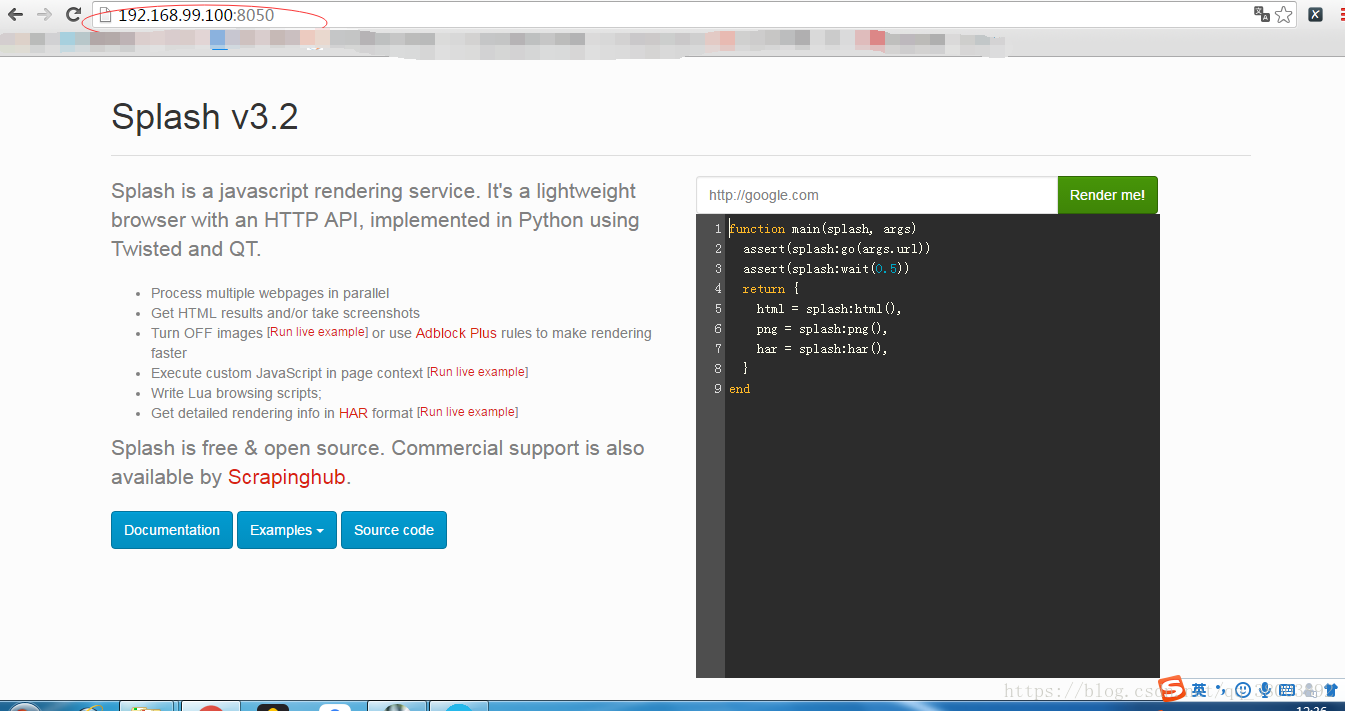
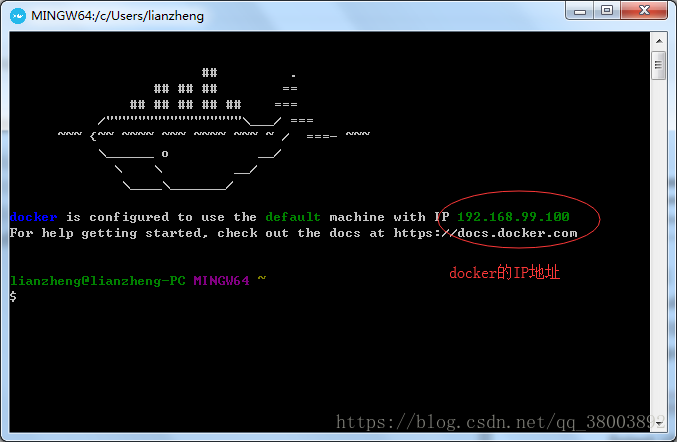
注意这里的网址 是 由你的docker IP地址决定的 端口号就是你运行splash的端口号(8050)
4)安装scrapy-splash
打开cmd 输入命令:pip install scrapy-splash
3 测试
1 创建爬虫项目(这里不多说了)
2 在settings.py中设置以下几项(若没有则添加):
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# 渲染服务的url
SPLASH_URL = 'http://192.168.99.100:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'3 创建spider,并编写
这里用这样一个例子,给大家说明
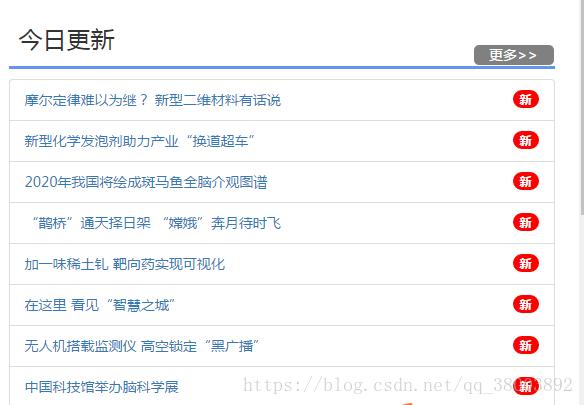
爬虫目标网站:http://39.104.87.35/findex/
爬取网站今日更新截图:
网页源码:

爬虫代码:
# -*- coding: utf-8 -*-
import scrapy
from scrapy_splash import SplashRequest
class TestSpider(scrapy.Spider):
name = 'test'
start_urls = ['http://39.104.87.35/findex/']
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url=url, callback=self.parse, args={'wait': 1})
def parse(self, response):
print(response.xpath('//ul[@id="updatelist"]/li//a/text()').extract())
爬取结果:

这样我们就大功告成了!