-
toDF
toDF方法是将Dataset转换成Dataframe,当然,如果引入了隐式转换,则可以将rdd转换成Dataframe,import sparkSession.implicits._ val sourceRdd = sparkSession.sparkContext.makeRDD(Seq(1, 2, 3, 4)) val sourceDF = sourceRdd.toDF("num") -
as[U : Encoder]: Dataset[U]
将dataset的行数据转换类型,并返回新的datasetval sourceDF = sparkSession.sparkContext.makeRDD( Seq(("tom z", 60, 18), ("jim x", 50, 20), ("tom y", 68, 18), ("jim t", 70, 20), ("jerry l", 90, 22) )).toDF("name", "score", "age") val sourceFormatDF=sourceDF.as[(String, String, String)] -
agg
在Dataset上的聚合函数,官方提供了4种重载方法,即4种用法import sparkSession.implicits._ //创建rdd val sourceRdd = sparkSession.sparkContext.makeRDD( Seq(("tom", 60, 18), ("jim", 50, 20), ("tom", 68, 18), ("jim", 70, 20), ("jerry", 90, 22) )) //创建dataFrame val sourceDF = sourceRdd.toDF("name", "score", "age")1.agg(aggExpr: (String, String), aggExprs: (String, String)*)
sourceDF.agg(("score" -> "max"), ("age" -> "avg")).show()result:
2.agg(exprs: Map[String, String])sourceDF.groupBy("name").agg(Map("score" -> "min", "score" -> "sum")).show()result:
3.agg(exprs: java.util.Map[String, String])
和用法二一样,只是参数是java的map4.agg(expr: Column, exprs: Column*)
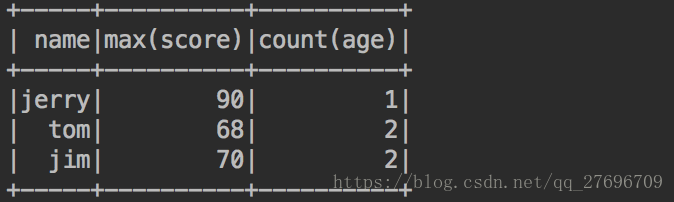
sourceDF.groupBy("name").agg(max("score"), count("age")).show()result:
-
na:DataFrameNaFunctions
返回类型是DataFrameNaFunctions用以处理dataset中缺失的数据import sparkSession.implicits._ val testDF = sparkSession.sparkContext.makeRDD( Seq(("a", null), ("b", "hj"), ("c", null) )).toDF("x", "y")1.drop:DataFrame
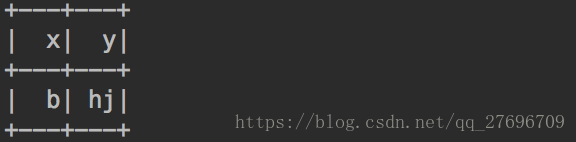
drop用来删除包含 null or NaN的行。drop可以传入两类参数,第一类是how:String,如果传入的是"any",那么只要包含null or NaN的行就会被删除,而"all"则表示如果这个行每一列都是null or NaN才会被删除,默认是"any"。第二类是cols:Array[String]/Seq[String],用来指定要被处理的列,默认是对所有列进行处理testDF.na.drop().show()result:
2.fill
fill用来替换 null or NaN。fill可以传入两类参数,第一类是value:String/Double,用来替换null or NaN的值;第二类则是cols:Seq[String],用来指定被处理的列,没有被指定的列的 null or NaN则不会被替换,默认是所有列testDF.na.fill("def").show()result:
3.replace[T]:DataFrame
用来替换指定的值。replace可以传入两类参数,第一类是col:String/Seq[String],表示要替换的列;第二类是replacement:Map[T, T],表示要被替换的目标值和替换值。testDF.na.replace[String]("x",Map("c"->"d")).show()result:
-
replace
-
schema
返回dataset的schema -
printSchema
将schema以tree的形式输出到控制台 -
explain
输出spark sql的执行计划 -
dtypes
将列名和类型以数组的形式返回 -
columns
将列名以数组的形式返回 -
show
展示dataset的数据。官方有2个地方需要注意的,第一,展示的个数默认是20;第二,展示的字符长度默认也是20,超过20的字符会被省略。当然这两个参数是可以自定义的,所以官方提供了show的5种重载方法,朋友们可以自行查阅源码以进一步了解 -
distinct
根据输入dataframe的各列组合去重,当两行的每一列数据都同等时,这两行会被去重 -
checkpoint
给dataset设置检查点 -
cache
将Dataset持久化,持久化级别是“MEMORY_AND_DISK” -
persist(newLevel: StorageLevel)
可以选择Dataset持久化的级别 -
unpersist
将持久化的Dataset从磁盘或者内存中去掉 -
coalesce
coalesce的作用是合并同一机器上的多个partition,目的是解决多个partition数据量差异很大的case带来的资源浪费 -
repartition(numPartitions: Int)
数据重新分区,可以设置参数来设置返回的分区数 -
collect
返回dataset的所有行数据 -
take
返回dataset的前几行 -
first
返回dataset的第一行 -
head(n: Int)
返回dataset的前几行 -
drop(col: Column)
删除掉某列 -
withColumnRenamed(existingName: String, newName: String)
更改列名 -
withColumn(colName: String, col: Column)
给已有的dataset添加新的列 -
explode
将dataset的一列分成多行的操作
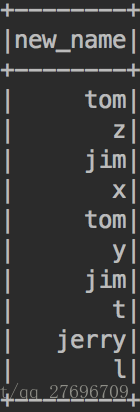
例子:import sparkSession.implicits._ val sourceRdd = sparkSession.sparkContext.makeRDD( Seq(("tom z", 60, 18), ("jim x", 50, 20), ("tom y", 68, 18), ("jim t", 70, 20), ("jerry l", 90, 22) )) val sourceDF = sourceRdd.toDF("name", "score", "age") sourceDF.select(explode(split(col("name"), " ")).as("new_name")).show()result:
-
transform
未完待续。。。。。。。。。。。。。。。。。
spark api学习之Dataset




猜你喜欢
转载自blog.csdn.net/qq_27696709/article/details/83090291
今日推荐
周排行