环境:Windows10+Anaconda python3.6.5+Spyder
目标:抓取链家北京地区所有房源信息。
打开链家官网 https://bj.lianjia.com/ 。粗略的浏览了一下,整个网站使用的都是静态网页,通过改变url来实现网页变动。不过网站默认只显示100页的内容,每页30条,不管那里写着多少多少条数据。
如果需要抓取所有数据,必须通过某些条件筛选。有地区、价格、朝向、楼层等,这里面我选择了地区,因为这是区分度比较明确的。地区就那么多,一次获取,可以同时用在在售、成交和租房。
先获取首页的地区对应的url(每一个地区都是超链接),如下图:

通过url再获取进一步区域的url,如下图:

虽然这里显示到香河,但是点击香河发现还有区域在其他的网页,这里只能将url加入一个列表,然后判断新的url是否在列表里,有就舍弃,没有则添加并获取进一步区域的信息。(而且这里还有一个很奇怪,我爬取的是北京的,所有url的host应该是bj.lianjia.com,但香河的host确是lf.lianjia.com。后面很多url都是相对路径需要手动添加host,于是又多了一步host的判断)
第一步抓取的信息如下图(这一次抓取并没有什么阻碍,全部获取到):
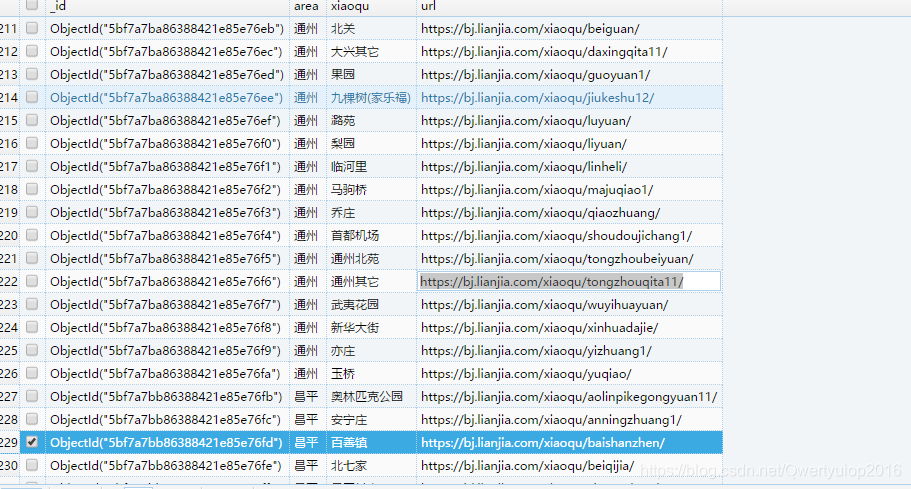
这里插一个经验:我看到很多人在这里直接将url设为_id ,这样可以直接达到去重的效果,但需要捕获异常,还有一种是update,效率是真的低的可怕(我更新的是几百万条的数据)。所以我觉得还是直接将url设为_id 去重好一点。(如果有更好的方法,还请留言指教)
第二次抓取的信息(小区),这一次抓取,sleep时间无论是随机2-5秒还是5秒都会在抓取几条之后返回404,这样只能使用代理和随机头信息。不过我没有代理,以前写的aiohttp测试的代理,居然不支持https的网站,http的网站一切正常(还是我大requests强大,就是有点慢),而且居然还有地区的小区数量大于3000,算了就这样吧:
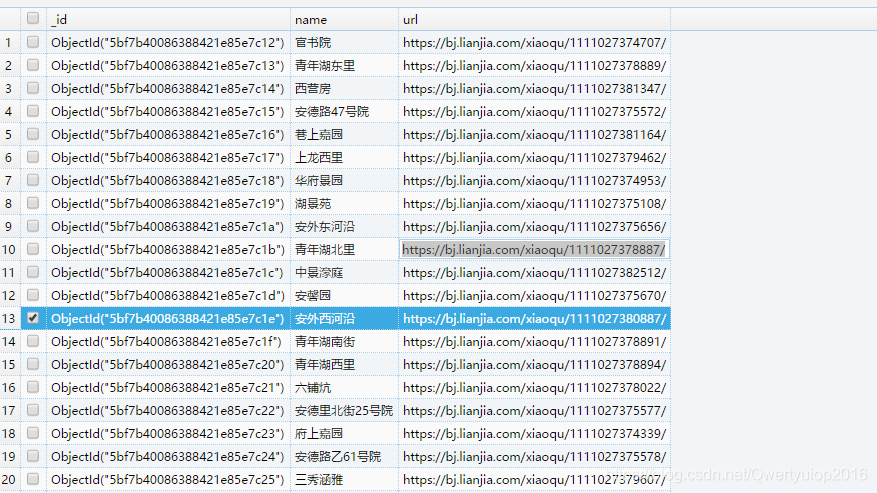
第三步则抓取小区下的房源信息:
在这里房源url是有规律的,所有没有必要访问小区的url。
小区的url格式:https://bj.lianjia.com/xiaoqu/1111027378891/
二手房成交url:https://bj.lianjia.com/chengjiao/c1111027378891/
在售url:https://bj.lianjia.com/ershoufang/c1111027378891/
租房url:https://bj.lianjia.com/zufang/c1111027380887/
所以只需要正则获取后面的一串数字,然后构造就行。这样还能将chengjiao的那部分设为变量,然后三个网站只需要一个程序就行。(而且在多次尝试发现,小区的url里面可能没有成交房源的信息,但手工构造的url却能访问,也包含正常信息,这就有点坑了)
第一步代码:
date: Fri Nov 23 10:41:25 2018
python: Anaconda 3.6.5
author: kanade
email: [email protected]
"""
import re
import requests
import pyquery
import pymongo
class Area(object):
'''
获取北京链家的所有地区的url
'''
def __init__(self):
self.start_url = 'https://bj.lianjia.com/xiaoqu/'
self.client = pymongo.MongoClient()
self.db = self.client['lianjia']['area']
self.regex = re.compile(r'\w\w\.lianjia\.com') # 提取host的正则
def get_html(self, url, session):
'''
请求url,返回host和响应内容
'''
# 提取url中的host作为请求头参数
host = re.search(self.regex, url).group()
headers = {
'Host':host,
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.61 Safari/537.36'
}
resp = session.get(url, headers=headers)
if resp.status_code == 200:
return host, resp.text
def extract_html(self, html, query_rule):
'''
使用pyquery提取网页中的区域和它相对应的url
'''
host, html = html
doc = pyquery.PyQuery(html)
items = doc(query_rule).items()
for item in items:
area = item.text()
url = item.attr.href
if url.startswith('/'):
url = 'https://' + host + url
yield area, url
def run(self):
'''
运行函数,因为最多只有两页地区信息,所以只有两个循环
'''
session = requests.Session()
html = self.get_html(self.start_url, session)
self.area_url = list(self.extract_html(html, 'div[data-role="ershoufang"] a'))
# 获取详细的小区信息,并存储到MongoDB
for area, url in self.area_url:
html = self.get_html(url, session)
xiaoqu = self.extract_html(html, 'div[data-role="ershoufang"] div:last-child a')
for sub_area, sub_url in xiaoqu:
d = {'area':area,
'xiaoqu':sub_area,
'url':sub_url
}
self.db.insert_one(d)
#time.sleep(0.5)
# html为上一次循环最后一个网页,再提取一遍地区,如果和上次相同则舍弃,否则获取小区
for area_url in self.extract_html(html, 'div[data-role="ershoufang"] div:first-child a'):
if area_url not in self.area_url:
area, url = area_url
html = self.get_html(url, session)
xiaoqu = self.extract_html(html, 'div[data-role="ershoufang"] div:last-child a')
for sub_area, sub_url in xiaoqu:
d = {'area':area,
'xiaoqu':sub_area,
'url':sub_url
}
self.db.insert_one(d)
if __name__ == '__main__':
a = Area()
a.run()
第二步代码:
# -*- coding: utf-8 -*-
"""
date: Fri Nov 23 15:07:38 2018
python: Anaconda 3.6.5
author: kanade
email: [email protected]
"""
import re
import time
import random
import requests
import pyquery
import pymongo
class XiaoQu(object):
'''
获取地区下的所有小区的url
'''
def __init__(self):
self.client = pymongo.MongoClient()
self.db_xiaoqu = self.client['lianjia']['xiaoqu']
self.regex = re.compile(r'\w\w\.lianjia\.com')
def random_time(self):
i = random.randint(2, 4)
j = random.random()
return i + j
def get_html(self, url, session):
host = re.search(self.regex, url).group()
headers = {
'Host':host,
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.61 Safari/537.36'
}
resp = session.get(url, headers=headers)
print(resp.status_code)
if resp.status_code == 200:
return host, resp.text
def run_one(self, url):
session = requests.Session()
html = self.get_html(url, session)
doc = pyquery.PyQuery(html[1])
count = int(doc('.resultDes.clear h2.total span').text().strip())
if count == 0:
return
self.extract(html)
if count % 30 == 0:
count = count // 30
else:
count = count //30 + 1
time.sleep(2)
for page in range(2, count+1):
if url.endswith('/'):
url += 'pg' + str(page) + '/'
else:
url += '/pg' + str(page) + '/'
html = self.get_html(url, session)
self.extract(html)
t = self.random_time()
time.sleep(t)
def run(self):
db_area = self.client['lianjia']['area']
for data in db_area.find().skip(222):
print(data['area'],data['xiaoqu'])
self.run_one(data['url'])
def extract(self, html):
host, html = html
doc = pyquery.PyQuery(html)
data = []
items = doc('li.xiaoquListItem').items()
for item in items:
name = item.find('.title a').text()
url = item.find('.title a').attr.href
if url.startswith('/'):
url = 'https://' + host + url
d = {'name':name,
'url':url
}
data.append(d)
self.db_xiaoqu.insert_many(data)
if __name__ == '__main__':
xq = XiaoQu()
xq.run()
第三步代码:
# -*- coding: utf-8 -*-
"""
date: Sat Nov 24 11:10:05 2018
python: Anaconda 3.6.5
author: kanade
email: [email protected]
"""
import time
import re
import requests
import pyquery
import pymongo
class FangYuan(object):
'''
从数据库拿到小区的链接,然后抓取小区的房源信息
'''
def __init__(self):
client = pymongo.MongoClient()
self.db = client['lianjia']
self.regex = re.compile(r'\w\w\.lianjia\.com')
def get_html(self, url, session):
host = re.search(self.regex, url).group()
headers = {
'Host':host,
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.61 Safari/537.36'
}
resp = session.get(url, headers=headers)
print(resp.status_code)
if resp.status_code == 200:
return resp.text
def run_one(self, url):
host = re.search(self.regex, url).group()
url_id = re.search(r'/(\d+)', url).group(1)
url = 'https://' + host + '/chengjiao' + '/c' + url_id + '/'
session = requests.Session()
html = self.get_html(url, session)
doc = pyquery.PyQuery(html)
count = int(doc('.resultDes.clear .total span').text().strip())
if not html or count == 0:
return
self.extract(html, host)
if count % 30 == 0:
count = count // 30
else:
count = count // 30 + 1
time.sleep(2)
for page in range(2, count+1):
url = 'https://' + host + '/chengjiao'+\
'/pg'+str(page)+'c'+url_id +'/'
html = self.get_html(url, session)
self.extract(html, host)
time.sleep(3)
def run(self):
for i in self.db['xiaoqu'].find():
self.run_one(i['url'])
def extract(self, html, host):
doc = pyquery.PyQuery(html)
items = doc('ul.listContent li').items()
for item in items:
img = item.find('.img').attr.href
title = item.find('.title a').text()
url = item.find('.title a').attr.href
time_ = item.find('.address .dealDate').text()
price = item.find('.address .totalPrice').text()
every_price = item.find('.flood unitPrice').text()
describe_1 = item.find('.address .houseInfo').text()
describe_2 = item.find('.flood .positionInfo').text()
describe_3 = item.find('.dealHouseInfo').text()
describe_4 = item.find('.dealCycleeInfo').text()
describe = describe_1.strip() + '\n' + describe_2.strip() +\
'\n' + describe_3.strip() +'\n'+ describe_4.strip()
if url.startswith('/'):
url = 'https://' + host + url
d = { 'img':img,
'title':title,
'url':url,
'time':time_,
'price':price,
'every_price':every_price,
'describe':describe
}
self.db['fangyuan'].insert_one(d)
if __name__ == '__main__':
fy = FangYuan()
fy.run_one('https://bj.lianjia.com/xiaoqu/1111027378889/')
#fy.run()
如果想要全部房源信息,需要加入代理。我就不加了,没加代理很快就会返回404。因为只是学习思路,这个爬虫并不成熟,没有异常处理,也没有特殊情况处理,而且爬虫还可以在宏观一点,获取每个城市的url。有能力或者需求的可以自行添加。