在分类算法中,我们首先将数据集分成训练数据集和测试数据集,用训练数据集去训练我们的分类模型,用测试数据集的输入特征去预测,将预测的结果与测试数据集的真实结果对比,得出模型的准确率。
对于线性回归算法:

上面的衡量标准是与样本数m有关的

对于均方误差(MSE)来说还有一个量纲上的问题,改进后会得到均方根误差(RMSE)


以上就是三个评价线性回归算法的标准
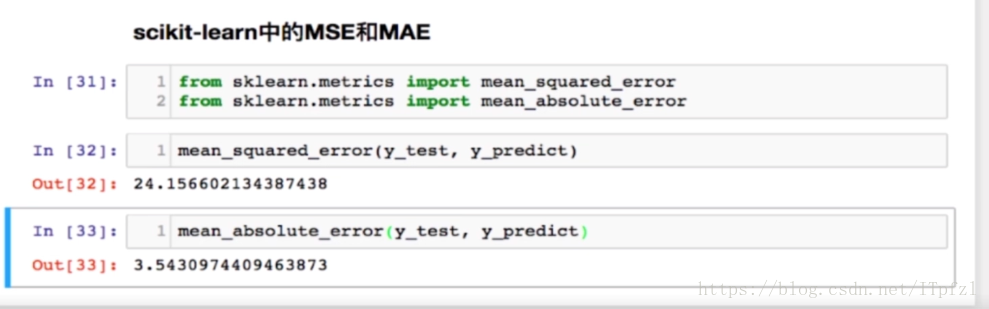
mean_squared_error是均方误差(MSE)
mean_absolute_error是绝对值误差(MAE)
R平方模型衡量的是我们训练出的模型对比y等于y的均值这个基准模型的效果是怎么样

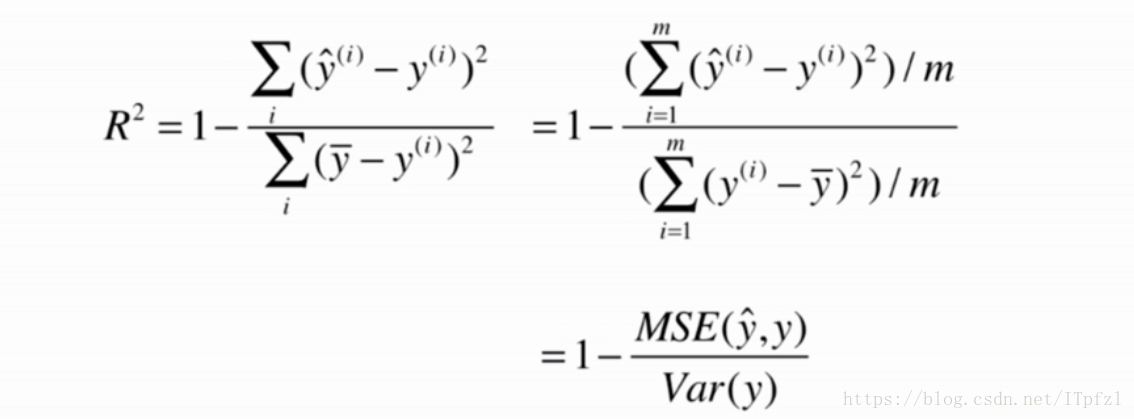

使用sklearn提供的包

三个评价线性回归标准的代码实现
import numpy as np
from math import sqrt
def accuracy_score(y_true, y_predict):
"""计算y_true和y_predict之间的准确率"""
assert len(y_true) == len(y_predict), \
"the size of y_true must be equal to the size of y_predict"
return np.sum(y_true == y_predict) / len(y_true)
def mean_squared_error(y_true, y_predict):
"""计算y_true和y_predict之间的MSE"""
assert len(y_true) == len(y_predict), \
"the size of y_true must be equal to the size of y_predict"
return np.sum((y_true - y_predict)**2) / len(y_true)
def root_mean_squared_error(y_true, y_predict):
"""计算y_true和y_predict之间的RMSE"""
return sqrt(mean_squared_error(y_true, y_predict))
def mean_absolute_error(y_true, y_predict):
"""计算y_true和y_predict之间的MAE"""
assert len(y_true) == len(y_predict), \
"the size of y_true must be equal to the size of y_predict"
return np.sum(np.absolute(y_true - y_predict)) / len(y_true)
def r2_score(y_true, y_predict):
"""计算y_true和y_predict之间的R Square"""
return 1 - mean_squared_error(y_true, y_predict)/np.var(y_true)