版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Zoe_Su/article/details/84481651
深度知识追踪(Deep Knowledge Tracing)
知识追踪是基于学生行为序列进行建模,预测学生对知识的掌握程度。知识追踪是构建自适应教育系统的核心和关键。在自适应的教育系统中,无论是做精准推送,学生学习的路径规划或知识图谱的构建,第一步都是能够精准预测学生对知识的掌握程度。
知识追踪问题可以描述为: 给定一学生的观测序列
x0,……,xt预测下次表现
xt+1,通常
xt={qt,at},其中
qt代表回答的问题成分(如对应的知识点),
at代表对应的回答是否正确,通常
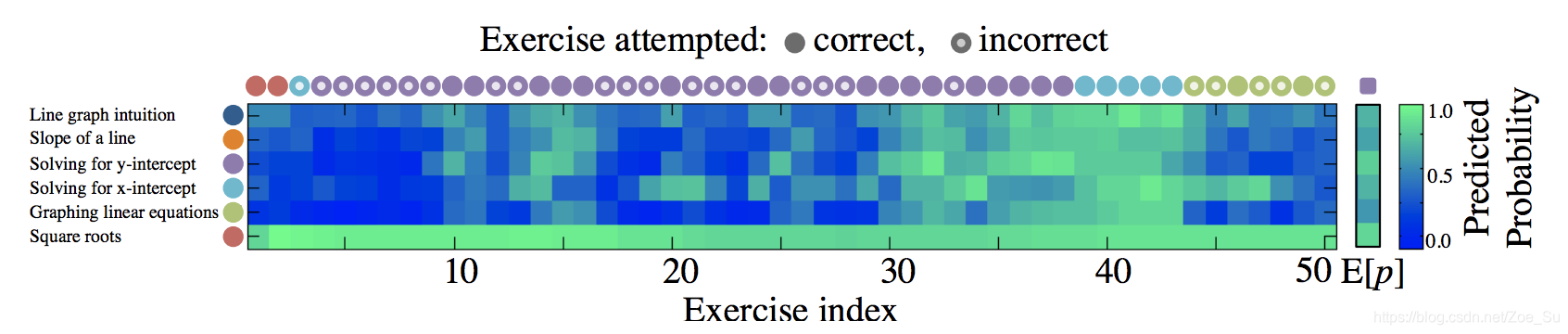
at={0,1}。 下图描述了一个学生在八年级数学中的知识追踪结果可视化展示。
传统的知识追踪是基于一阶马尔可夫模型,如贝叶斯知识追踪(Bayesian Knowledge Tracing),2015年 Chris Piech 等人提出利用深度学习来处理知识追踪的任务,之后引发了学者们对利用深度学习来处理知识追踪任务对不断探讨,下面依次介绍相关论文核心内容及思考。
Deep Knowledge Tracing
循环神经网络(RNN)是一种时间序列的模型,天然具有高维连续的隐状态表示的特征,RNN能够利用早期的信息进行预测,因此在2015年 Chris Piech 将RNN应用于知识追踪领域,并取得了较好的结果。
模型:
文章中,作者采用了传统的RNN模型和其变种LSTM,其输入数据为经过编码的
qt,输出为
at。对于输入的编码方式有两种:
- 将输入进行one-hot编码,如模型输入数据涉及M个知识成分(如知识点),每道题有两种结果0,1(分别对应答错和答对),则模型输入长度为2M。例如,对于某题,其知识成分为i,若答对,对应输入为第i+1位为1其余位置为0;若答错,则第i位为1其余位置为0。
- 将输入进行压缩,若知识成分M巨大时,输入维度过高,可以采用感知压缩使输入从2M降低至
log(2M)。
模型输出
yt 长度为M,对应描述了每一个知识成分的掌握程度(即对应知识成分所对应题目的答对概率),模型的核心为使用前
t时刻的学生做题序列预测
t+1时刻的知识成分的掌握情况,即:
P(yt+1∣xt,……,xt)。
模型的目标函数是观测序列的非负对数似然函数,假设
δ(qt+1)为
t+1时刻的编码输入,
l为二进制交叉上函数,目标函数如下:
L=∑tℓ(yiTδ(qt+1),at+1)
模型优缺点:
优点:
- 能够反应长时间的知识关系,基于RNN的特性能够根据学生近期学习表现进行预测(近因效应),也能根据实际学生学习路径进行建模;
- 能够对复杂的知识点之间的联系进行建模,如构建知识图谱;
- 能够处理多知识成分的问题。
- 模型无法重构输入,即输入某一知识成分答题错误,模型对该知识成分的预测反而是正确。
- 在时间序列上,学生对知识点的掌握程度不具有连续一致性,波动情况较大。
Going Deeper with Deep Knowledge Tracing
2016年Xiaolu Xiong等人对DKT和PFA(Performance Factor Analysis),BKT(Bayesian Knowledge Tracing)模型进行了比较,对DKT模型能碾压其他两种模型的结果进行了怀疑并加以论证,进一步讨论了原论文能够得出上述结果的原因,对进一步使用DKT模型提供了参考。
文章中指出,对于DKT文章中在ASSISTments数据集上取得好的结果的原因进行了分析,得到以下三个原因来说明为什么DKT能够取得碾压BKT的效果:
- ASSISTments数据集中存在23.6%的重复数据,这部分数据应该舍弃而不应该用于训练或测试。
- DKT模型在实验中,并没有去除支架式教学问题的做题记录,这就导致DKT模型能够有更多信息引入模型。
- 由于DKT处理多知识成分的问题时,单条做题记录会被扩展成多条,存在重复利用数据的问题。
作者将上述问题数据依次剔除,形成多个数据集,并采用ACU和
r2作指标,对DKT,PFA,BKT模型进行了对比,结果表明DKT相比BKT和PFA没有碾压式的超越但是的确会比其他模型结果要好。
文章中提及,当遇到多知识成分的题目时,使用联合知识成分作为新的知识成分的方式比重复利用做题记录的方式结果要差很多,这也是在我们实际使用DKT模型中需要注意的。
Addressing Two Problems in Deep Knowledge Tracing viaPrediction-Consistent Regularization
Chun-Kit Yeung等人在2018年6月发表论文中指出DKT模型现存的缺点,即对输入序列存在重构问题和预测结果的波动性,进而论文提出了改善上述问题的方法:增加对应的正则项,得到DKT+(增强的DKT模型)。

如上图所示,纵轴
Si表示知识成分,横轴为学生在各个知识成分上的答题情况。
问题1对应的是在
6thstep,
S45的评估结果相比前一时刻是增加了的即使当前的输入是
S45做错了的。
问题2对应为在上述图描述的学习过程中,
S32,S33,S45和
S55预测做对的概率随着
S32,S33的学习有着非常大的波动,这和我们实际情况是不相符的,我们总是期望知识成分的变化是随着时间缓慢变化的,而不是在掌握和没掌握之间跳跃。
对于问题1,作者认为出现这种情况是由于,在DKT模型采用的损失函数中并没有考虑到时间t时刻的输入值,只是考虑了t时刻的输出值和t+1时刻的输入值。为了解决上述问题,作者在损失函数中引入正则项,并在正则项中引入了时间t时刻的输入值,正则项r如下:
r=∑i=1n(Ti−1)1(∑i=1n∑t=1Ti−1l(yti⋅δ(qti),ati))
对于问题2,作者认为可能是由于RNN的隐层表示问题,RNN的隐含层
ht依赖于前一隐含层的输出
ht−1和当前输入
xt,隐含层表示了潜在的学生知识掌握程度,但是很难说清隐含层的每个状态是如何影响对知识成分的预测。所以简答起见,直接对输出结果进行正则约束(L1,L2正则),使预测结果能够平滑输出,所加正则项如下:
w1=M∑i=1n(Ti−1)∑i=1n∑t=1Ti−1∥yt+1i−yti∥1
w22=M∑i=1n(Ti−1)∑i=1n∑t=1Ti−1∥yt+1i−yti∥22
综合上述正则项,最终模型的损失函数为:
L′=L+λrr+λw1w1+λw2w22
参考文献:
- Deep Knowledge Tracing
- Addressing Two Problems in Deep Knowledge Tracing via Prediction-Consistent Regularization
- Going Deeper with Deep Knowledge Tracing
- How Deep is Knowledge Tracing?