一、集合的遍历
集合的遍历可以有多种方式
1.普通的for循坏(两种)
①for(int i = 0; i < list.size(); i++){
System.out.println(list.get(i));
}
②int length = list.size();
for(int i = 0; i < length; i++){
System.out.println(list.get(i));
}
2.写成foreach形式的for
for (String str:list){
System.out.println(str);
}
3.迭代器
for(Iterator iterator = list.iterator();iterator.hasNext();){
System.out.println(iterator.next());
}
4.集合的forEach方法
list.forEach(s -> {
System.out.println(s);
});
5.迭代器的forEachRemaining
Iterator iterator = list.iterator();
iterator.forEachRemaining(str->{
System.out.println(str);
});
有关于这几种遍历方式的效率问题看具体集合而定,这里不作介绍
这次主要介绍的是第2、第3、第4和第5的本质。
二、foreach相关遍历的本质
1.第2也就是写成foreach形式的for,很多人都知道它其实是调用了迭代器,这其实是一种语法糖,可以通过反编译来验证,由于缺乏反编译工具,这里只验证其使用了迭代器,我们验证使用的集合是Vector,这是一个历史遗留的类,采用它作测试的原因下文会讲到。
首先,我们在Vector迭代器上设置断点:
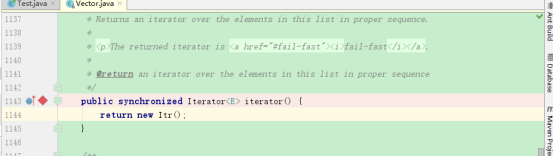
然后在主程序进行debug,得到结果:
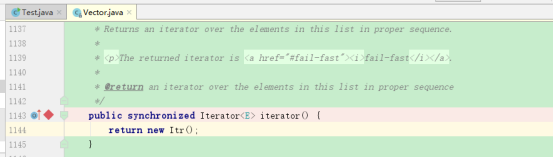
我们可以发现程序跳到了迭代器上,由此可以得出写成foreach形式的for实际调用了迭代器进行遍历。
2.第3就是迭代器,这个就是直接调用迭代器进行遍历
3.第4就是集合的forEach方法,这个方法在Iterable接口就定义成了默认方法:
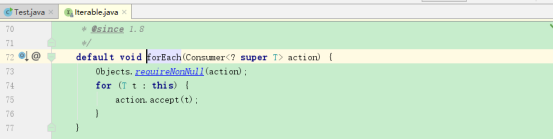
而在有些集合里面会对这个方法进行重写。
在这里我们测试两种集合,第一种还是前面的Vector,我们可以发现在Vector里对forEach方法进行了重写:
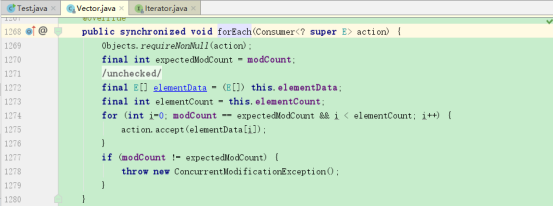
第二种集合是LinkedList,在LinkedList里没有对forEach方法进行重写。
①在集合Vector上的测试
先在Iterable上的forEach方法上作断点:
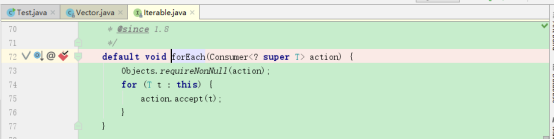
在主程序上debug:
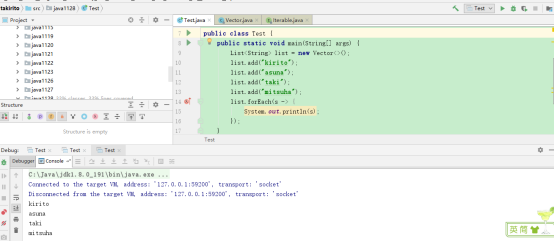
可以发现程序直接停止,并没有跳到Iterable上的forEach断点,说明在Vector集合上的forEach方法不是Iterable上的forEach方法
把在Iterable上的forEach方法的断点取消,在Vector上重写的forEach方法上作断点:
在主程序上debug:
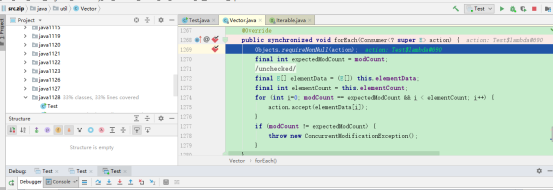
可以发现跳到Vector上的forEach方法,说明在Vector集合上的forEach方法是Vector上的forEach方法,其实这很明显,作验证只是为了证明“编译看左边,运行看右边”
List<String> list = new Vector<>();
虽然List类里没有重写forEach方法,运行看右边,运行时是调用的是Vector集合上的forEach方法。然后我们取消在Vector上重写的forEach方法上的断点。
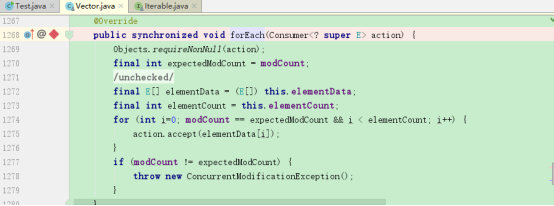
我们看下Vector上重写的forEach方法的源码
public synchronized void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int elementCount = this.elementCount;
for (int i=0; modCount == expectedModCount && i < elementCount; i++) {
action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
就是对elementData依次填到action.accept方法,由于调试无法进去accept方法,只是和lambda表达式结合在一起,所以我们通过别的方式推断accept执行了什么。
接下来验证在Vector上重写的forEach方法(accept)有没有调用迭代器,我们先在Vector迭代器上加断点:
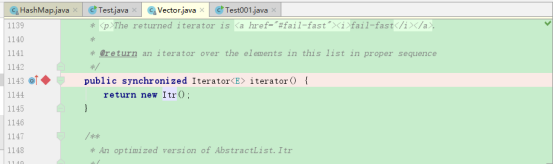
然后在主程序debug:
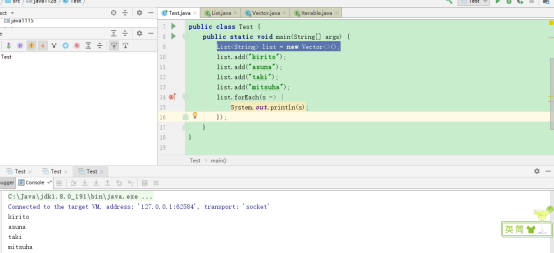
可以发现程序正常停止,没有调用Vector的迭代器,说明forEach方法并没有调用Vector的迭代器。
②在集合LinkedList上的测试
由于LinkedList没有重写forEach方法,所以调用的是Iterable上的forEach方法,下面进行验证
在Iterable上的forEach方法上加断点:

debug:
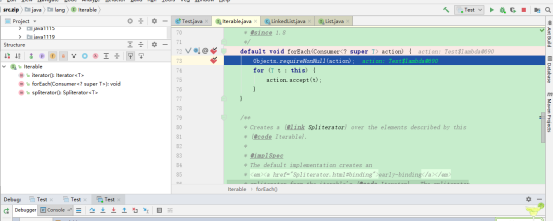
可以发现调用的确实是Iterable上的forEach方法
再在LinkedList迭代器上添加断点(因为LinkedList的Iterator方法没有重写,所以在AbstractSequentialList的迭代器方法上加断点):
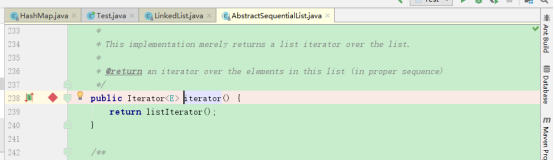
结果:
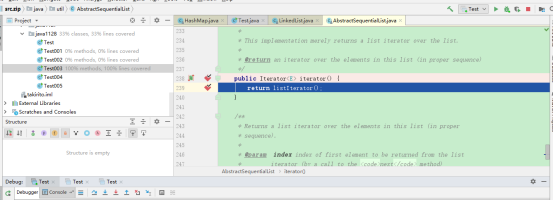
我们可以发现Iterable上的forEach方法调用了迭代器,我们再看Iterable上的源码:
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
发现调用的是一个foreach循环上的for,前面我们已经证明这个形式的遍历其实是通过迭代器来遍历的,然后再调用action.accept方法。
因此,Vector迭代器里的forEachRemaing方法也是同理,没重写的调用迭代器,有重写的不调用,可以查看下面源码得出:
Iterator的forEachRemaining方法
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
Vector迭代器重写的forEachRemaining方法
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
synchronized (Vector.this) {
final int size = elementCount;
int i = cursor;
if (i >= size) {
return;
}
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) Vector.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
action.accept(elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
}
三、遇到的问题
本来这是能直接看源码就能理解的事,为什么要debug来验证呢?
因为在我们不能进去的accept方法里,有一个问题,这也是我们测试之所以不采用ArrayList的原因。
我们查看ArrayList源码:
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
可以发现和Vector基本类似,那么ArrayList的forEach方法和迭代器里的forEachRemaining方法应该不会调用迭代器才对,我们先看测试:
在ArrayList迭代器上设置断点:
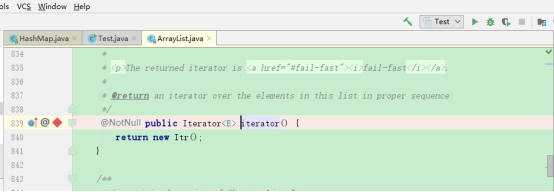
debug:
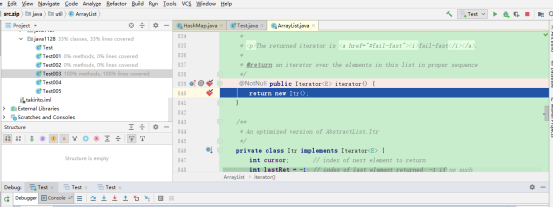
居然跳转到迭代器上。
再测试迭代器上的forEachRemaining方法,同样在ArrayList迭代器上设置断点,debug:
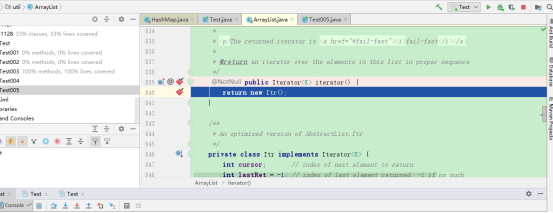
也跳转到迭代器上。
这和我们前面Vector的测试结果完全不一样,我们前面得到的结论是:没重写的调用迭代器,有重写的不调用。但ArrayList的这两个方法却调用了迭代器,但是ArrayList里重写的forEach方法和forEachRemaining方法确实没有调用迭代器的代码啊,这时,只剩下一个我们进不去的accept方法了,只能看怎么找出结果,但是因为进不去实在毫无头绪,于是我在debug界面里面疯狂乱跳代码,结果跳到一处:
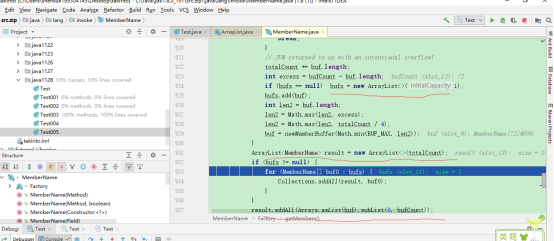
可以发现此处new了两个ArrayList并把buf加进去result,往下
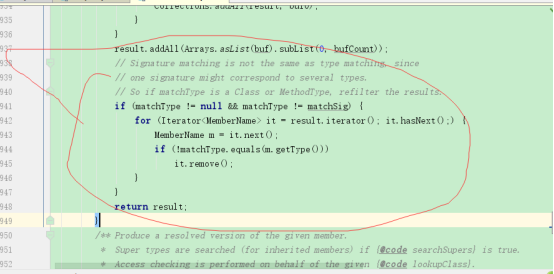
我们又发现了迭代器的使用,原来迭代器是在这使用的,为了验证确实是在accept方法里使用的ArrayList的迭代器,我们会到Vector的测试,ArrayList上的迭代器上断点保留,debug:
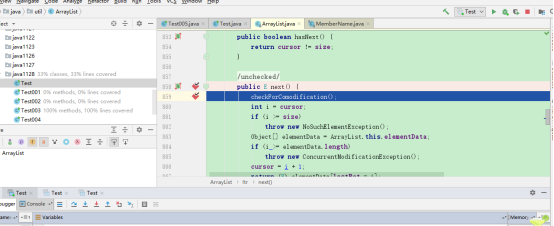
结果不出所料,真的跳到ArrayList的迭代器上去了。
所以,accept方法和lambda结合,原理实在复杂又不能debug,只能勉强得出这里面用到ArrayList和它的迭代器,可能是拿来迁移数据和遍历输出的,当然这只是我的猜测。
四、新的问题
集合里还有HashMap,但HashMap的遍历是通过Set进行的,于是我开始着眼于Set,先测试,代码:
public class Test {
public static void main(String[] args) {
Map<String,String> map = new HashMap();
map.put("kirito", "asuna");
map.put("taki", "mitsuha");
Set<String> set = map.keySet();
set.forEach(a->{
System.out.println(a);
});
}
}
依然是在迭代器上作断点
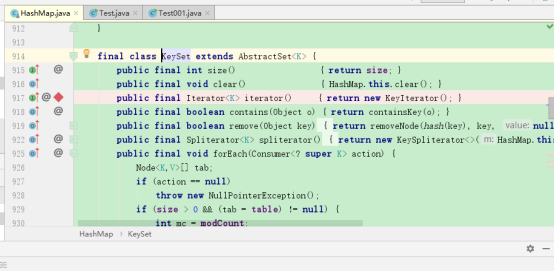
debug:
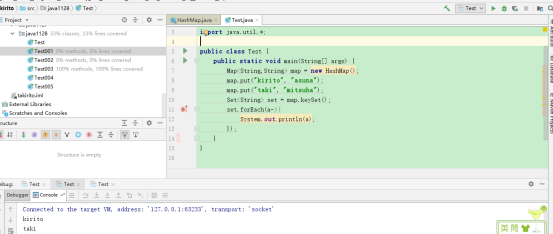
主程序停止,并没有调转到迭代器,这符合我们之前的结论,毕竟HashMap的KeySet里有对forEach方法进行重写
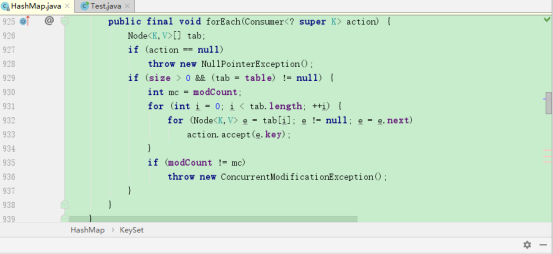
然后我们换成forEachRemaining方法,结果跳转了:
因为HashMap的KeySet迭代器没有对forEachRemaining方法进行重写,所以调用Iterator的forEachRemaining方法,所以用到了迭代器,在我心满意足的时候,一切都向着我希望的方式发展时,我发现KeySet的迭代器是KeyIterator

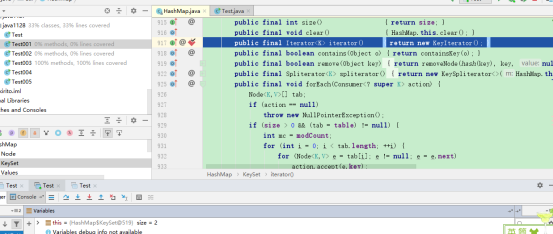
因此我决定把断点设置深一点看看
debug:
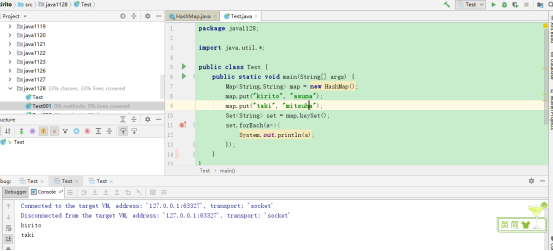
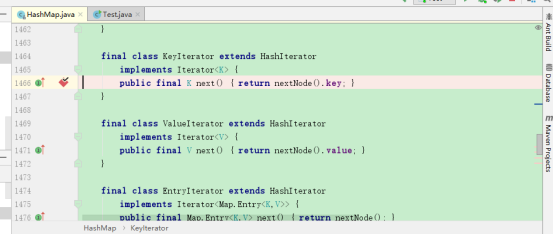
仍然停止,就在我要放弃的时候,发现

KeyIterator继承自HashIterator,然后我再把断点设置到了HashIterator上
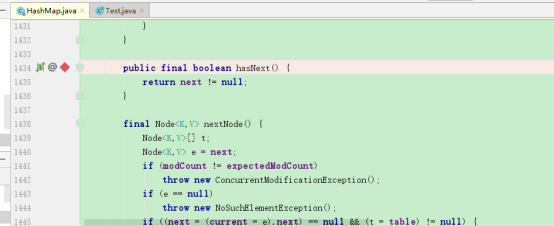
debug:
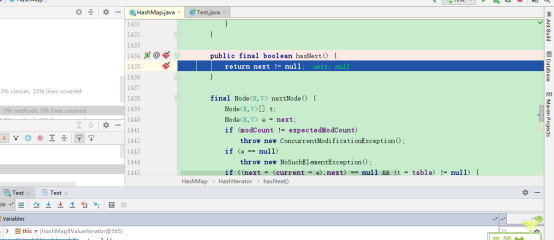
这回竟然跳转到了这个迭代器,我思前想后,应该还是accept的问题,因为确实forEach方法里是没有调用到迭代器的,然后我还是疯狂debug:来了
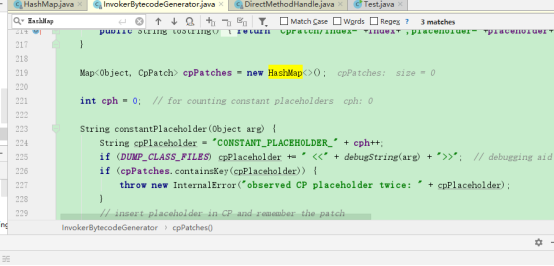
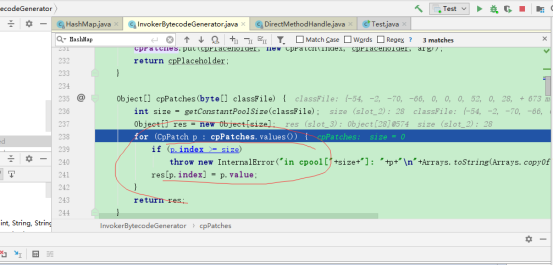
这里用了HashMap里values的迭代器,所以刚刚不会跳到KeySet的迭代器而是跳到HashIterator。
在values的迭代器设置断点:
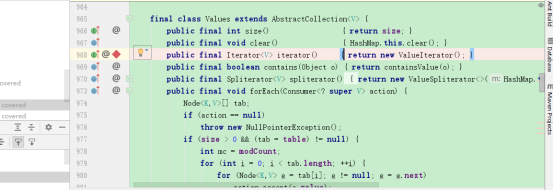
debug:
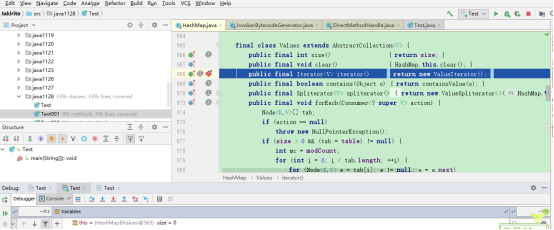
不出所料
五、结论
经过了这么一折腾,我们可以发现默认的forEach方法(Iterable)和forEachRemaining方法(Iterator)都会调用对应集合的迭代器,集合没重写调用的就是默认的这两种方法,集合重写后的这两种方法一般都是自己遍历然后交给lambda表达式输出,不会调用迭代器,但是lambda表达式的原理里面,存在ArrayList和HashMap的values这两个集合的使用以及迭代器的使用,虽然用处不知,但这使用这两种集合作测试时会误认为重写过后的forEach方法(Iterable)和forEachRemaining方法是调用自身迭代器进行遍历,所以forEach方法和forEachRemaining方法的时间复杂度,不是重写的要看自身迭代器的效率还有ArrayList和HashMap的效率,是重写的则是自己重写遍历效率和ArrayList和HashMap的效率,相当复杂,因为lambda的原理完全不懂。所以,对于网上各种遍历方式的时间效率测试,没有绝对的对错,这不仅要看集合,还要看各种实现,总之,时间复杂度不是绝对的,要看具体代码,代码级别的时间复杂度才足够客观。