MeanShift
该算法也叫做均值漂移,在目标追踪中应用广泛。本身其实是一种基于密度的聚类算法。
主要思路是:计算某一点A与其周围半径R内的向量距离的平均值M,计算出该点下一步漂移(移动)的方向(A=M+A)。当该点不再移动时,其与周围点形成一个类簇,计算这个类簇与历史类簇的距离,满足小于阈值D即合并为同一个类簇,不满足则自身形成一个类簇。直到所有的数据点选取完毕。
一般形式
对于给定的 n 维空间
中的 m 个样本点
,i=1…m,对于其中一个样本X,他的均值漂移向量为:
,其中
指的是一个半径为h的球状领域,定义为
,如下图所示
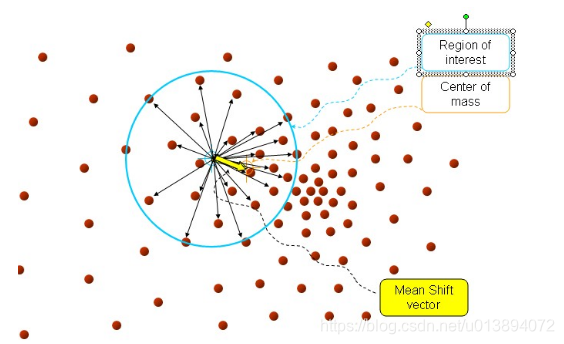
蓝色圈内表示半径h的区域
,黄色箭头尾部指的是计算前的数据点
,箭头本身是指的计算后的漂移向量
。由上图可以看出,均值漂移会不断的往密度较大的区域移动。熟悉的同学可能了解到,一般用的均值漂移都是经过核函数改进的,那为什么要引入核函数呢?
首先,我们再看一下上图和公式:蓝色圈区域内,每一个与
相邻的
在计算过程中对均值漂移向量的贡献都是一样的,不以这个点与X的距离远近而变化。按照我们人类的思想,近朱者赤 近墨者黑,离得中心点越近,受影响/反影响的力度就会越大。比如,都是程序员,但是三线城市程序员和北京程序员在知识广度、能力、成长速度等方面都有较大差距,毕竟北京是互联网行业的中心城市嘛。应用到算法里也是一样的,因此就有人提出邻域内的点需要设置不同的权重来进行漂移计算,故提出了核函数的概念
核函数形式
设
是输入空间,是实数空间的一个子集。设
为希尔伯特空间(完备的空间,抽象意义上对有限维欧式空间的扩展),设存在一个映射:
,此时有函数
,其中
。关于希尔伯特空间和核函数的概念,本人了解的也不深,欢迎探讨。
高斯核函数是一种应用广泛的核函数:
其中h为bandwidth 带宽,不同带宽的核函数形式也不一样
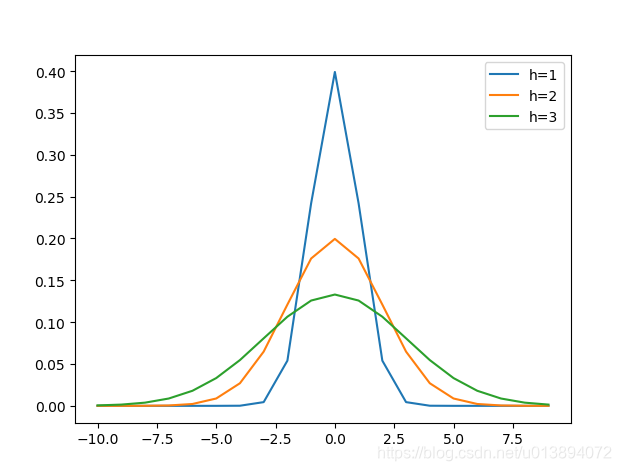
由上图可以看到,横坐标指的是两变量之间的距离。距离越近(接近于0)则函数值越大,否则越小。h越大,相同距离的情况下 函数值会越小。因此我们可以选取适当的h值,得到满足上述要求的那种权重(两变量距离越近,得到权重越大),故经过核函数改进后的均值漂移为:
其中
就是高斯核函数
看到其他的文章说,经过核函数改进后的均值漂移,经过证明(求导),会朝着概率密度上升的区域移动。
上代码及实验结果:
Python代码
class MeanShift(object):
"""
均值漂移聚类-基于密度
"""
def __init__(self,radius = 0.5,distance_between_groups = 2.5,bandwidth = 1,use_gk = True):
self._radius = radius
self._groups = []
self._bandwidth = bandwidth
self._distance_between_groups = distance_between_groups
self._use_gk = use_gk #是否启用高斯核函数
def _find_nearst_indexes(self,xi,XX):
if XX.shape[0] == 0:
return []
distances= eculide(xi,XX)
nearst_indexes = np.where(distances <= self._distance_between_groups)[0].tolist()
return nearst_indexes
def _compute_mean_vector(self,xi,datas):
distances = datas-xi
if self._use_gk:
sum1 = self.gaussian_kernel(distances)
sum2 = sum1*(distances)
mean_vector = np.sum(sum2,axis=0)/np.sum(sum1,axis=0)
else:
mean_vector = np.sum(datas - xi, axis=0) / datas.shape[0]
return mean_vector
def fit(self,X):
XX = X
while(XX.shape[0]!=0):
# 1.从原始数据选取一个中心点及其半径周边的点 进行漂移运算
index = np.random.randint(0,XX.shape[0],1).squeeze()
group = Group()
xi = XX[index]
XX = np.delete(XX,index,axis=0) # 删除XX中的一行并重新赋值
nearest_indexes = self._find_nearst_indexes(xi, XX)
nearest_datas = None
mean_vector = None
if len(nearest_indexes) != 0:
nearest_datas = None
# 2.不断进行漂移,中心点达到稳定值
epos = 1.0
while (True):
nearest_datas = XX[nearest_indexes]
mean_vector = self._compute_mean_vector(xi,nearest_datas)
xi = mean_vector + xi
nearest_indexes = self._find_nearst_indexes(xi, XX)
epos = np.abs(np.sum(mean_vector))
if epos < 0.00001 : break
if len(nearest_indexes) == 0 : break
# 有些博客说在一次漂移过程中 每个漂移点周边的点都需要纳入该类簇中,我觉得不妥,此处不是这样实现的,
# 只把稳定点周边的数据纳入该类簇中
group.members = nearest_datas.tolist()
group.center = xi
XX = np.delete(XX, nearest_indexes, axis=0)
else:
group.center = xi
# 3.与历史类簇进行距离计算,若小于阈值则加入历史类簇,并更新类簇中心及成员
for i in range(len(self._groups)):
h_group = self._groups[i]
distance = eculide(h_group.center,group.center)
if distance <= self._distance_between_groups:
h_group.members = group.members
h_group.center = (h_group.center+group.center)/2
else:
group.name = len(self._groups) + 1
self._groups.append(group)
break
if len(self._groups) == 0:
group.name = len(self._groups) + 1
self._groups.append(group)
# 4.从余下的点中重复1-3的计算,直到所有数据完成选取
def plot_example(self):
figure = plt.figure()
ax = figure.add_subplot(111)
ax.set_title("MeanShift Iris Example")
plt.xlabel("first dim")
plt.ylabel("third dim")
legends = []
cxs = []
cys = []
for i in range(len(self._groups)):
group = self._groups[i]
members = group.members
x = [member[0] for member in members]
y = [member[2] for member in members]
cx = group.center[0]
cy = group.center[2]
cxs.append(cx)
cys.append(cy)
ax.scatter(x, y, marker='o')
#ax.scatter(cx,cy,marker='+',c='r')
legends.append(group.name)
plt.scatter(cxs,cys,marker='+',c='k')
plt.legend(legends, loc="best")
plt.show()
def gaussian_kernel(self,distances):
"""
高斯核函数
:param distances:
:param h:
:return:
"""
left = 1/(self._bandwidth*np.sqrt(2*np.pi))
right = np.exp(-np.power(distances,2)/(2*np.power(self._bandwidth,2)))
return left*right
def test_meanshift(use_gk = False):
data,t,tn=load_data()
ms = MeanShift(radius=0.66,distance_between_groups=1.4,use_gk=use_gk)
ms.fit(data)
ms.plot_example()
test_meanshift(use_gk = True)
上述定义的Group类及一些import导入包,参见K均值聚类及代码实现
实验结果还是利用了iris数据集,结果如下,第一幅图是一般形式,第二幅图是高斯核函数。黑色“+”代表的是聚类中心


与KMeans相比较而言,meashift可以不用指定类簇的个数,自动发现类簇结构。
但是Kmeans也类似,发现的类簇多为球状类簇,不能发现一些混合度较高,非球状类簇。
下面是经过调参得到的分为3个类图像。此时
MeanShift(radius=1.5,distance_between_groups=2.3,use_gk=use_gk)
此处实现的与sklearn中的MeanShift不同,后续会研究一下sklearn的实现方法。

参考文献
1.简单易学的机器学习算法——Mean Shift聚类算法
2.python机器学习算法-赵志勇
1中的文章也是2作者写的