一、SparkStreaming简介
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对多种数据源(如Kdfka、Flume、Twitter、Zero和TCP 套接字)进行类似Map、Reduce和Join等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。

Spark Streaming处理的数据流图

Spark Streaming构架
二、DStream简介
1.Dstream离散流由一系列连续的RDD组成,每个RDD都包含了确定时间间隔内的数据。

2.对DStream中数据的各种操作也是映射到内部的RDD上来进行的
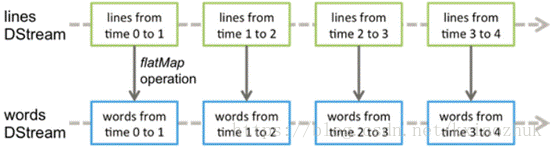
3.Dstream的输入源包括基本源(文件系统和Socket(套接字)连接)和高级源( Kafka、Flume、Kinesis、Twitter 等,额外增加类依赖)
三、DStream操作
1.1普通的转换操作:map、flatMap、flter、union、count、join等
1.2transform(func)操作:允许DStream 上应用任意RDD-to-RDD函数
1.3updateStateByKey操作:
1.4窗口转换操作: 允许你通过滑动窗口对数据进行转换,如countByWindow、 reduceByKeyAndWindow等,(批处理间隔、窗口间隔和滑动间隔)
2.输出操作:允许DStream的数据被输出到外部系统,如数据库或文件系统,有print()、foreachRDD(func)、saveAsTextFiles()、 saveAsHadoopFiles()等
3.持久化:通过persist()方法将数据流存放在内存中,有利于高效的迭代运算