、HDFS是什么
二、HDFS的搭建
三、HDFS的组成
四、HDFS的存储流程和原理
五、HDFS的shell命令
一、HDFS是什么
HDFS是hadoop集群中的一个分布式的我文件存储系统。他将多台集群组建成一个集群,进行海量数据的存储。为超大数据集的应用处理带来了很多便利。
和其他的分布式文件存储系统相比他有以下优点:
高容错:即在HDFS运行过程中,若其中一台机器宕机了,也无需担心数据的丢失,因为在存储的过程中进行了备份,备份数量可以选择,这个将在后面的博客说明。
成本低:即使配置条件不足的情况下,都可以搭建一个HDFS,对硬件的要求不高。
易扩展:若出现集群容量不足的情况,直接添加机器,进行配置即可,无需太麻烦的操作。
高吞吐量:HDFS能够提供比较吞吐量的数据访问,这里是访问不是修改
在满足以上有点的同时,也存在一些不足:
对于对数据的访问时间要求较高的情况下,HDFS并没有什么优势,这一点会在原理上进行解释。
不利于同时有大量的用用户进行文件的修改操作。
二、HDFS的平台搭建
搭建HDFS集群的方式有很多种,目前在企业工作中应用较多的是通过cloudera manager来对整个hadoop集群进行搭建,同时提供一整套的监控平台进行监控,大大提高了维护成本。但是对于初学者来说还是进行源码的方式安装
这样有助于大家更加深入的了解HDFS的工作原理和配置参数的作用,小编在这就通过这种方式进行安装,当然如果有兴趣的读者,我会在接下来的时间通过cloudera manager的方式进行搭建。
搭建准备:注意这是在linux机器上进行搭建,如对如何配置linux环境的同学不动的话,可以在网上进行搜索,小编也会更新博文给大家提供便利。
主机名:hdp-01 对应的ip地址:192.168.33.61 主机名:hdp-02 对应的ip地址:192.168.33.62 主机名:hdp-03 对应的ip地址:192.168.33.63 主机名:hdp-04 对应的ip地址:192.168.33.64
第一步:关闭防火墙
[root@hdp1 ~]# service iptables stop # 临时关闭
[root@hdp1 ~]# chkconfig iptables off # 关闭防火墙开机自动启动
第二步:安装jdk,因为hdfs是通过java语言开发的,所以需要我们安装java的运行环境
jdk下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
tar -zxvf jdk-8u191-linux-x64.tar.gz
对应整个集群环境,为了方便管理可以将安装包上传到 /usr/local/src下面
解压:
二、HDFS数据存储原理
要了解HDFS数据的存储原理,就必须知道HDFS的工作原理,通过工作原理,我们就可以得出HDFS的数据存储原理。
hdfs有着文件系统共同的特征:
1、有目录结构,顶层目录是: /
2、系统中存放的就是文件
3、系统可以提供对文件的:创建、删除、修改、查看、移动等功能
hdfs跟普通的单机文件系统有区别:
1、单机文件系统中存放的文件,是在一台机器的操作系统中
2、hdfs的文件系统会横跨N多的机器
3、单机文件系统中存放的文件,是在一台机器的磁盘上
4、hdfs文件系统中存放的文件,是落在n多机器的本地单机文件系统中(hdfs是一个基于linux本地文件系统之上的文件系统)
hdfs的工作机制:简单的讲,hdfs是分布式的文件存储系统,它可以将一个大的文件切块,将这些块存储在不同的服务器上。
1、客户把一个文件存入hdfs,其实hdfs会把这个文件切块后,分散存储在N台linux机器系统中(负责存储文件块的角色:datanode)<准确来说:切块的行为是由客户端决定的>,切块的大小,切块的副本数这些都可以由
客户端进行指定,若没有进行指定,则HDFS会自动加载配置文件中配置的信息,进行切块大小,副本数量信息。
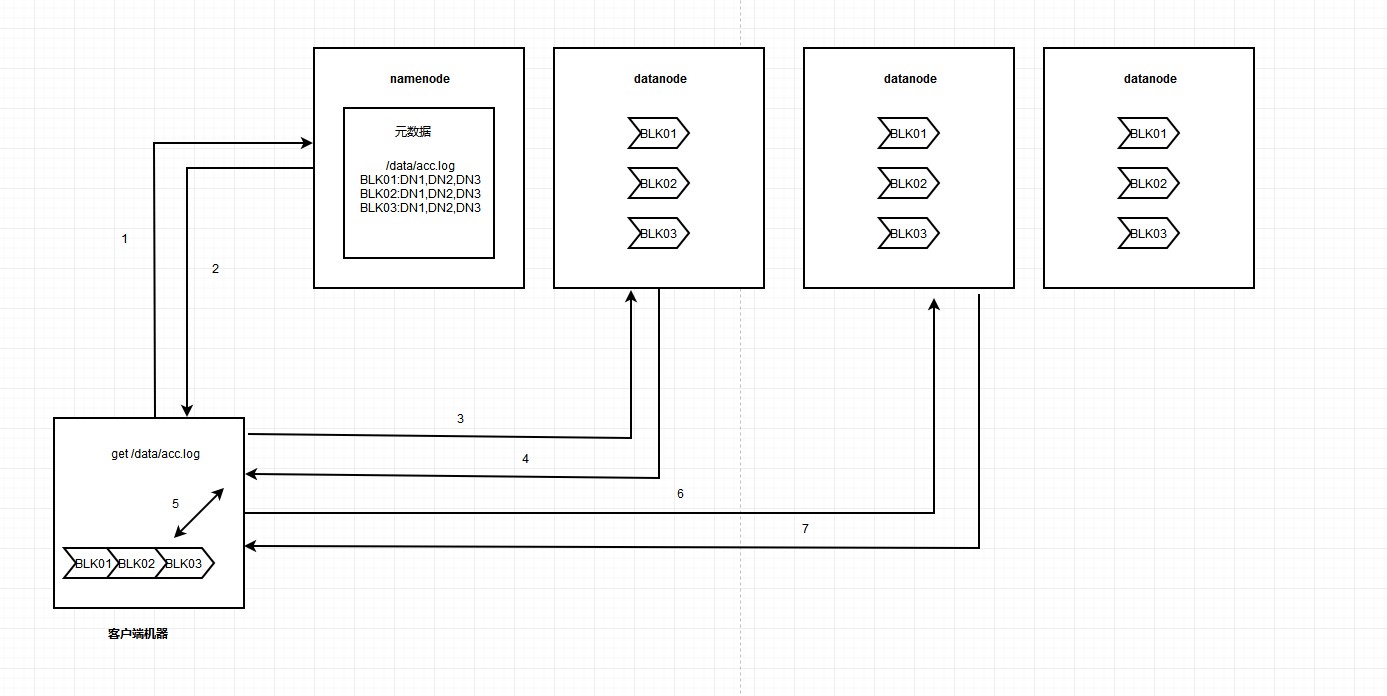
2、一旦文件被切块存储,那么,hdfs中就必须有一个机制,来记录用户的每一个文件的切块信息,及每一块的具体存储机器(负责记录块信息的角色是:name node),这样可以方便客户端在访问hdfs文件系统时准确的
找到每一块文件存储在哪些节点上,将切块的数据进行归整,同时他又可以合理的控制磁盘IO问题。
3、为了保证数据的安全性,hdfs可以将每一个文件块在集群中存放多个副本,保证当其中一台机器宕机后,namenode可以通过记录的副本信息找到切块的文件。(到底存几个副本,是由当时存入该文件的客户端指定的)
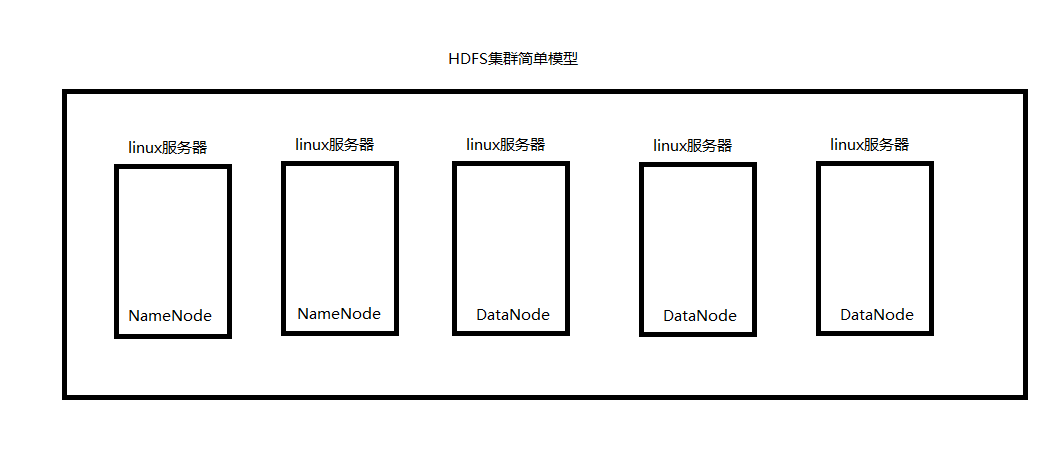
综述:一个hdfs系统,由一台运行了namenode的服务器,和N台运行了datanode的服务器组成!
如下图所示,就是一个简单的HDFS分布式文件系统的模型:
存储文件的详情:请看下图
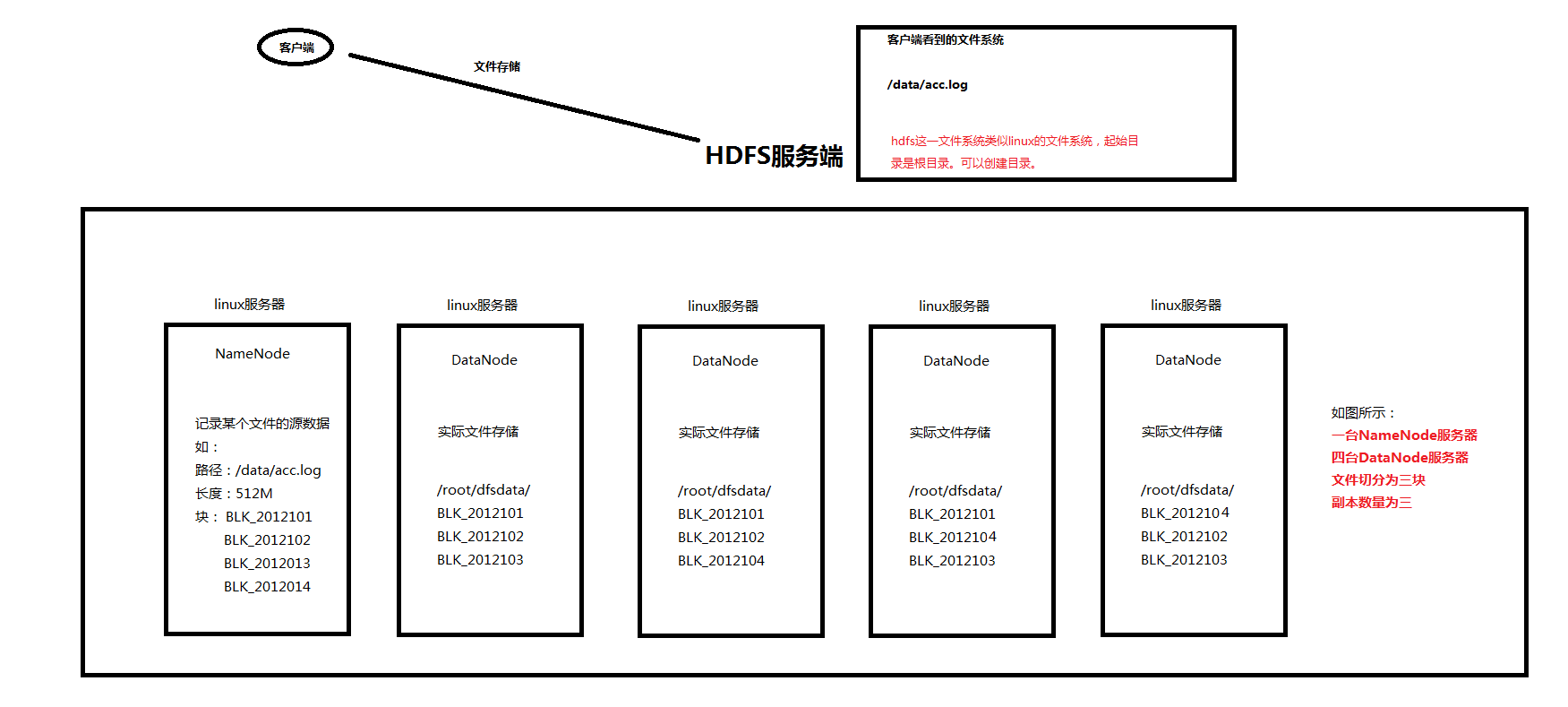
HDFS文件存储信息:
1、hdfs客户端与服务端进行交互,将文件存储在hdfs集群中。
2、hdfs服务端将客户端传来的文件,根据参数进行切块、复制,并将这些块存储在hdfs的datanode节点中。
3、hdfs的namenode节点记录某个文件的元数据(元数据包含文件大小,文件路径,文件块存储在哪个地方,副本信息等)
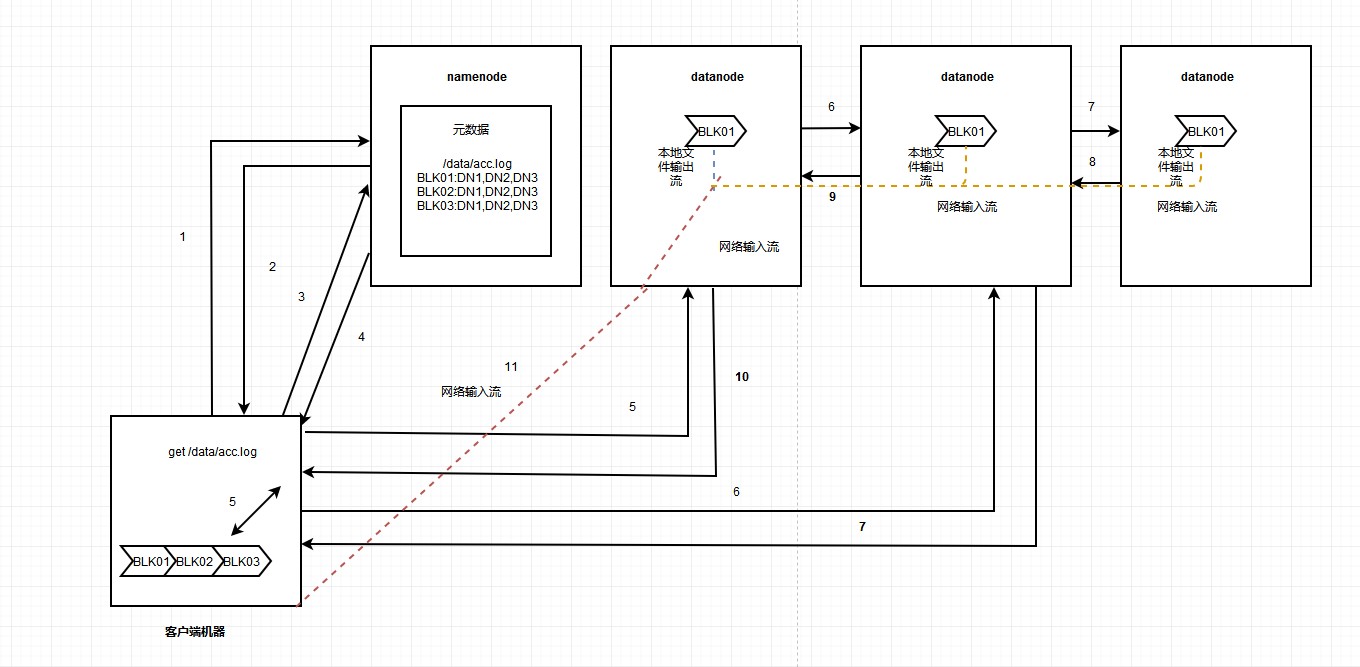
HDFS读取数据流程如下图:
HDFS写数据流程数据流程如下图: