最近在学数据挖掘的相关基础知识,希望对学习的内容进行整理,以下转自很棒的师兄的博客~
一趟聚类简介
一趟聚类算法是由蒋盛益教授提出的无监督聚类算法,该算法具有高效,简单的特点。数据集只需要遍历一遍即可完成聚类。算法对超球状分布的数据有良好的识别,对凸型数据分布识别较差。 一趟聚类可以在大规模数据,或者二次聚类中,或者聚类与其他算法结合的情况下,发挥其高效,简单的特点
算法流程
1.初始时从数据集读入一个新的对象
2.以这个对象构建一个新的簇
3.若达到数据集末尾,则转6,否则读入一个新的对象;计算它与每个已4有簇之间的距离,并选择与它距离最小的簇
4.若最小距离超过给定的阈值r,转2
5.否则将对象并入该簇,并更新簇心,转3
6.结束
距离公式
在本算法中,我采用的是欧氏距离公式计算节点与簇心之间的距离
欧氏距离公式

在python代码中,使用numpy包可以轻易地实现
import numpy as np
def euclidian_distance(vec_a, vec_b):
return np.sqrt(np.sum(np.square(np.array(vec_a) - vec_b)))代码实现
def clustering(self):
self.cluster_list.append(ClusterUnit()) # 初始新建一个簇
self.cluster_list[0].add_node(0, self.vectors[0]) # 将读入的第一个节点归于该簇
for index in range(len(self.vectors))[1:]:
min_distance = euclidian_distance(vec_a=self.vectors[0],
vec_b=self.cluster_list[0].centroid) # 与簇的质心的最小距离
min_cluster_index = 0 # 最小距离的簇的索引
for cluster_index, cluster in enumerate(self.cluster_list[1:]):
# 寻找距离最小的簇,记录下距离和对应的簇的索引
distance = euclidian_distance(vec_a=self.vectors[index],
vec_b=cluster.centroid)
if distance < min_distance:
min_distance = distance
min_cluster_index = cluster_index + 1
if min_distance < self.threshold: # 最小距离小于阀值,则归于该簇
self.cluster_list[min_cluster_index].add_node(index, self.vectors[index])
else: # 否则新建一个簇
new_cluster = ClusterUnit()
new_cluster.add_node(index, self.vectors[index])
self.cluster_list.append(new_cluster)
del new_cluster实验
实验说明
现有中国天气的数据集,数据包括中国各个城市每年的最低和最高温以及该城市的x,y坐标。
现在分别使用nltk包中自带的k-mean聚类算法和上述的一趟聚类算法对中国城市的气温情况进行聚类。每个城市的属性只考虑2个属性分别为最高气温和最低气温。
最后使用matplotlib包对聚类结果进行构图。
其中k-means,初始设定的k的个数为5; 一趟聚类,阈值初始设置为9,最后聚类出10个簇。
实验结果
运行时间
针对该份数据集,通过多次运行计算运行时间求平均值
得出:
k-means: 0.00024s
one-pass cluster: 0.00008s
不难看出一趟聚类由于算法自身的简单,运行速度相比于k-means有显著的提升。
聚类效果
不能只看运行时间,我们同样也要观察聚类的效果如何。现有2幅分别为k-means和一趟聚类的效果图。
k-means聚类效果图

一趟聚类效果图

中国年平均气温图
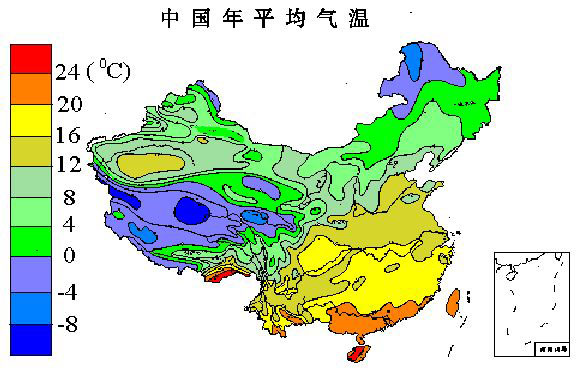
通过简单的目测对比可得,一趟聚类和k-means聚类的效果都能够有效地反映出中国气温的分布。综上所述,一趟聚类是一种较为有效的聚类算法,考虑到它的算法简单,该算法在处理大数据上有着显著的优越性。
完整代码