图(graph)对于理解tensorflow程序的结构十分重要,是tensorboard的重要组成部分,今天主要记录自己在学习图的使用过程中的一些心得。
一、认识图中的基本元素
要使用图,我们首先要理解图中的一些基本的元素。
1)命名空间
这个叫tf.name_scope,是tensorflow中层次较高的节点(node)。
2)操作符节点
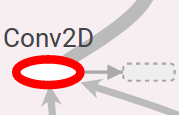
这个叫OpNode,他代表一个操作,或者说是运算,函数,输入的张量是这个函数的自变量,通过函数运算后输出。
3)常量

这个叫constant,他代表一个常量,也就是一个常数。
4)数据流边
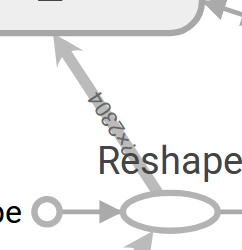
这里面的带箭头的线叫dataflow edge,是数据流边,表示张量数据流向箭头所指的节点,线段的宽度代表了张量的维度,维度越多越宽。
如果线段变成了虚线,就变成了控制依赖边,表示箭头尾部对箭头头部的控制、依赖关系。
5)参考边
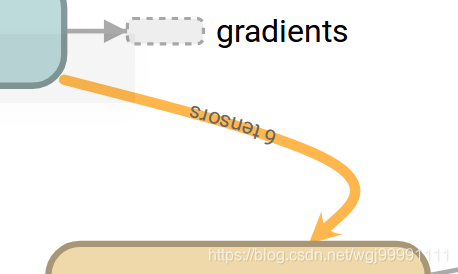
这个黄色的边叫Reference edge ,表示箭头所指的节点可以调整、优化输入过来的张量。(这里理解不是很清楚?每个节点不都是有这样的能力吗?mutate用在这里到底是什么含义?)
以上就是常用到的一些基本的图形,当然还有其他的一些,用到的时候可以自己查。
- 二、如何构建图
首先要明确,图中所显示的一切都是我们构建出来的。构建图的过程,就是在程序中加入name_scope,以及给函数命名的过程。你的name_scope加的好,你的图就看起来层次清晰,反之,图就不好看。
经验:
第一步,构建层类,把卷积层、池化层、全连接层等都变成类,这些层类可以通过读取配置文件来初始化。 这样就可以通过写配置文件的方式来初始化多个层。
第二步,在读取配置文件初始化时,给每一个层命名,然后把该层配置过程中的重要操作放在一个name_scope下,把该层执行过程中的主体操作放在一个name_scope下。
这样,形成的图层次结构就比较清晰。
1)name_scope
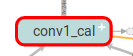
在某个函数中加上name_scope,则在图中就会是一个NameSpace节点
def get_output(self, inputs, is_training=True):
with tf.name_scope('%s_cal' % (self.name)) as scope:
self.hidden = self.conv(inputs=inputs)
if self.batch_normal:
self.hidden = self.bn(self.hidden, training=is_training)
return self.output
这段代码给get_output函数的主要代码加上了name_scope,则在图中就会显示如下一个节点。
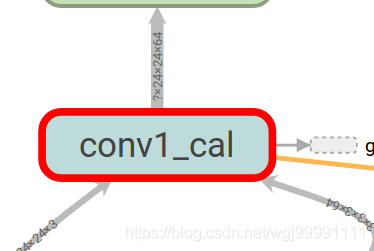
2)命名函数
命名函数,图中就会显示函数的节点。
self.bn = tf.layers.BatchNormalization(
axis=-1,
momentum=0.9,
epsilon=1e-5,
center=True,
scale=True,
beta_initializer=tf.constant_initializer(beta_init_value),
gamma_initializer=tf.constant_initializer(gamma_init_value),
moving_mean_initializer=tf.constant_initializer(moving_mean_init_value),
moving_variance_initializer=tf.constant_initializer(moving_variance_init_value),
trainable=True,
name='%s_bn' % (self.name))
这段代码对函数tf.layers.BatchNormalization进行了命名
name=’%s_bn’ % (self.name)),则在图中就会显示如下一个节点:
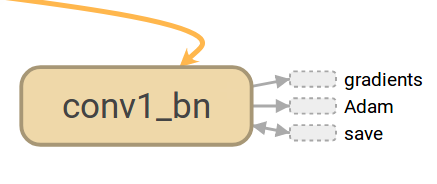
- 三、如何看图
下面我们就事论事,具体对一个比较好的图进行分析,看看能看到什么东西。
1) 一副图从整体上来看是这样的,分为两个区,左边是主图区,右边是从属区。
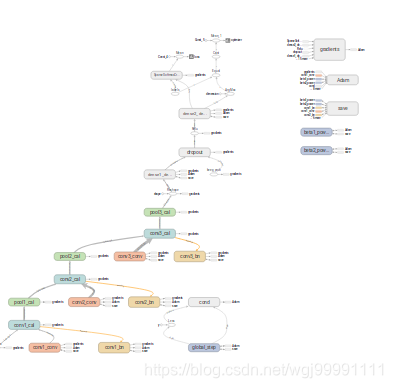
2)从图中可以看出,张量(数据)是从下向上流动的。并且这个图是分层的,我们能看到每一层的主要操作。

3)在图的最上方,张量(数据)会分到两个方向,一边是损失函数,另一边是预测精度。
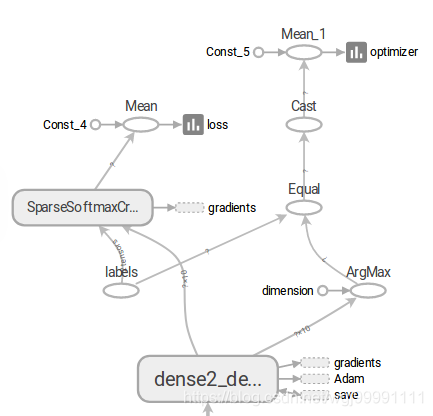
4)损失函数的值我们希望其越来越低,预测精度我们希望其越来越高,这里面还有个一反向传播的问题,虽然我们在程序中没有设计到反向传播的图形标注代码,但这个系统是自己生成的,反向传播的过程是通过数据输入gradients节点来实现的。我们可以看到有很多节点都向gradients节点输出数据了,这里描述的就是一个反向传播优化权重值的过程。
而Adam则表示模型的寻优算法的变化过程。
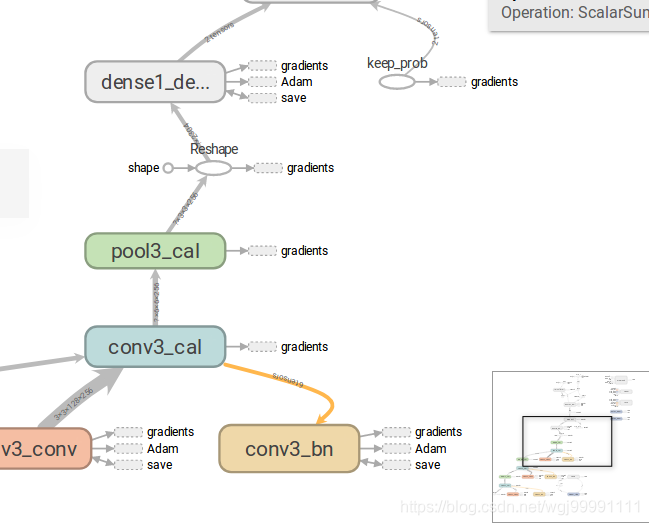
5)信息采集点

这个图左边是一个节点,一个数据流边,然后一个Summary节点,表示我们会采集这个节点计算过后的数据,并会把数据显示在tensorboard中。看到这个东西,就表示这时我们的一个数据采集点。
也可以说,如果你认为那个节点的数据需要采集,作为我们调优的依据,就把他记下来,然后在程序中加代码,把这个节点数据采集下来。
6)高频节点和从属区
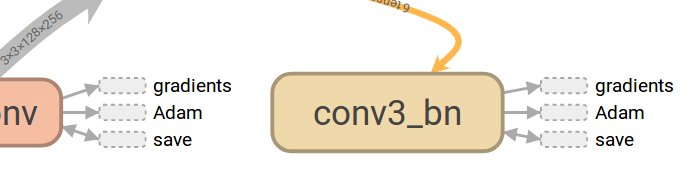
图中这些用虚线框起来的节点称之为高频节点(high-degree)(这个中文是自己翻译的,可能不准确),由于这些节点与图中的其他很多节点都有连接关系,如果都表示出来就会显得图很乱,所以就把这些节点显示在图右上角的从属区,而在主图中采取这种方式表示其他节点与高频节点之间的关系。从属区如下图所示:

右侧的这个就是从属区。