有如下 Pandas DataFrame:
-
import pandas as pd -
inp = [{'c1':10, 'c2':100}, {'c1':11,'c2':110}, {'c1':12,'c2':120}] -
df = pd.DataFrame(inp) -
print df
上面代码输出:
-
c1 c2 -
0 10 100 -
1 11 110 -
2 12 120
现在需要遍历上面DataFrame的行。对于每一行,都希望能够通过列名访问对应的元素(单元格中的值)。也就是说,需要类似如下的功能:
-
for row in df.rows: -
print row['c1'], row['c2']
Pandas 可以这样做吗?
我找到了similar question。但这并不能给我需要的答案,里面提到:
for date, row in df.T.iteritems():
要么
for row in df.iterrows():
但是我不明白row对象是什么,以及我如何使用它。
最佳解决方案
要以 Pandas 的方式迭代遍历DataFrame的行,可以使用:
-
-
for index, row in df.iterrows(): -
print row["c1"], row["c2"]
-
-
-
for row in df.itertuples(index=True, name='Pandas'): -
print getattr(row, "c1"), getattr(row, "c2")
-
itertuples()应该比iterrows()快
但请注意,根据文档(目前 Pandas 0.19.1):
-
iterrows:数据的
dtype可能不是按行匹配的,因为iterrows返回一个系列的每一行,它不会保留行的dtypes(dtypes跨DataFrames列保留)* -
iterrows:不要修改行
你不应该修改你正在迭代的东西。这不能保证在所有情况下都能正常工作。根据数据类型的不同,迭代器返回一个副本而不是一个视图,写入它将不起作用。
new_df = df.apply(lambda x: x * 2) -
itertuples:列名称将被重命名为位置名称,如果它们是无效的Python标识符,重复或以下划线开头。对于大量的列(> 255),返回常规元组。
第二种方案: apply
您也可以使用df.apply()遍历行并访问函数的多个列。
-
def valuation_formula(x, y): -
return x * y * 0.5 -
df['price'] = df.apply(lambda row: valuation_formula(row['x'], row['y']), axis=1)
第三种方案:iloc
您可以使用df.iloc函数,如下所示:
-
for i in range(0, len(df)): -
print df.iloc[i]['c1'], df.iloc[i]['c2']
第四种方案:略麻烦,但是更高效,将DataFrame转为List
您可以编写自己的实现namedtuple的迭代器
-
from collections import namedtuple -
def myiter(d, cols=None): -
if cols is None: -
v = d.values.tolist() -
cols = d.columns.values.tolist() -
else: -
j = [d.columns.get_loc(c) for c in cols] -
v = d.values[:, j].tolist() -
n = namedtuple('MyTuple', cols) -
for line in iter(v): -
yield n(*line)
这相当于pd.DataFrame.itertuples,但是效率更高。
将自定义函数用于给定的DataFrame:
-
list(myiter(df)) -
[MyTuple(c1=10, c2=100), MyTuple(c1=11, c2=110), MyTuple(c1=12, c2=120)]
或与pd.DataFrame.itertuples:
-
list(df.itertuples(index=False)) -
[Pandas(c1=10, c2=100), Pandas(c1=11, c2=110), Pandas(c1=12, c2=120)]
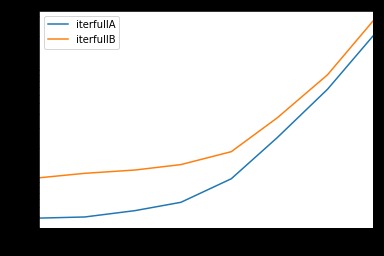
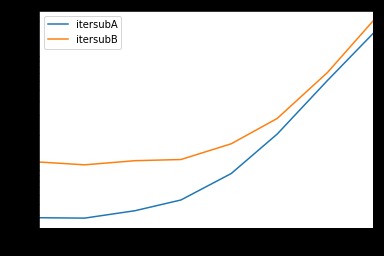
全面的测试
我们测试了所有可用列:
-
def iterfullA(d): -
return list(myiter(d)) -
def iterfullB(d): -
return list(d.itertuples(index=False)) -
def itersubA(d): -
return list(myiter(d, ['col3', 'col4', 'col5', 'col6', 'col7'])) -
def itersubB(d): -
return list(d[['col3', 'col4', 'col5', 'col6', 'col7']].itertuples(index=False)) -
res = pd.DataFrame( -
index=[10, 30, 100, 300, 1000, 3000, 10000, 30000], -
columns='iterfullA iterfullB itersubA itersubB'.split(), -
dtype=float -
) -
for i in res.index: -
d = pd.DataFrame(np.random.randint(10, size=(i, 10))).add_prefix('col') -
for j in res.columns: -
stmt = '{}(d)'.format(j) -
setp = 'from __main__ import d, {}'.format(j) -
res.at[i, j] = timeit(stmt, setp, number=100) -
res.groupby(res.columns.str[4:-1], axis=1).plot(loglog=True);