1、CNN-based Cascaded Multi-task Learning of High-level Prior and Density Estimation for Crowd Counting
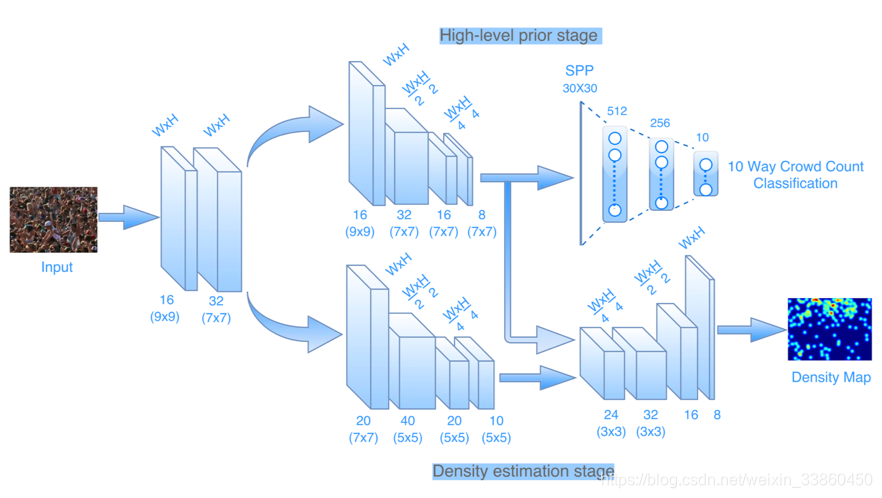
Two sub tasks: crowd count classification and density map estimation,First stage learning high level prior ,Second stage preforming density map estimation。即上层为人头数分类,下层输出密度图
2、Cross-scene Crowd Counting via Deep Convolutional Neural Networks

3个卷积层 3个全连接层。第一个卷积层有 32个 7×7×3 滤波器,第二个卷积层 32个 7×7×32 滤波器,第三个卷积层有64个 5 × 5 × 32 滤波器。第一第二卷积层后面各用一个 2 × 2 最大池化,卷积和全连接层都使用 Rectified linear unit (ReLU) 激活响应函数。交替优化密度图估计任务和人数估计任务
3、CrowdNet: A Deep Convolutional Network for Dense Crowd Counting
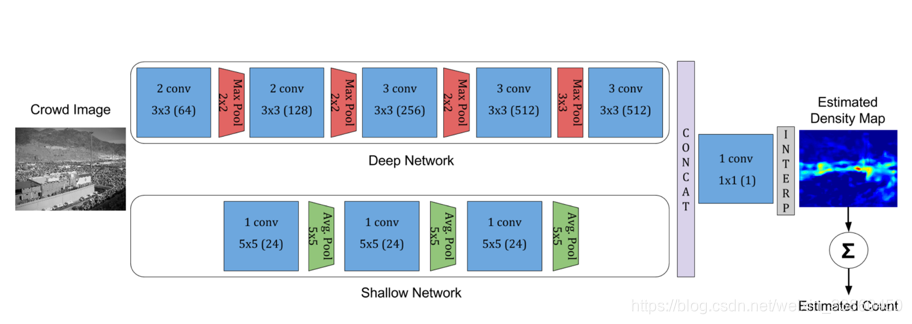
似乎两个网络分支最后融合,一个尺度小的卷积核一个尺度大的卷积核,多层小的卷积核不是能等同于大的卷积核?
4、Highly Congested Scenes Single-Image Crowd Counting via Multi-Column Convolutional Neural Network
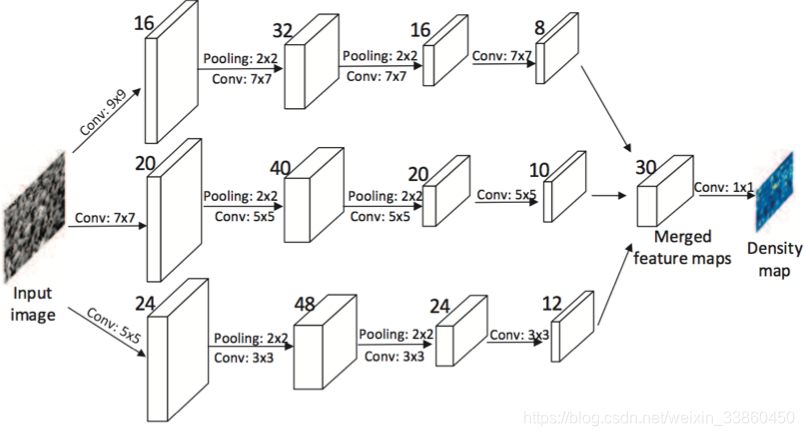
MCNN网络的每一列并行的子网络深度相同,但是滤波器的大小不同(大,中,小),因此每一列子网络的感受野不同,能够抓住不同大小人头的特征,最后将三列子网络的特征图做线性加权(由1x1的卷积完成)得到该图像的人群密度图,类似模型融合的思想。采用了2*2的max-pooling和ReLU激活函数。(注意,因为这里用到了两次max-pooling,所以需要先对训练样本也缩小到1/4,再生成对应的密度图ground truth)。使用基于几何适应高斯核的密度图
5、Switching Convolutional Neural Network for Crowd Counting
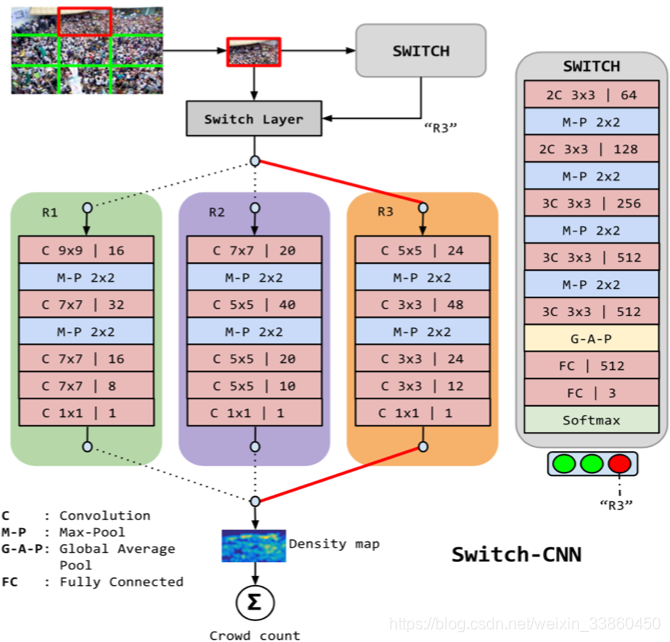
针对人群密度估计问题提出了一个 Switch-CNN网络,大的思路就是根据图像块的内容信息来选择合适的CNN网络进行人群密度估计。首先将图像分成3*3=9 个图像块,然后使用一个 CNN网络对每个图像块进行分类,看它适合使用哪个CNN网络来进行密度估计,这里提供了3个CNN网络来进行密度估计
6、DecideNet: Counting Varying Density Crowds Through Attention Guided Detection and Density Estimation
整体网络:

Detect:

将 Faster-RCNN 应用到人头检测,在网络后面加了一个 Gaussian convolutional layer 将检测框转为密度图
Destiny:

Attention:

有两个密度图,如何将这两个密度图融合起来了?这里使用一个小网络来学习这个权重系数
在人群密度小的时候,基于检测的方法效果更好。在人群密度较大的时候,基于回归方法的效果比较好。
7、Crowd counting via scale-adaptive convolutional neural network
整体网络:

We build a single backbone network with a single filter size. We combine the feature maps of multiple layers to adapt the network to the changes in pedestrian scale and perspective. Multi-scale layers share the same low-level parameters and feature representa- tions, which results in fewer parameters, fewer training data required, and faster training. We introduce two loss functions to jointly optimize the model: one is density map loss, the other is relative count loss. The relative count loss helps to reduce the variance of the prediction errors and improve the network generalization on very sparse crowd scenes.
提出一个自使用网络,端到端,单一尺寸3*3卷积核

8、Learning a perspective-embedded deconvolution network for crowd counting

网络的输入是 RGB,基于语义分割框架 FCN的 baseline model,加了两个卷积层 conv5 with 5 × 5和conv6 with 7 × 7,加入Perspective进行视角矫正。
9、Generating High-Quality Crowd Density Maps using Contextual Pyramid CNNs
对于以前各种方法分析,我们认为有以下几点问题:
1)这些方法都没有显示的嵌入 context 信息,而 context 信息对提升性能很有帮助
2)当前基于回归的密度图估计方法更侧重降低人群总数估计误差,而不是侧重人群密度图的质量
3)当前的 CNN 网络基本都是使用 像素级欧式损失函数来训练网络,这导致密度图比较模糊

使用GCE和LCE融合global和local的context信息,两者和DME进行融合并进一步处理。DMP获得高清密度图,F-CNN 综合GCE 、LCE 、 DME的结果;

Global context基于VGG,将整体图像输出成不同图像密度等级
将 global context 和图像的密度等级联系起来,这里我们将图像人群密度等级分为五类:extremely low-density (ex-lo), low-density (lo), medium-density (med), high-density (hi) and extremely high-density (ex-hi)
当然具体分多少类 这个和数据库密度变化范围有关,但是我们发现仅适用五类就可以明显提升密度图估计效果

Local context,将图像小块输出成不同等级的密度图,这样就包含了local ontext信息。我们相信 some kind of local contextual information 能够帮助我们提升密度图质量。和 GCE 思路类似,使用一个 CNN网络 将图像根据其人群密度分为5类, {ex-lo, lo,med, hi, ex-hi}

密度图映射,DMP为多列结构。
Fusion-CNN (F-CNN)则将前面学习到的3类特征组合起来。
10、Crowd Counting via Adversarial Cross-Scale Consistency Pursuit

使用方法:
1、使用了一个U-net的生成网络来设计生成密度图;
2、采用了一种对抗损失,将solution 映射到真实子空间内,从而减少了密度图估计的模糊效果
3、另外,设计了一种新的一致性调节方式,使得人群的总和,可以从小的图片中计算出来,再和全局图片来对比,使得数量一致;
4、最后这里是通过联合训练,通过两者的合作来提高密度估计性能。
以往的缺点,以往的人群记数是通过不同的卷积核来衡量大小:
1、因此只有L2范数来优化模型;
2、对离群值和图像的敏感性不足,图像过于模糊;
3、而且,不同的卷积子网络之间没有协助,只是试图最小化自己的估计,导致在其他的尺度上性能不好,没有追求尺度的一致性问题;
4、此外,卷积核为滑动窗口设计,所以局部补丁的丢失,会影响全局。
本文提出来的创新:
1、根据GANs在图像翻译上的思想,提出了一种对抗性损失,代替传统的L2范数损失,用于减轻optimization的模糊效应;
2、利用U-net 的多尺度架构,从而对于图像进行像素级翻译,即:一个像素点到密度图的像素点的映射。
3、提出了一种新的正则化器,用于校准跨尺度模型,并鼓励不同尺度的协同训练
4、使用两个互补密度图生成器,一个是大图像的输入,一个是将大图像切割后的小图像,通过大图像的记数=切割小图像记数的和,
博客链接:https://blog.csdn.net/uestcbyl/article/details/82666996
2018顶会:
11、Crowd Counting by Adaptively Fusing Predictions from an Image Pyramid
面临的挑战是:严重的遮挡;较大的尺度变化;视角畸变。使用多尺度图像来处理尺度变化问题。

不同尺度的图片送入FCN得出相应尺度的密度图;每个尺度以最后的特征图为输入输出一张注意力图;一个跨越各个尺度注意力图的softmax结果和各个尺度的密度图相乘;最后用1*1的卷积融合所有的密度图;各个尺度的FCN及注意力机制共享参数。
12、Iterative crowd counting

不同密度的人群

ic-CNN结构图,上一通道获取低分别率的密度图,并将特征图和得出的密度图传入下一条通道中,下一条通道则根据自身的特征加上低分辨率的特征和密度图得出高分辨率的密度图。
13、Scale Aggregation Network for Accurate and Efficient Crowd Counting

整体网络结构图,多尺度卷积提取特征,最后反卷积得出密度图;此处多尺度相当于把MCNN的三通道合成一个通道,每一步卷积都包含多尺度信息。在反卷积过程中也加入卷积操作,来喜欢特征图的细节。

多尺度卷积核,采用1×1, 3×3, 5×5, 7×7;损失函数采用L2和Local Pattern Consistency Loss相结合。
14、Top-Down Feedback for Crowd Counting Convolutional Neural Network
挑战:行人外表的变化性大。识别需要较大的空间上下文信息及场景语义信息。

15、CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes
整体网络为VGG+ Dilated convolutional,简单粗暴

目标检测值得参考的网络框架:
16、M2Det:A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
网络框架图:

FFMv1融合VGG4_3和VGG5_3特征作为基准特征,TUM产生多尺度的信息,而FFMv2则结合上层特征和TUM最后的特征图;TUM3层3*3卷积核,上采用并用1*1卷积进行特征融合

SLAM使用了注意力机制来引导融合特征通道时取到最优通道;

不同大小目标在不同尺度处得到检测