版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_24548569/article/details/83687881
CVPR2018论文:《Human-Machine Cooperation: Self-supervised Sample Mining 》
在许多应用场景中,已标注的数据集不是很多,但是未标注或部分标注的数据集非常多。在监督学习任务中,足够多的标注数据对模型来说至关重要,因此使用未标注和部分标注的数据集的想法越来越重要。但是为未标注或部分标注的数据进行标注的成本很高,因为通常需要人力来标注,而且未标注的数据太多。同时,挑选出可以提高模型表现的好样本不是一件简单的工作。论文提出了一种Self-supervised Sample Mining(SSM)框架,可以使用未标注或部分标注的数据训练模型。
SSM借鉴了自主学习、主动学习和自监督学习的思想。自主学习 (Self-paced Learning, SPL)起源于课程学习(Curriculum learning, CL),灵感来自于人的认知过程,先学习简单的知识(样本),然后总结归纳,再学习复杂的知识(样本),再总结归纳,如此重复学习。
自监督学习 (Self-supervised Learning, SSL)是使用没有额外的人工标注数据学习特征的表征,一般就是适合有未标注或部分标注数据集的任务。
主动学习 (Active Learning, AL)也是使用未标注或部分标注的数据的学习算法,但是AL重点在于主动提出标注请求,关注的是样本选择策略,关键是选择能够提高模型表现的好样本。目前的样本选择策略大概可以分成两种,分别是不确定性准则(uncertainty)和差异性准则(diversity)。信息熵越大,就代表不确定性越大,包含的信息量也就越丰富。不确定性策略就是要想方设法地找出不确定性高的样本,因为这些样本所包含的丰富信息量,对我们训练模型来说就是有用的。差异性策略是希望所选择的样本提供的信息是全面的,各个样本提供的信息不重复不冗余,即样本之间具有一定的差异性,避免样本信息冗余。
之前的工作在单个样本上下文之间计算样本选择指标,这种方法对模型偏差和样本数据类型不平衡问题很敏感,鲁棒性不行。SSM则可以在多个样本上下文之间计算样本选择指标,提高了方法的鲁棒性。而且之前的方法不支持mini-batch训练,但是SSM支持。
根据SSM设计的SSM框架可以使用未标注或部分标注的数据进行模型训练,而且可以最小化人力标注的成本。训练出来的模型的表现效果比当前先进的方法要好。
这是个人观点。因为SSM涉及AL,模型的训练过程需要人参与,为proposal人工标注,因此训练过程会变慢。对于一些很庞大的训练数据集(比如ImageNet),光是训练就要好几周。因为任务只有少量的已标注的数据集,因此SSM肯定需要迁移学习,SSM训练的过程只是fine-tune,但是SSM在每次mini-batch之后都要选择低一致性样本,通过人工标注低一致性样本,因此人工标注的速度对模型的训练速度有很大的影响。
论文提出的SSM框架的管道流图如下
我们先了解SSM使用的公式,从公式中获取框架的具体细节。
在物体检测问题中,假设我们有n个region proposals(指的是ground truth bb)和m个类别。定义训练集为
D
=
{
x
i
}
i
=
1
n
∈
R
d
\mathcal{D} = \{x_i\}_{i=1}^n \in R^d
D = { x i } i = 1 n ∈ R d
x
i
x_i
x i
x
i
x_i
x i
y
i
=
{
y
i
}
j
=
−
1
m
\mathbf{y}_i = \{y_i\}_{j=-1}^m
y i = { y i } j = − 1 m
y
i
(
j
)
∈
{
+
1
,
−
1
}
y_i^{(j)} \in \{+1, -1\}
y i ( j ) ∈ { + 1 , − 1 }
x
i
x_i
x i
大多数样本的标签
Y
=
{
y
i
}
i
=
1
n
\mathbf{Y} = \{y_i\}_{i=1}^n
Y = { y i } i = 1 n
I
\mathbf{I}
I
{
x
i
}
i
=
1
n
\{x_i\}_{i=1}^n
{ x i } i = 1 n
整个框架的损失函数为:
(1)
Loss
=
L
loc
(
W
)
+
L
cls
AL
(
W
)
+
L
cls
SSM
(
W
,
V
)
\text{Loss} = \mathcal{L}_{\text{loc}}(\mathbf{W}) + \mathcal{L}_{\text{cls}}^{\text{AL}}(\mathbf{W}) + \mathcal{L}_{\text{cls}}^{\text{SSM}}(\mathbf{W}, \mathbf{V}) \tag{1}
Loss = L loc ( W ) + L cls AL ( W ) + L cls SSM ( W , V ) ( 1 )
L
loc
(
W
)
\mathcal{L}_{\text{loc}}(\mathbf{W})
L loc ( W )
L
cls
AL
(
W
)
\mathcal{L}_{\text{cls}}^{\text{AL}}(\mathbf{W})
L cls AL ( W )
L
cls
SSM
(
W
,
V
)
\mathcal{L}_{\text{cls}}^{\text{SSM}}(\mathbf{W}, \mathbf{V})
L cls SSM ( W , V )
论文定义
L
cls
AL
(
W
)
=
1
∣
Ω
I
∣
∑
i
∈
Ω
I
∑
j
=
1
m
ℓ
i
(
x
i
,
W
)
\mathcal{L}_{\text{cls}}^{\text{AL}}(\mathbf{W}) = \frac{1}{ \left | \varOmega_I \right |} \sum_{i \in \varOmega_I} \sum_{j=1}^{m} \ell _i(x_i, \mathbf{W})
L cls AL ( W ) = ∣ Ω I ∣ 1 i ∈ Ω I ∑ j = 1 ∑ m ℓ i ( x i , W )
Ω
I
\varOmega_I
Ω I
I
∈
I
I \in \mathbf{I}
I ∈ I
ℓ
i
(
x
i
,
W
)
\ell _i(x_i, \mathbf{W})
ℓ i ( x i , W )
x
i
x_i
x i
ℓ
i
(
x
i
,
W
)
=
−
(
1
+
y
i
(
j
)
2
log
ϕ
j
(
x
i
;
W
)
+
1
−
y
i
(
j
)
2
log
(
1
−
ϕ
j
(
x
i
;
W
)
)
)
\ell _i(x_i, \mathbf{W}) = -\left ( \frac{1+y_i^{(j)}}{2} \log \phi_j (x_i; \mathbf{W}) + \frac{1-y_i^{(j)}}{2} \log (1 - \phi_j (x_i; \mathbf{W})) \right )
ℓ i ( x i , W ) = − ( 2 1 + y i ( j ) log ϕ j ( x i ; W ) + 2 1 − y i ( j ) log ( 1 − ϕ j ( x i ; W ) ) )
W
\mathbf{W}
W
ϕ
j
(
x
i
;
W
)
)
\phi_j (x_i; \mathbf{W}))
ϕ j ( x i ; W ) )
x
i
x_i
x i
y
i
(
j
)
∈
{
+
1
,
−
1
}
y_i^{(j)} \in \{ +1, -1\}
y i ( j ) ∈ { + 1 , − 1 }
接着讲
L
cls
SSM
(
W
,
V
)
\mathcal{L}_{\text{cls}}^{\text{SSM}}(\mathbf{W}, \mathbf{V})
L cls SSM ( W , V )
x
i
x_i
x i
y
i
\mathbf{y}_i
y i
V
=
{
v
(
j
)
}
j
=
1
m
=
{
[
v
1
(
j
)
,
⋯
 
,
v
n
(
j
)
]
T
}
j
=
1
m
\mathbf{V} = \{ v^{(j)}\}_{j=1}^{m} = \{ [v_1^{(j)}, \cdots, v_n^{(j)}]^T \}_{j=1}^m
V = { v ( j ) } j = 1 m = { [ v 1 ( j ) , ⋯ , v n ( j ) ] T } j = 1 m
(2)
L
cls
SSM
(
W
,
V
)
=
1
∣
Ω
I
‾
∣
∑
i
∈
Ω
I
‾
∑
j
=
1
m
(
v
i
(
j
)
ℓ
j
(
x
i
,
W
)
+
R
(
x
i
,
v
i
(
j
)
,
W
)
)
s
.
t
.
∑
j
=
1
m
∣
y
i
(
j
)
+
1
∣
≤
2
,
y
i
(
j
)
∈
{
−
1
,
+
1
}
\mathcal{L}_{\text{cls}}^{\text{SSM}}(\mathbf{W}, \mathbf{V}) = \frac{1}{\left | \overline{\varOmega_I} \right |} \sum_{i \in \overline{\varOmega_I}} \sum_{j=1}^{m} \left ( v_i^{(j)} \ell_j (x_i, \mathbf{W}) + R(x_i, v_i^{(j)}, \mathbf{W}) \right ) s.t. \sum_{j=1}^{m} \left | y_i^{(j)} + 1 \right | \le 2, y_i^{(j)} \in \{ -1, +1\} \tag{2}
L cls SSM ( W , V ) = ∣ ∣ Ω I ∣ ∣ 1 i ∈ Ω I ∑ j = 1 ∑ m ( v i ( j ) ℓ j ( x i , W ) + R ( x i , v i ( j ) , W ) ) s . t . j = 1 ∑ m ∣ ∣ ∣ y i ( j ) + 1 ∣ ∣ ∣ ≤ 2 , y i ( j ) ∈ { − 1 , + 1 } ( 2 )
Ω
I
‾
\overline{\varOmega_I}
Ω I
y
i
\mathbf{y}_i
y i
R
(
⋅
)
R(\cdot)
R ( ⋅ )
(3)
R
(
x
i
,
v
i
(
j
)
,
W
)
=
−
f
(
x
i
,
W
)
v
i
(
j
)
R(x_i, v_i^{(j)}, \mathbf{W}) = -f(x_i, W)v_i^{(j)} \tag{3}
R ( x i , v i ( j ) , W ) = − f ( x i , W ) v i ( j ) ( 3 )
(4)
v
i
(
j
)
=
{
1
,
ℓ
j
(
x
i
,
W
)
≤
f
(
x
i
,
W
)
0
,
otherwise
v_i^{(j)} = \begin{cases} 1, \ell_j (x_i, \mathbf{W}) \le f(x_i, \mathbf{W}) \\ 0, \text{otherwise} \end{cases} \tag{4}
v i ( j ) = { 1 , ℓ j ( x i , W ) ≤ f ( x i , W ) 0 , otherwise ( 4 )
f
(
⋅
)
f(\cdot)
f ( ⋅ )
(5)
f
(
x
i
,
W
)
=
λ
∣
Ω
I
j
‾
∣
∑
p
∈
Ω
I
j
‾
1
(
IoU
(
B
I
(
x
i
)
,
B
I
(
x
p
)
)
≥
γ
)
ϕ
j
(
x
p
;
W
)
)
f(x_i, \mathbf{W}) = \frac{\lambda}{\left | \varOmega_I^{\overline{j}} \right |} \sum_{p \in \varOmega_I^{\overline{j}}} \mathbf{1} (\text{IoU}(B_I(x_i), B_I(x_p)) \ge \gamma) \phi_j (x_p; \mathbf{W})) \tag{5}
f ( x i , W ) = ∣ ∣ ∣ Ω I j ∣ ∣ ∣ λ p ∈ Ω I j ∑ 1 ( IoU ( B I ( x i ) , B I ( x p ) ) ≥ γ ) ϕ j ( x p ; W ) ) ( 5 )
x
i
x_i
x i
x
i
x_i
x i
B
I
(
x
p
)
B_I(x_p)
B I ( x p )
B
I
(
x
q
)
B_I(x_q)
B I ( x q )
x
p
x_p
x p
x
q
x_q
x q
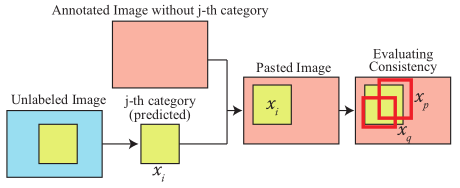
如果预测为j类的
x
i
x_i
x i
x
i
x_i
x i
x
i
x_i
x i
x
i
x_i
x i
x
i
x_i
x i
x
p
x_p
x p
x
q
x_q
x q
x
p
x_p
x p
x
q
x_q
x q
x
i
x_i
x i
现在说明公式(5)的符号,
Ω
I
j
‾
\varOmega_I^{\overline{j}}
Ω I j
λ
\lambda
λ
B
I
(
x
i
)
B_I(x_i)
B I ( x i )
x
i
x_i
x i
IoU
(
B
I
(
x
i
)
,
B
I
(
x
p
)
)
\text{IoU}(B_I(x_i), B_I(x_p))
IoU ( B I ( x i ) , B I ( x p ) )
B
I
(
x
i
)
B_I(x_i)
B I ( x i )
B
I
(
x
p
)
B_I(x_p)
B I ( x p )
γ
\gamma
γ
1
(
⋅
)
\mathbf{1}(\cdot)
1 ( ⋅ )
如果
x
i
x_i
x i
f
(
⋅
)
f(\cdot)
f ( ⋅ )
ℓ
j
(
x
i
,
W
)
≤
f
(
x
i
,
W
)
\ell_j (x_i, \mathbf{W}) \le f(x_i, \mathbf{W})
ℓ j ( x i , W ) ≤ f ( x i , W )
v
i
(
j
)
=
1
v_i^{(j)} = 1
v i ( j ) = 1
开始讲模型的优化过程。论文中通过SSM过程更新样本权重
V
\mathbf{V}
V
Y
\mathbf{Y}
Y
W
\mathbf{W}
W
更新
V
\mathbf{V}
V :固定
{
Y
,
X
,
W
}
\{ \mathbf{Y}, \mathbf{X}, \mathbf{W}\}
{ Y , X , W }
f
(
x
i
,
W
)
f(x_i, \mathbf{W})
f ( x i , W )
V
\mathbf{V}
V
更新
Y
\mathbf{Y}
Y :更新
V
\mathbf{V}
V
s
i
s_i
s i
(6)
s
i
=
1
∣
I
∣
∑
I
∈
I
1
∣
Ω
I
j
∗
‾
∣
∑
p
∈
Ω
I
j
∗
‾
ϕ
j
∗
(
x
p
;
W
)
s_i = \frac{1}{\left | \mathbf{I} \right |} \sum_{I \in \mathbf{I}} \frac{1}{\left | \varOmega_I^{\overline{j^*}} \right |} \sum_{p \in \varOmega_I^{\overline{j^*}}} \phi_{j^*} (x_p; \mathbf{W}) \tag{6}
s i = ∣ I ∣ 1 I ∈ I ∑ ∣ ∣ ∣ Ω I j ∗ ∣ ∣ ∣ 1 p ∈ Ω I j ∗ ∑ ϕ j ∗ ( x p ; W ) ( 6 )
j
∗
j^*
j ∗
j
∗
=
arg
max
j
∈
[
m
]
ϕ
j
(
x
p
,
W
)
j^* = \arg \underset{j \in [m]}{\max} \phi_j (x_p, W)
j ∗ = arg j ∈ [ m ] max ϕ j ( x p , W )
j
∗
=
arg
max
j
∈
[
m
]
ϕ
j
(
x
i
,
W
)
j^* = \arg \underset{j \in [m]}{\max} \phi_j (x_i, W)
j ∗ = arg j ∈ [ m ] max ϕ j ( x i , W )
x
i
x_i
x i
x
i
x_i
x i
N
=
5
N=5
N = 5
计算所有挑选出来的
x
i
x_i
x i
s
i
s_i
s i
S
=
{
s
i
}
i
=
1
m
S = \{s_i\}_{i=1}^m
S = { s i } i = 1 m
H
\mathcal{H}
H
H
=
[
H
1
,
⋯
 
,
H
j
,
⋯
 
,
H
m
]
\mathcal{H} = [H_1, \cdots, H_j, \cdots, H_m]
H = [ H 1 , ⋯ , H j , ⋯ , H m ]
[
∣
H
j
∣
≤
k
]
[| H_j | \le k]
[ ∣ H j ∣ ≤ k ]
固定
{
W
,
V
,
{
x
i
}
i
=
1
∣
H
∣
}
{\{ \mathbf{W}, \mathbf{V}, \{{x_i}\}_{i=1}^{|\mathcal{H}|} \}}
{ W , V , { x i } i = 1 ∣ H ∣ }
y
i
y_i
y i
(7)
min
y
i
∈
{
−
1
,
+
1
}
m
,
i
∈
H
∑
j
=
1
m
v
i
(
j
)
ℓ
j
(
x
i
,
W
)
s
.
t
.
∑
j
=
1
m
∣
y
i
(
j
)
+
1
∣
≤
2
\underset{y_i \in \{-1, +1\}^m, i \in \mathcal{H}}{\min} \sum_{j=1}^{m} v_i^{(j)} \ell _j (x_i, \mathbf{W}) \quad s.t. \sum_{j=1}^{m} \left | y_i^{(j)} + 1 \right | \le 2 \tag{7}
y i ∈ { − 1 , + 1 } m , i ∈ H min j = 1 ∑ m v i ( j ) ℓ j ( x i , W ) s . t . j = 1 ∑ m ∣ ∣ ∣ y i ( j ) + 1 ∣ ∣ ∣ ≤ 2 ( 7 )
v
i
̸
=
0
v_i \not = 0
v i ̸ = 0
y
i
y_i
y i
y
i
y_i
y i
m
+
1
m+1
m + 1
这样挑选样本可以有效地抑制逐渐增加的伪标签错误的积累,因为(1)在不同图片内容中交叉图片验证提供更精确和更鲁棒性的评估,(2)所有的伪标签都是一次性的,每次mini-batch迭代之后就会被丢弃。
Low-consistency Sample Annotating :对高一致性样本进行伪标注之后,使用AL过程更新已标注的图片集
I
\mathbf{I}
I
s
i
s_i
s i
U
\mathcal{U}
U
更新
W
\mathbf{W}
W :固定
{
D
,
V
,
Y
}
\{\mathcal{D}, \mathbf{V}, \mathbf{Y}\}
{ D , V , Y }
(8)
min
w
1
∣
H
∪
{
Ω
I
}
I
∈
I
∣
∑
i
∈
H
∪
{
Ω
I
}
I
∈
I
∑
j
=
1
m
ℓ
j
(
x
i
,
W
)
+
L
loc
(
W
)
\underset{w}{\min} \frac{1}{\left | \mathcal{H \cup \{{\varOmega_I}\}_{I \in \mathbf{I}} } \right |} \sum_{i \in \mathcal{H \cup \{{\varOmega_I}\}_{I \in \mathbf{I}} }} \sum_{j=1}^m \ell_j (x_i, \mathbf{W}) + \mathcal{L}_{\text{loc}}(\mathbf{W}) \tag{8}
w min ∣ H ∪ { Ω I } I ∈ I ∣ 1 i ∈ H ∪ { Ω I } I ∈ I ∑ j = 1 ∑ m ℓ j ( x i , W ) + L loc ( W ) ( 8 )
R
(
⋅
)
R(\cdot)
R ( ⋅ )
整个优化过程由下面的伪代码表示:
收敛分析 :这个框架能够保证收敛,有3个原因。(1)公式(2)关于
V
\mathbf{V}
V
首先是SSM和其他方法的比较,这里只简单的说下结果。
下图是在VOC 2007 test set的结果
下表是更加具体的实验结果
下图是通过交叉图片验证过程选择高一致性样本和低一致性样本。