一、RNN的作用:
RNN可解决的问题:
训练样本输入是连续的序列,且序列的长短不一,比如基于时间的序列:一段段连续的语音,一段段连续的手写文字。这些序列比较长,且长度不一,比较难直接的拆分成一个个独立的样本来通过DNN/CNN进行训练。
二、RNN模型:
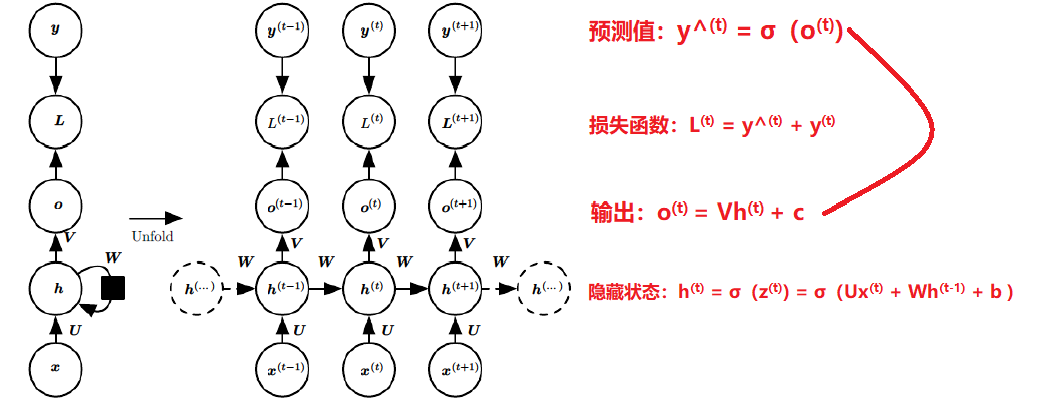
上图中左边是RNN模型没有按时间展开的图,如果按时间序列展开,则是上图中的右边部分。我们重点观察右边部分的图。
这幅图描述了在序列索引号t附近RNN的模型。其中:
1)x(t)代表在序列索引号 t 时训练样本的输入。同样的,x(t−1)和x(t+1)代表在序列索引号t−1和t+1 时训练样本的输入。
2)h(t) 代表在序列索引号 t 时模型的隐藏状态。h(t) 由x(t)和h(t−1) 共同决定。
3)o(t) 代表在序列索引号 t 时模型的输出。o(t) 只由模型当前的隐藏状态h(t)决定。
4)L(t) 代表在序列索引号 t 时模型的损失函数。
5)y(t) 代表在序列索引号 t 时训练样本序列的真实输出。
6)U,W,V 这三个矩阵是我们的模型的线性关系参数,它在整个RNN网络中是共享的,这点和DNN很不相同。 也正因为是共享了,它体现了RNN的模型的“循环反馈”的思想。
U:输入层到隐藏层直接的权重
W:隐藏层到隐藏层的权重
V: 隐藏层到输出层的权重
三、 RNN前向传播算法
- 对于任意一个序列索引号 t ,我们隐藏状态h(t)由x(t) 和h(t−1)得到:
- h(t)=σ(z(t))=σ(Ux(t)+Wh(t−1)+b)
- 其中σ为RNN的激活函数,一般为tanh, b为线性关系的偏倚。
- 序列索引号 t 时模型的输出o(t)的表达式比较简单:
- o(t)=Vh(t)+c
- 在最终在序列索引号 t 时我们的预测输出为:
- y^(t)=σ(o(t))
- 通常由于RNN是识别类的分类模型,所以上面这个激活函数一般是softmax。
- 通过损失函数L(t),比如对数似然损失函数,我们可以量化模型在当前位置的损失,即y^(t)和y(t)的差距。
四、RNN反向传播算法推导
RNN反向传播算法的思路和DNN是一样的,即通过梯度下降法一轮轮的迭代,得到合适的RNN模型参数U,W,V,b,c。
由于我们是基于时间反向传播,所以RNN的反向传播有时也叫做BPTT(back-propagation through time)。
当然这里的BPTT和DNN也有很大的不同点,即这里所有的U,W,V,b,c在序列的各个位置是参数共享的,反向传播时我们更新的是相同的参数。
为了简化描述,这里的损失函数我们为对数损失函数,输出的激活函数为softmax函数,隐藏层的激活函数为tanh函数。
(1)对于RNN,由于我们在序列的每个位置 t 都有损失函数,因此最终的损失L为:
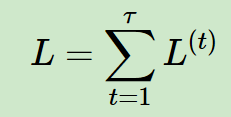
(2)其中 V,c 的梯度计算是比较简单的:
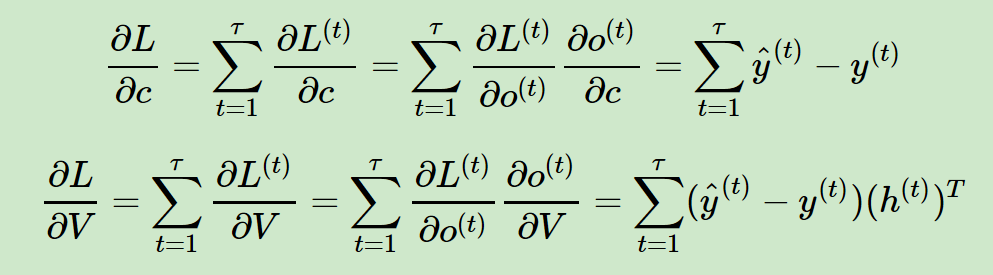
(3)W,U,b的梯度计算比较复杂:
从RNN的模型可以看出,在反向传播时,在某一序列位置t的梯度损失由当前位置的输出对应的梯度损失和序列索引位置t+1时的梯度损失两部分共同决定。对于W在某一序列位置t的梯度损失需要反向传播一步步的计算。我们定义序列索引t位置的隐藏状态的梯度为:


摘自:https://www.cnblogs.com/pinard/p/6509630.html