# 用框架爬取交友信息并保存到数据库
# yuehui.py
# -*- coding: utf-8 -*-
import scrapy
import json
import math
from ..items import YuehuiItem,TrueHeartItem
import re
class YuehuiSpider(scrapy.Spider):
name = 'yuehui'
allowed_domains = ['yuehui.163.com']
start_urls = ['http://yuehui.163.com/searchusersrcm.do?ajax=1&ageBegin=18&ageEnd=89&aim=-1&marriage=0&mode=4&order=8&province=0&city=0&district=-1&sex=0&userTag=0&searchType=0&page=1&pagesize=81']
def parse(self, response):
data = json.loads(response.text)
total = data[0]['total']
max_page = math.ceil(int(total) / 81)
base_url = 'http://yuehui.163.com/searchusersrcm.do?ajax=1&ageBegin=18&ageEnd=89&aim=-1&marriage=0&mode=4&order=8&province=0&city=0&district=-1&sex=0&userTag=0&searchType=0&page=%d&pagesize=81'
for i in range(int(max_page),0, -1):
fullurl = base_url % i
yield scrapy.Request(fullurl,callback=self.parse_list)
def parse_list(self,response):
data = json.loads(response.text)
data = data[0]['list']
for friend in data:
item = YuehuiItem()
uid = friend['id']
age = friend['age']
sex = friend['sex']
is_married = friend['marriage']
edu = friend['degreeName']
loc = friend['cityName'] + friend['districtName']
height = friend['stature']
weight = friend['avoirdupois']
col = friend['constellationName']
job = friend['industryName']
img1 = friend['fullPhotoUri']
img2 = friend['photoUri250']
# img1 = json.loads(img1)
# img2 = json.loads(img2)
item['uid'] = uid
item['age'] = age
item['sex'] = sex
item['is_married'] = is_married
item['edu'] = edu
item['loc'] = loc
item['height'] = height
item['weight'] = weight
item['col'] = col
item['job'] = job
item['images'] = [img1,img2]
# 发起详情页请求
detail_url = 'http://yuehui.163.com/viewuser.do?id=%d'
fullurl = detail_url % uid
yield scrapy.Request(fullurl,callback=self.parse_detail,meta={'data':item})
# 解析详情页
def parse_detail(self,response):
print(response.meta)
item = response.meta['data']
# 获取详情页信息
info_list = response.xpath('//ul[@class="infolist"]/li')
ani = info_list[-2].xpath('./text()').extract()[0].strip('生肖:')
nature = response.xpath('//ul[@class="infolist infolist-visitor personality g-txtwline"]/li/text()').extract()
nature = '-'.join(nature)
item['ani'] = ani
item['nature'] = nature
item['spider_name'] = self.name
yield item
# 创建真心话请求
true_heart_url = 'http://yuehui.163.com/getqalist.do?ajax=1&type=-1&id=%s&page=1&pagesize=100' % item['uid']
yield scrapy.Request(true_heart_url,callback=self.parse_heart)
def parse_heart(self,response):
data = json.loads(response.text)
true_heart_list = data[0]['list']
for true_heart in true_heart_list:
item = TrueHeartItem()
if true_heart['answered']:
qid = true_heart['qid']
question = true_heart['question']
answer = true_heart['answer']
uid_pat = re.compile(r'id=(\d+)')
res = uid_pat.search(response.url)
if res is not None:
uid = res.group(1)
# 构建数据
item['qid'] = qid
item['question'] = question
item['answer'] = answer
item['uid'] = uid
yield item
else:
print('获取用户ID失败')
# items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class Day12Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class YuehuiItem(scrapy.Item):
uid = scrapy.Field()
sex = scrapy.Field()
is_married = scrapy.Field()
age = scrapy.Field()
edu = scrapy.Field()
loc = scrapy.Field()
job = scrapy.Field()
weight = scrapy.Field()
height = scrapy.Field()
col = scrapy.Field()
ani = scrapy.Field()
nature = scrapy.Field()
images = scrapy.Field()
path = scrapy.Field()
spider_name = scrapy.Field()
def get_sql(self):
sql = 'insert into py07_yuehui(path,uid,sex,is_married,age,edu,loc,job,weight,height,col,ani,nature,spider_name) ' \
'values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
data = (self["path"],self["uid"],self["sex"],self["is_married"],self["age"],self["edu"],self["loc"],self["job"],self["weight"],self["height"],self["col"],self["ani"],self["nature"],self["spider_name"])
return sql,data
class TrueHeartItem(scrapy.Item):
qid = scrapy.Field()
question = scrapy.Field()
answer = scrapy.Field()
uid = scrapy.Field()
def get_sql(self):
sql = 'insert into py07_trueheart(question,answer,uid) values(%s,%s,%s)'
data = (self['question'],self['answer'],self['uid'])
return sql,data
# mymiddlewares.py
from scrapy.conf import settings
import random
class ProxyMiddleware(object):
def process_request(self,request,spider):
proxy = settings['PROXIES']
proxy = random.choice(proxy)
proxy = 'http://%s' % proxy['host']
request.meta['proxy'] = proxy
# pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
from .items import YuehuiItem
class Day12Pipeline(object):
def process_item(self, item, spider):
return item
class YuehuiPipeline(object):
def __init__(self):
self.conn = pymysql.connect('127.0.0.1','root','123456','han',charset='utf8')
self.cursor = self.conn.cursor()
def process_item(self,item,spider):
# 插入数据库
sql ,data = item.get_sql()
self.cursor.execute(sql,data)
self.conn.commit()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
from scrapy.pipelines.images import ImagesPipeline
class YuehuiImagePipeline(ImagesPipeline):
# 下载完以后触发
def item_completed(self, results, item, info):
if isinstance(item,YuehuiItem):
images = ''
for it in results:
if it[0]:
path = it[1]['path']
images += path + ','
# 数据库中存储的图片路径
item['path'] = images
# print(dict(item))
return item
# settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for day12 project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'day12'
SPIDER_MODULES = ['day12.spiders']
NEWSPIDER_MODULE = 'day12.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'day12 (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 1
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.5
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'day12.middlewares.Day12SpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
# 'day12.middlewares.MyCustomDownloaderMiddleware': 543,
'day12.mymiddlewares.ProxyMiddleware' : 1
}
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
# 获取项目根目录
import os
BASE_DIR = os.path.dirname(os.path.dirname(__file__))
# 指定图片字段
IMAGES_URLS_FIELD = 'images'
IMAGES_STORE = os.path.join(BASE_DIR ,'images')
ITEM_PIPELINES = {
# 'scrapy.pipelines.images.ImagesPipeline' : 1, # 图片处理管道'
'day12.pipelines.YuehuiImagePipeline' : 1, # 图片处理管道'
'day12.pipelines.YuehuiPipeline': 2,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# AUTH_PROXIES = [
# {'host' : '120.78.166.84:6666', 'auth' : 'alice:123456'}
# ]
PROXIES = [
# {'host' : '124.239.236.127:9999'},
# {'host' : '202.100.167.149:80'},
{'host' : '118.212.137.135:31288'}
]
# main.py
from scrapy import cmdline
cmdline.execute('scrapy crawl yuehui'.split())
# 爬取部分结果如下:
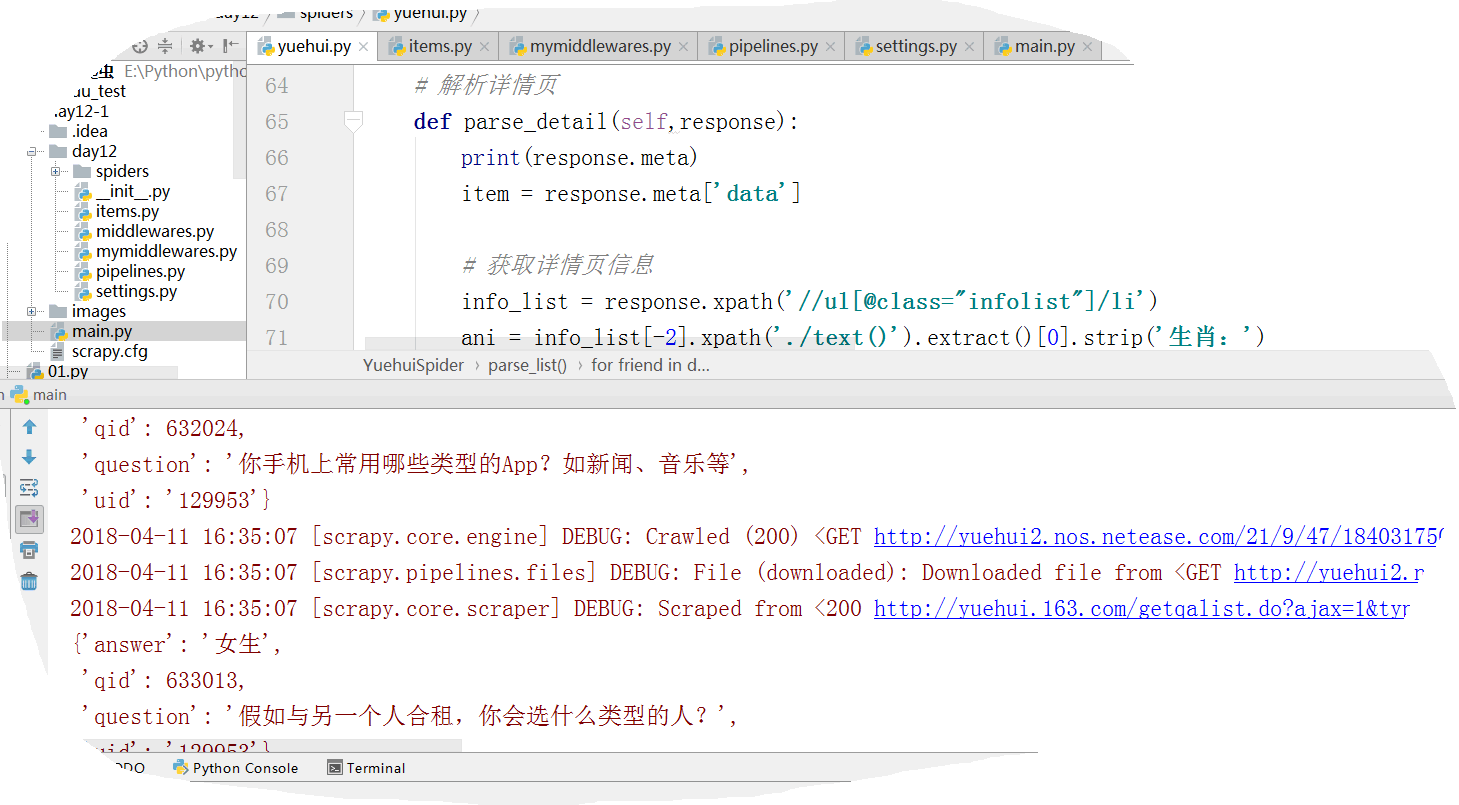
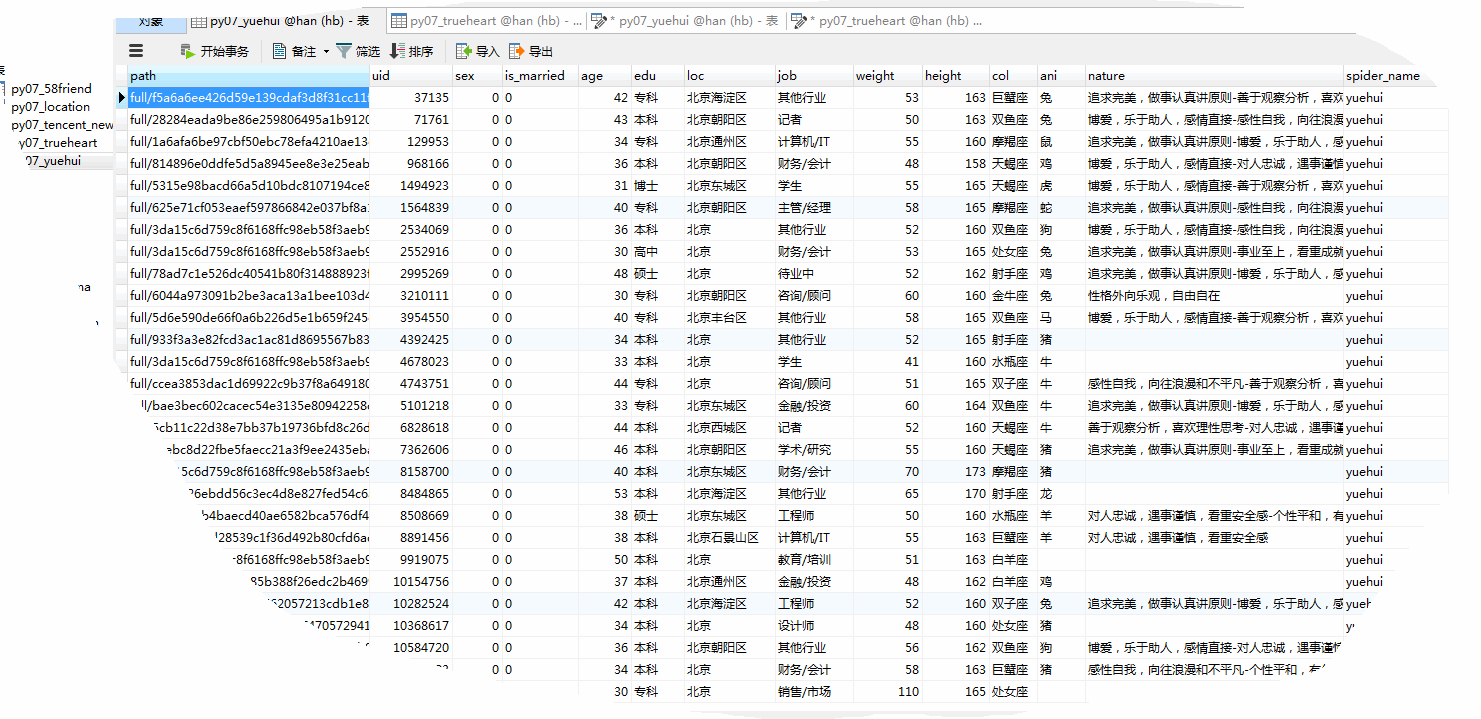
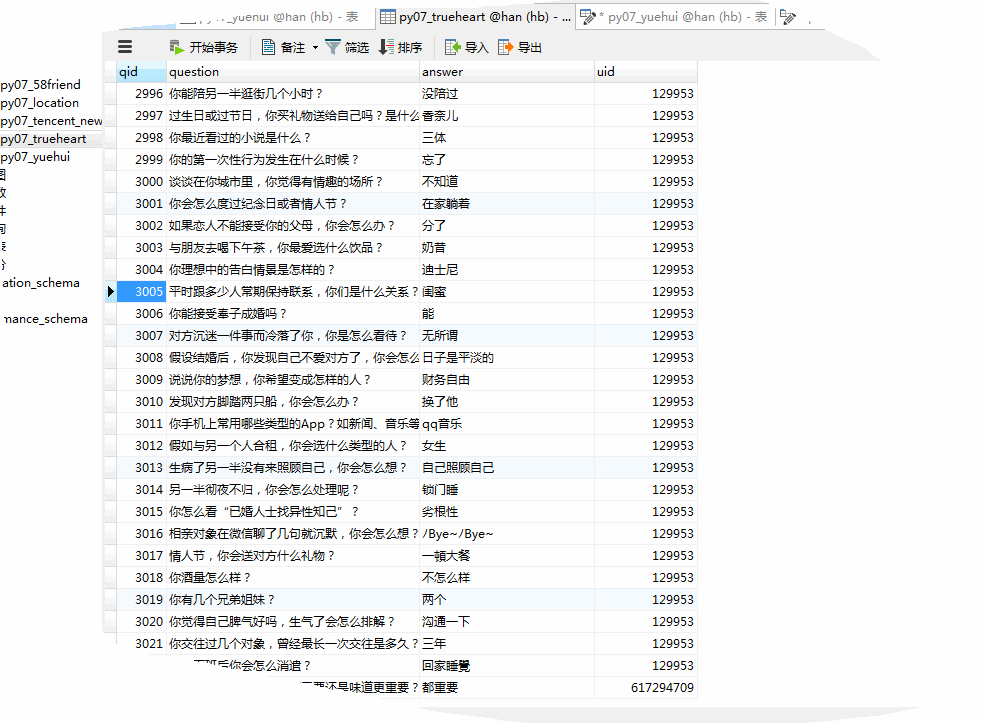
兄弟连学python
Python学习交流、资源共享群:563626388 QQ