版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_38038143/article/details/84640571
题意:
根据儿子、父母关系,输出孙子、爷奶关系:
输入: 输出:
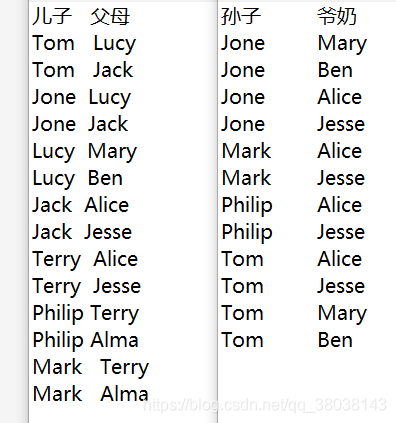
程序的执行浏览如同 wordcount 一样,输入输出几乎没有什么改动,该程序的输入输出结果流程如下图(主要是在第二个箭头中如何按照爷孙关系输出):

重点是如何在reducer端输出时按照爷孙关系输出,这里在job驱动类中定义一个静态变量relationship(相当于全局变量),其定义如下:
public static Map<String, ArrayList<String>> relationship = new HashMap<>();
relationship是一个Map集合,实现key、value的存储:
- 字符串类型的Key存储输入数据的“子”
- 列表类型的Value存储输入数据的“父”
当map端运行结束,将得到两个结果:
- mapper输出到reducer的结果:
<Jack <Jesse, Alice>>
<Jone <Lucy, Jack>>
<Lucy <Mary, Ben>>
<Mark <Alma, Terry>>
<Philip <Terry, Alma>>
<Terry <Alice, Jesse>>
<Tom <Jack, Lucy>>
- 最终relationship存储的数据如下:
key , value
Jone Lucy, Jack]
Jack [Alice, Jesse]
Philip [Terry, Alma]
Lucy [Mary, Ben]
Terry [Alice, Jesse]
Mark [Terry, Alma]
Tom [Lucy, Jack]
因此,在reducer端只需要根据上面1、2点的结果进行遍历,按照关系输出,即可得到最终的结果。
代码:
1. 其中STLinkJob为主函数(驱动类),包含配置信息及静态变量:
public static Map<String, ArrayList<String>> relationship = new HashMap<>();
2. Mapper端代码:
StringTokenizer stringTokenizer = new StringTokenizer(value.toString());
String sun = stringTokenizer.nextToken();
String par = stringTokenizer.nextToken();
// 利用集合将父子关系存储记录
ArrayList<String> arrayList = new ArrayList<>();
if (!STLinkJob.relationship.containsKey(sun)) { // 第一次记录
arrayList.add(par);
STLinkJob.relationship.put(sun, arrayList);
} else { // 第二次记录
arrayList = STLinkJob.relationship.get(sun);
arrayList.add(par);
STLinkJob.relationship.put(sun, arrayList);
}
context.write(new Text(sun), new Text(par));
3. Reducer端代码:
ArrayList<String> grands = new ArrayList<>();
// 通过遍历父母,查询map关系来确定爷奶
for (Text parent : values) { // 父母
String par = parent.toString();
if (STLinkJob.relationship.containsKey(par)) {
grands = STLinkJob.relationship.get(par);
for (String grand : grands) { // 爷奶
context.write(key, new Text(grand));
}
}
}