版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_38038143/article/details/84329286
1. 前言
由于隐私问题,这里不提供日志,可自行准备或随机生成。
下面给出的代码统计的数据文件格式是定的,如果格式与博主不同,请适当修改代码。
2. 分析
- 分析日志统计出IP地址来源,重点无非是IP地址,如下图:
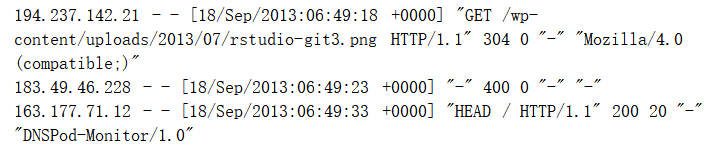
- 通过正则表达式提取合理IP地址:
正则表达式在线测试网站:http://tool.oschina.net/regex/
如下图:

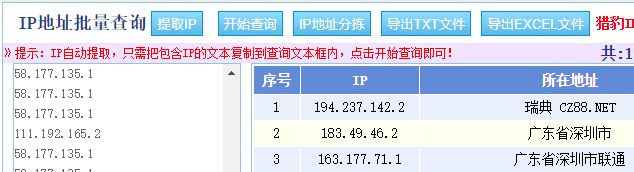
- 将提取出的IP地址查询其地址来源
批量IP地址查询网站:http://ip.soshoulu.com/
如下图:
- 导出TXT文件
将导出的文件上传至Hadoop集群。
3. 代码
代码中共执行了三个 job 任务:
- 根据IP分类、计数
- 根据地址来源分类、计数
- 按照省、市、国家等分类、计数(注:该job的输入为第2个job的输出)
因此,代码设置了 main 函数的参数(可根据自身集群设置):
右键 Run As -> Run Configures

剖析:
hdfs://master:9000/data/logfile/access.log.10 ===> 第一个job的输入
hdfs://master:9000/output/logAnalysisOutput/IPAndCount ===> 第一个job的输出
hdfs://master:9000/data/logfile/IPaddressAll.txt ===> 第二个job的输入
hdfs://master:9000/output/logAnalysisOutput/area ===> 第二个job的输出、第三个job的输入
hdfs://master:9000/output/logAnalysisOutput/detail ===> 第三个job的输出
注:
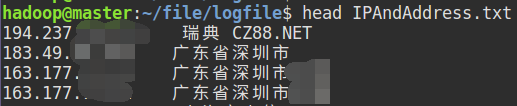
两个输入文件的格式如下:

下图文件内容是先使用正则提取IP,然后使用批量查询IP地址后导出的文件:
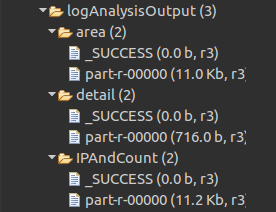
HDFS输出:(注:logAnalysisOutput需要先创建,area、detail、IPAndCount自动生成)
代码见 GitHub:https://github.com/GYT0313/LogAnalysis
实验日志输出结果示例:
- IPAndCount:
1.xxx.203.1 2
1.xxx.186.3 53
1.xxx.222.1 1
1.xxx.70.7 1
1.xxx.126.5 41
- area:
---- 1
上海市xxxxxx公司上海电信节点 7
上海市xxxxxx公司电信节点 28
上海市xxxx公司(中山南路xxx号) 33
乌克兰 5
云南省xxxx电信 1
云南省xxxx 1
- detail
上海市 3336
乌克兰 5
云南省 35
俄罗斯 8
其他国家和地区 17
内蒙古 19
加拿大 57