之前的文章已经简单介绍过mapreduce的运作流程,不过其内部的shuffle过程并未深入讲解;本篇博客将分享shuffle的全过程。
一、mapreduce运作流程长卷图(其中[深]朱红色代表是可以用户自定义的部分,当然它们有默认实现)
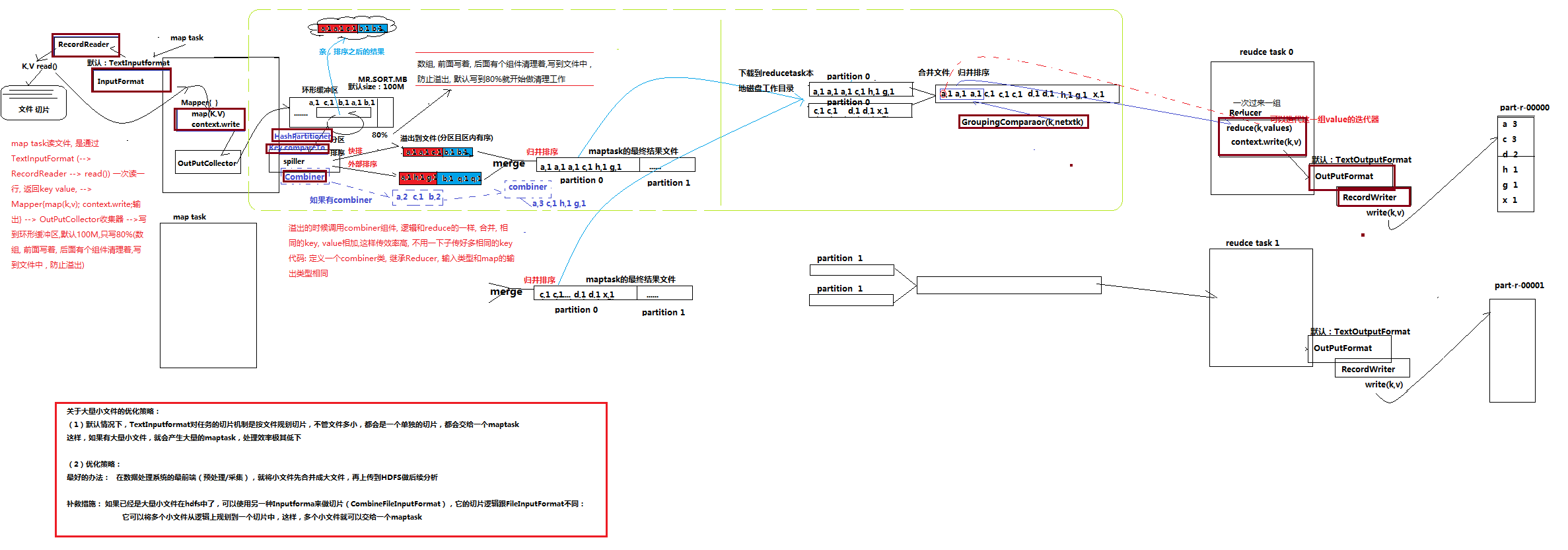
二、shuffle过程中的combiner自定义实现
首先combiner组件有什么作用呢?它可以减少我们在shuffle归并排序是的次数、reduce阶段处理的数据次数,同时可以有效提供程序的执行效率。
以下是wordcount使用combiner实现的代码
(1) maper实现:
package com.empire.hadoop.mr.wccombinerdemo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* WordcountMapper.java的实现描述: KEYIN: 默认情况下,是mr框架所读到的一行文本的起始偏移量,Long,
* 但是在hadoop中有自己的更精简的序列化接口,所以不直接用Long,而用LongWritable
* VALUEIN:默认情况下,是mr框架所读到的一行文本的内容,String,同上,用Text
* KEYOUT:是用户自定义逻辑处理完成之后输出数据中的key,在此处是单词,String,同上,用Text
* VALUEOUT:是用户自定义逻辑处理完成之后输出数据中的value,在此处是单词次数,Integer,同上,用IntWritable 类
*
* @author arron 2018年12月4日 下午9:30:09
*/
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* map阶段的业务逻辑就写在自定义的map()方法中 maptask会对每一行输入数据调用一次我们自定义的map()方法
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将maptask传给我们的文本内容先转换成String
String line = value.toString();
//根据空格将这一行切分成单词
String[] words = line.split(" ");
//将单词输出为<单词,1>
for (String word : words) {
//将单词作为key,将次数1作为value,以便于后续的数据分发,可以根据单词分发,以便于相同单词会到相同的reduce task
context.write(new Text(word), new IntWritable(1));
}
}
}
(2) reducer实现实现:
package com.empire.hadoop.mr.wccombinerdemo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* 类 WordcountReducer.java的实现描述:KEYIN, VALUEIN 对应 mapper输出的KEYOUT,VALUEOUT类型对应
* KEYOUT, VALUEOUT 是自定义reduce逻辑处理结果的输出数据类型 KEYOUT是单词 VLAUEOUT是总次数
*
* @author arron 2018年12月4日 下午9:51:15
*/
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* <angelababy,1><angelababy,1><angelababy,1><angelababy,1><angelababy,1>
* <hello,1><hello,1><hello,1><hello,1><hello,1><hello,1>
* <banana,1><banana,1><banana,1><banana,1><banana,1><banana,1>
* 入参key,是一组相同单词kv对的key
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0;
/*
* Iterator<IntWritable> iterator = values.iterator();
* while(iterator.hasNext()){ count += iterator.next().get(); }
*/
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
(3) combiner实现实现:
package com.empire.hadoop.mr.wccombinerdemo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* 类 WordcountCombiner.java的实现描述:输如为map的输出
*
* @author arron 2018年12月4日 下午9:29:25
*/
public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0;
for (IntWritable v : values) {
count += v.get();
}
context.write(key, new IntWritable(count));
}
}
(4) mapreduce主程序驱动类实现:
package com.empire.hadoop.mr.wccombinerdemo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 类 WordcountDriver.java的实现描述:相当于一个yarn集群的客户端 需要在此封装我们的mr程序的相关运行参数,指定jar包
* 最后提交给yarn
*
* @author arron 2018年12月4日 下午9:29:48
*/
public class WordcountDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//是否运行为本地模式,就是看这个参数值是否为local,默认就是local
/* conf.set("mapreduce.framework.name", "local"); */
//本地模式运行mr程序时,输入输出的数据可以在本地,也可以在hdfs上
//到底在哪里,就看以下两行配置你用哪行,默认就是file:///
/* conf.set("fs.defaultFS", "hdfs://mini1:9000/"); */
/* conf.set("fs.defaultFS", "file:///"); */
//运行集群模式,就是把程序提交到yarn中去运行
//要想运行为集群模式,以下3个参数要指定为集群上的值
/*
* conf.set("mapreduce.framework.name", "yarn");
* conf.set("yarn.resourcemanager.hostname", "mini1");
* conf.set("fs.defaultFS", "hdfs://mini1:9000/");
*/
Job job = Job.getInstance(conf);
job.setJar("c:/wc.jar");
//指定本程序的jar包所在的本地路径
/* job.setJarByClass(WordcountDriver.class); */
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定需要使用combiner,以及用哪个类作为combiner的逻辑
/* job.setCombinerClass(WordcountCombiner.class); */
job.setCombinerClass(WordcountReducer.class);
//如果不设置InputFormat,它默认用的是TextInputformat.class
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
CombineTextInputFormat.setMinInputSplitSize(job, 2097152);
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
/* job.submit(); */
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
三、最后总结
虽然combiner组件在shuffle阶段使用的话,可以提高程序效率;但是,它有一个使用限制条件,那就是不能影响最后的执行结果;例如:这里讲述一个反例,对多个输入的数进行求平均数,如果此时使用combiner将不能得到正确的结果。
最后寄语,以上是博主本次文章的全部内容,如果大家觉得博主的文章还不错,请点赞;如果您对博主其它服务器大数据技术或者博主本人感兴趣,请关注博主博客,并且欢迎随时跟博主沟通交流。