Hadoop的sequenceFile为二进制键/值对提供了一个持久数据结构。它可以作为小文件的容器。HDFS和MapReduce是针对大文件优化的,所以通过SequenceFile类型将小文件包装起来,可以获得更高效率的存储和处理。
SequenceFile的实现代码:
package com.jr.sequencefile;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.Writer;
import org.apache.hadoop.io.Text;
import org.junit.Test;
public class TestSequenceFile {
/**
* 写入
* @throws IOException
*/
@Test
public void write() throws IOException {
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path name=new Path("/user/centos/hadoop/meseq2.seq");
IntWritable iw=new IntWritable();
Text txt=new Text();
Writer w=SequenceFile.createWriter(fs, conf, name, IntWritable.class, Text.class);
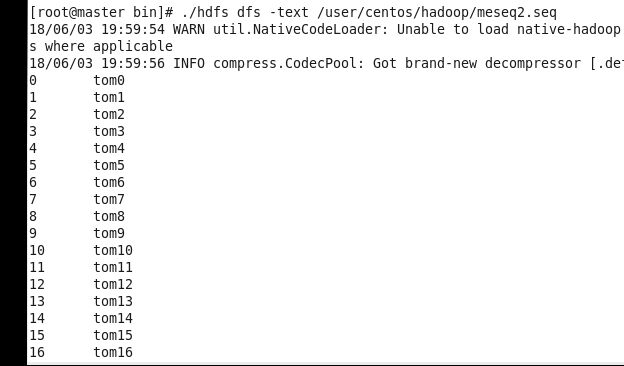
for(int i=0;i<1000;i++) {
w.append(new IntWritable(i), new Text("tom"+i));
}
w.close();
}
/**
* 读数据
*/
@Test
public void read() throws IOException {
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path name=new Path("/user/centos/hadoop/meseq2.seq");
IntWritable key=new IntWritable();
Text txt=new Text();
SequenceFile.Reader reader=new SequenceFile.Reader(fs, name,conf);
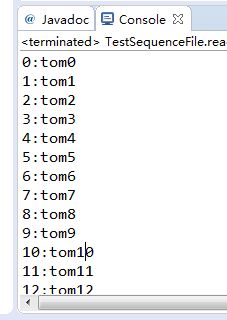
while(reader.next(key)) {
reader.getCurrentValue(txt);
System.out.println(key.get()+":"+txt.toString());
}
}
/**
* 写入无序的数据
* @throws IOException
*/
@Test
public void writeNoOrder() throws IOException {
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path name=new Path("/user/centos/hadoop/meseqNoOrder.seq");
IntWritable iw=new IntWritable();
Text txt=new Text();
Writer w=SequenceFile.createWriter(fs, conf, name, IntWritable.class, Text.class);
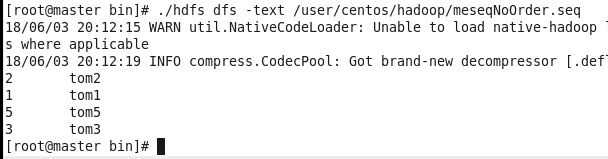
w.append(new IntWritable(2), new Text("tom2"));
w.append(new IntWritable(1), new Text("tom1"));
w.append(new IntWritable(5), new Text("tom5"));
w.append(new IntWritable(3), new Text("tom3"));
w.close();
}
/**
* 对sequence进行排序
* @throws IOException
*/
@Test
public void sortSeqFile() throws IOException {
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path src=new Path("/user/centos/hadoop/meseqNoOrder.seq");
Path dest=new Path("/user/centos/hadoop/meseqOrder.seq");
IntWritable iw=new IntWritable();
Text txt=new Text();
//创建排序对象
SequenceFile.Sorter sorter=new SequenceFile.Sorter(fs, IntWritable.class, Text.class, conf);
sorter.sort(src,dest);
}
/**
* 合并文件
* @throws IOException
*/
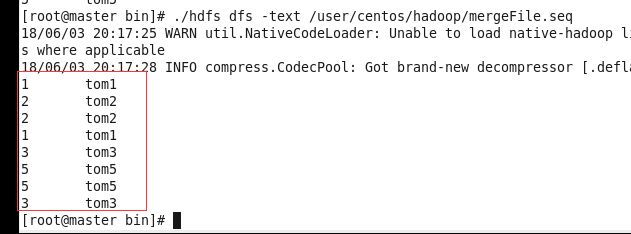
@Test
public void mergeFile() throws IOException {
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
Path src=new Path("/user/centos/hadoop/meseqNoOrder.seq");
Path dest=new Path("/user/centos/hadoop/meseqOrder.seq");
Path merge=new Path("/user/centos/hadoop/mergeFile.seq");
IntWritable iw=new IntWritable();
Text txt=new Text();
//创建排序对象
SequenceFile.Sorter sorter=new SequenceFile.Sorter(fs, IntWritable.class, Text.class, conf);
sorter.merge(new Path[] {src,dest}, merge);
}
}
查看各个方法执行结果:
1.public void write():
2.public void read()读数据:
3.public void writeNoOrder()写入无序的数据
4.public void sortSeqFile() 对 sequence进行排序
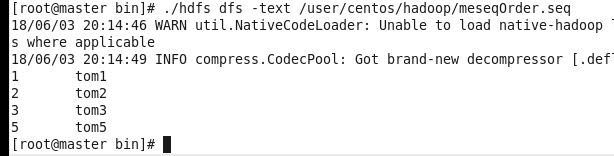
5.public void mergeFile()合并(合并文件没有排序处理)