一 查询过程:普通索引是找到叶子节点,然后再叶子节点中二分法找到那条记录,然后向后找,找不到就停止,然后回表。
唯一索引是找到一条就不找了,因为是唯一的。性能差别不到。
数据库查找记录,首先是把这条记录的所在的页全部加载到内存中,16k,
二 更新过程:更新过程普通索引会用change buffer ,把修改语句放到内存中,然后等到合适的时候触发merge,除了访问这个数据页会触发外,会定期,也会数据库shutdown的时候
change buffer 会存在内存中,也会存到磁盘。
唯一索引以为要判断唯一性,首先会加重数据页中的数据,所以会在内存中,也就没有必要change buffer ,而普通索引就会用到change buffer ,
如果数据在内存中,这俩个没什么区别,如果不在内存中,区别就大了。
适用场景,写多读少。不然就会有反作用。
普通索引和唯一索引对于查询没有多大的区别,区别在于插入更新。
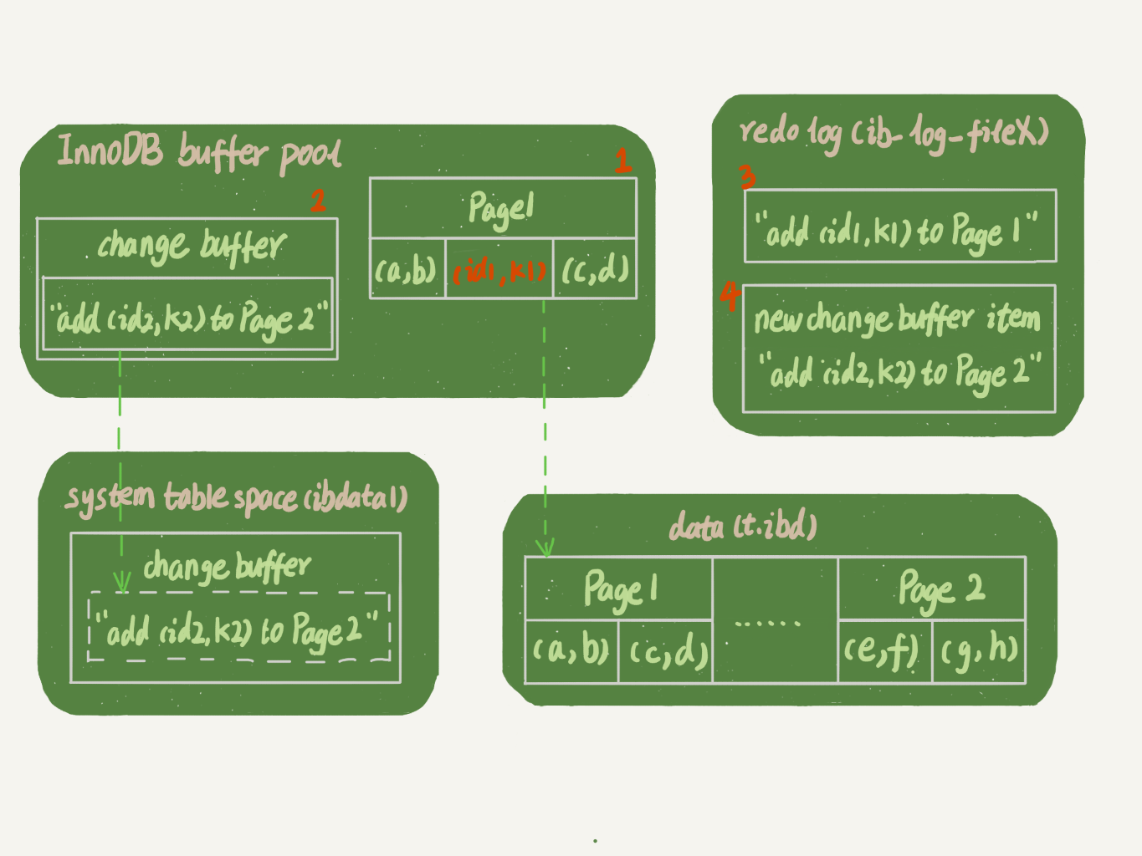
上图是page1在内存中,直接写入,page2不在内存中,然后change buffer ,然后记录日志
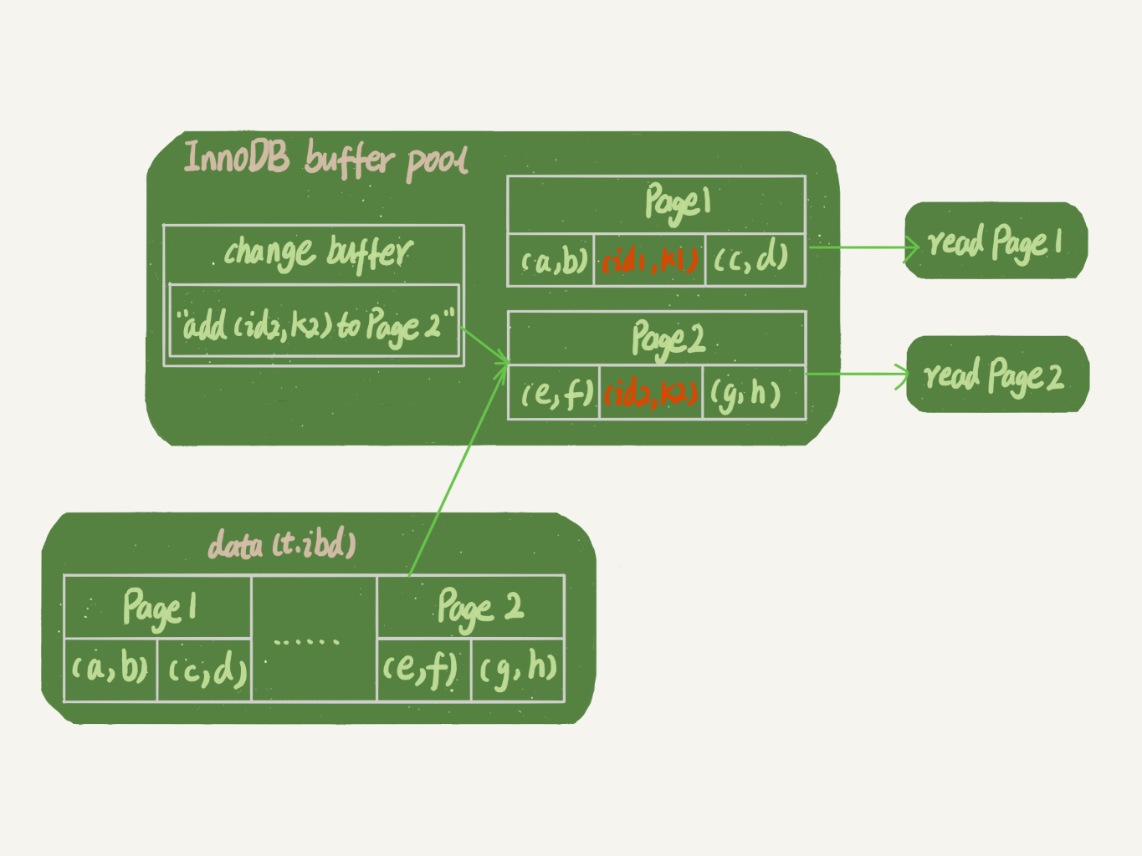
更新不久后,当读page 1,page 2,因为他们还在内存,page2进行merge,直接返回结果,存入磁盘