本文是我在大半年前在前公司做团队分享时的一个文档,写得比较挫,当时分享讲了2个小时,自己感觉讲得还可以。最近前同事跑来问我还有没有文档保存,翻了旧电脑和硬盘才找出来,于是就想着分享一下。
一、MySQL整体结构
-
服务器层(负责客户端连接、授权认证、安全、线程管理等)
-
核心层(缓存查询、解析器、查询优化器、函数)(存储过程,触发器,视图)
-
存储引擎层(MyISAM、InnoDB、Memory、Merge,负责数据的存储和提取)

数据库的全球排名情况
https://db-engines.com/en/ranking
本次讲的大多是INNODB
mysql太多内容可讲,每个点都一次分享都讲不完。
没有理解内核实现时的无法知道mysql怎么工作,只知道存储。
带大家从外而内看透MySQL。
这个整体结构类似于springMvc中的controller service dao
- Connectors:不同语言中与 SQL 的交互
- Management Serveices & Utilities:系统管理和控制工具
- Connection Pool:连接池
- SQL Interface:SQL 接口(提供给存储引擎层,类似于面向接口编程,SPI等)
- Parser:解析器
- Optimizer:查询优化器
- Cache 和 Buffer:查询缓存
- Engine:存储引擎
MyISAM和INNODB的区别
1、Innodb最大的特点: 支持事务处理与外键和行级锁
2、索引实现方式不同,MyISAM的索引和数据是分开的,并且索引是有压缩的,内存使用率就对应提高了不少InnoDB 中不保存表的具体行数,也就是说,执行select count() from table
3、对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引
4、DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。
5、InnoDB 中不保存表的具体行数,也就是说,执行select count() from table
关于MyISAM和InnoDB的其他相关
1、读多写少的,MyISAM的读性能是比Innodb强不少
2、MySQL 4.0以上 myisam引擎就支持了full text search 全文搜索
3、mysql版本号已经大于5.6.4了也就支持了innodb的全文搜索
一条查询语句的执行过程

二、MySQL的数据结构和原理
Questions
-
MySQL通过什么数据结构实现?
-
为什么要用这种数据结构实现?
扫描二维码关注公众号,回复: 4389123 查看本文章
-
我们如何最大化这种特性?如何利用这种特性来优化我们的数据库设计和查询?
- 常用的数据结构
线性结构:数组、链表、哈希表
树形结构:二叉树(平衡二叉树、二叉查找树、完全二叉树)、2-3树、红黑树、B树
图形结构:有向图、无向图
二叉树
-
若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
-
若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
-
任意节点的左、右子树也分别为二叉查找树。
-
没有键值相等的节点(no duplicate nodes)。

二分查找\二叉树查找,时间复杂度o(lgn)
2-3树
-
对于3节点,该节点保存两个key及对应value,以及三个指向左中右的节点
-
在最坏的情况下,也就是所有的节点都是2-node节点,查找效率为lgN
-
在最好的情况下,所有的节点都是3-node节点,查找效率为log3N约等于0.631lgN
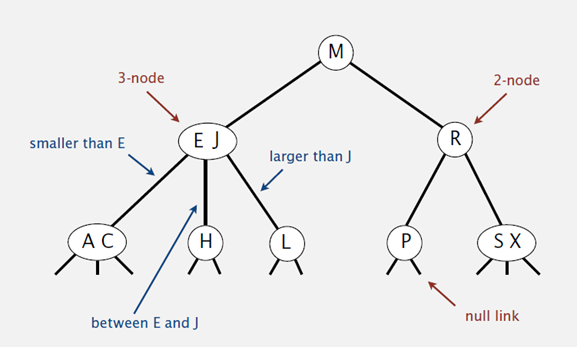
在最坏的情况下,也就是所有的节点都是2-node节点,查找效率为lgN
在最好的情况下,所有的节点都是3-node节点,查找效率为log3N约等于0.631lgN
红黑树
-
红色节点向左倾斜
-
一个节点不可能有两个红色链接
-
整个书完全黑色平衡,即从根节点到所以叶子结点的路径上,黑色链接的个数都相同。
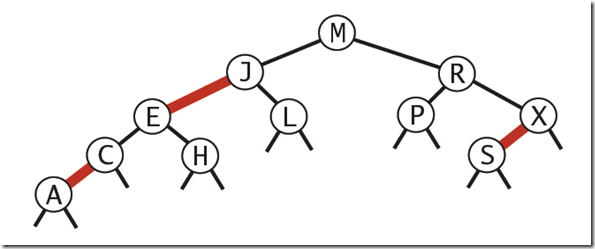
红黑树是2-3树的一种简单高效的实现
B树
- 每一个节点都包含数据,元素离根节点余越近访问越快

B+树
-
内部节点上不包含数据信息
-
叶子结点都是相连的
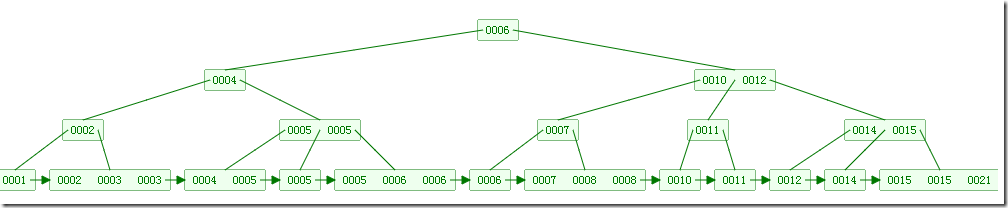
对于一颗节点为N度为M的子树,查找和插入需要logM-1N ~ logM/2N次比较。这个很好证明,对于度为M的B树,每一个节点的子节点个数为M/2 到 M-1之间,所以树的高度在logM-1N至logM/2N之间。
这种效率是很高的,对于N=62*1000000000个节点,如果度为1024,则logM/2N <=4,即在620亿个元素中,如果这棵树的度为1024,则只需要小于4次即可定位到该节点,然后再采用二分查找即可找到要找的值。
B树和B+树的排序图区别
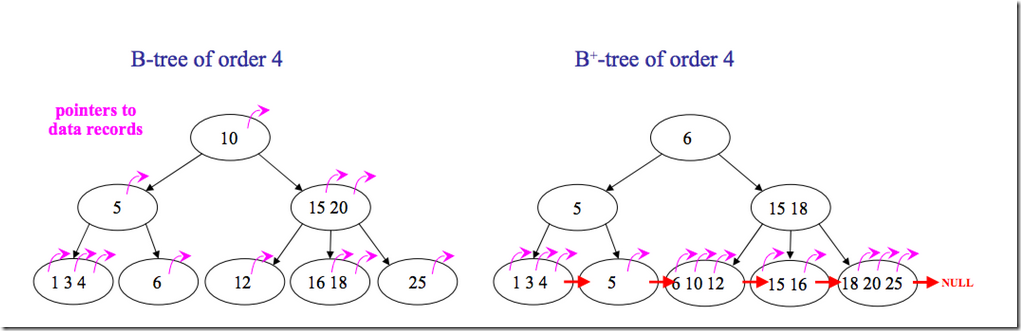
- 有哪些可能被用来实现MySQL的数据结构
有了上面的数据结构知识,可以知道MySQL会利用什么数据结构实现了吗?
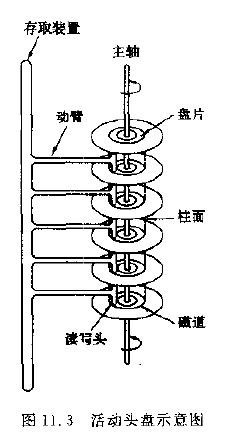
磁盘上数据必须用一个三维地址唯一标示:柱面号、盘面号、块号(磁道上的盘块)。
磁盘读取数据是以盘块(block)为基本单位的,一个block为4k
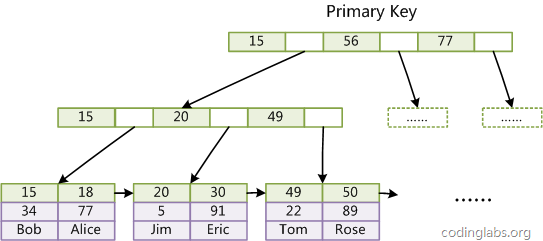
- InnoDB索引实现
主键索引
非主键索引
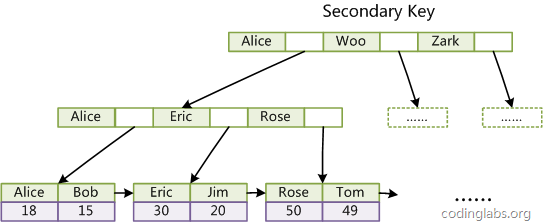
基于B+树的数据结构给出的建议:
- 表的主键尽量用自增ID,不用随机生成的
- 某些查询可以使用覆盖索引的,则可以减少一次回表查询
三、MySQL隔离级别和MVCC实现原理
- Read Uncommitted(读未提交)
- Read Committed(读已提交)
- Repeatable Read(可重复读)
- Serializable(串行化)

四、MySQL的锁机制
常用的锁的方式
- select … lock in share mode
- select … for update
乐观锁的使用例子:
update trade_id_log set max_trade_id=#maxTradeId# where owner_id=#ownerId# and max_trade_id = #originMaxTradeId#
看下面的SQL是否加锁,如何加锁:SQL1:select * from t1 where id = 10;
SQL2:delete from t1 where id = 10;
先抛两个名词:记录锁、间隙锁 看下面几种情况是怎么加锁的1.id列是主键,RC隔离级别
(X锁是排他锁)

2.id列是二级非唯一索引,RC隔离级别

3.id列是二级非唯一索引,RR隔离级别

4.id无索引,RR隔离级别

5.Serializable隔离级别
Serializable隔离级别,影响的是SQL1:select * from t1 where id = 10;6.思考一下这几种情况
(1)id列是二级唯一索引,RC隔离级别;
(2)id列上没有索引,RC隔离级别;
(3)id列是主键,RR隔离级别;
(4)id列是二级唯一索引,RR隔离级别;
7.分析一条复杂的SQL的加锁方式(RR隔离级别)

–>
五、MySQL使用技巧
1.sql查询优化,了解explain
(1)分页问题:用户需要查看第50000页的100条数据
解决方案一:
先通过覆盖索引查对应的分页数据的主键ID,再通过主键ID去查数据
解决方案二:
业务优化,不让用户选择;或者只能上/下一页翻动
explain select SQL_NO_CACHE * from product limit 5000000,100
\# 扫描的行:6512596
explain select SQL_NO_CACHE * from product where id > 7391753 limit 0,100
\# 扫描的行:3256298,记录上一页最后一条数据id,用于下一次的搜索
(2)Group by优化
GROUP BY 默认会使用分组字段排序(可能会文件排序),取消排序使用order by null
如:explain select status,count(status) from trade30 group by status ;
改写成 explain select status,count(status) from trade30 group by status order by null ;
2.ip存储
select inet_aton("192.168.52.100");
select inet_ntoa(3232248932);
3.mysql程序 mysql函数(使用案例:自定义大量数据入库(模拟陈胤的product数据))
自定义函数:生成随机字符串
DELIMITER &&
CREATE FUNCTION `randstring`(n INT) RETURNS varchar(255)
BEGIN
DECLARE chars_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE return_str varchar(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str = concat(return_str,substring(chars_str , FLOOR(1 + RAND()*62 ),1));
SET i = i +1;
END WHILE;
RETURN return_str;
END
&&
4.自定义hash索引(crc32函数 crc64函数)使用案例:精确查找某个固定的字符串
CREATE TABLE `crc` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`article` varchar(512) DEFAULT NULL,
`value` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `IDX_V` (`value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
set @aa = "adsfhaklshfjdsafhasdkfyuqwo4623703241213846231891421354961238472318947123elrbmanvcuixgqwbelfjasdkcgsavdlfbasdkchadgsliubfja.sdkvhgvsi";
insert into crc VALUES(null,@aa,CRC32(@aa));
select * from crc where value = crc32(@aa);
5.避免数据库插入重复记录
(1)insert ignore into person (id,name,phone) VALUES (20,‘111’,‘12’);
(2)REPLACE into person (id,name,phone) VALUES (20,‘20’,‘20’);
(3)insert into person (id,name,phone) VALUES (32,‘3232’,‘3232’) ON DUPLICATE KEY UPDATE name=‘323232’;
6.乐观锁的使用
update trade_id_log set max_trade_id=#maxTradeId# where owner_id=#ownerId# and max_trade_id = #originMaxTradeId#
7.视图的使用
删除视图
drop view if exists user_view;
创建视图
create view user_view as select uid,uname,mobile from user_account;
查询视图
select * from user_view;
作者推荐博客