1.MAPREDUCE原理篇
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;
2. MAPREDUCE框架结构及核心运行机制
1.结构:
一个完整的mapreduce程序在分布式运行时有三类实例进程:
1、MRAppMaster:负责整个程序的过程调度及状态协调
2、mapTask:负责map阶段的整个数据处理流程
3、ReduceTask:负责reduce阶段的整个数据处理流程
3.mapreduce快速体验(单词技术案例)
首先需要配置本地的hadoop环境:


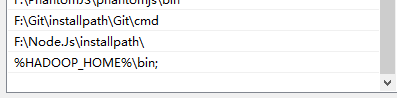
1.第一种运行方式,新建java项目本地运行,不在集群上跑,新建java项目,导入jar包
解压


代码编写,创建一个驱动类:
package com.wx.mapreduce1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
//相当于一个yarn集群的客户端,在这里我们封装好mr的运行参数,指定jar包
//最后交给yarn
Configuration conf=new Configuration();
//是否运行在本地
conf.set("mapreduce.framework.name", "local");
//本地运行mapreduce时输入的数据可以在本地也可以在hadoop上,看你怎么配置
// conf.set("fs.defaultFS", "hdfs://hadoop1:9000/");
//conf.set("fs.defaultFS", "file:///"); //默认就是从本地拿
//要想运行为集群模式,就要把程序提交到yarn中去运行,一下三个参数就要指定为集群上的值
// conf.set("mapreduce.framework.name", "yarn");
// conf.set("yarn.resourcemanager.hostname", "hadoop1");
// conf.set("fs.defaultFS", "hdfs://hadoop1:9000/");
Job job =Job.getInstance(conf);
//指定本程序jar包所在的本地路径
job.setJarByClass(WordCountDriver.class); //hadoop -jar这个才能找到正确位置,这是打包上去用hadoop-jar运行
//job.setJar("/home/hadoop/wordcount.jar");//java -jar就要写死了让他去找jar包,这是打包上去用java -jar运行
job.setJar("F:\\hadoopwordcount.jar"); //这是eclipse里面运行集群模式,指定jar包
//指定本业务要使用的mapper/reduces业务
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
//指定mapper输出数据kv的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定最终输出数据kv的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定job输入源文件的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将job中设置的相关参数,和job所用java类所在的jar包提交给yarn,让yarn去运行
//job.submit();
//Job运行是通过job.waitForCompletion(true),true表示将运行进度等信息及时输出给用户,
//false的话只是等待作业结束
//Job对象有两种状态:DEFINE和RUNNING,是通过JobState枚举类定义的
boolean re = job.waitForCompletion(true);
System.exit(re?0:1);
}
}
编写map程序:
package com.wx.mapreduce1;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* 默认情况下KEYIN是mr读到一行文本的起始偏移量,类型为Long,但是在hadoop中有自己更精简的序列化接口
* 所以不直接用Long,而是用LongWritable
* VALUEIN默认情况下为mr读到的一行文本的内容,类型为String,用Text
* KEYOUT为用户 自定义处理后输出数据的key,此处是单词类型为String,同样使用Text
* VALUEOUT为用户自定义处理输出后的value,此处是单词的次数,类型为Integer,使用IntWritable
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
//maptask会对我们输入的每一行数据都调用一次map方法处理
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
//将输入的文本先转换为空格
String line = value.toString();
//按空格分割
String[] words = line.split(" ");
//将单词输出 结果为 <单词,1>
for(String word:words)
{
//将单词作为key,value作为1
context.write(new Text(word), new IntWritable(1));
}
}
}
编写reduce程序:
package com.wx.mapreduce1;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/*
* Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN和VALUEIN为其他的mapper的输出数据 如:<hello,1><hello,1><hello,1><hello,1>
* KEYOUT和VALUEOUT一个是单词,一个单词的总次数
*/
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int count=0;
//把单词的次数相加
for(IntWritable value:values)
{
count+=value.get();
}
//输出
context.write(key,new IntWritable(count));
}
}
打包本地运行:打包成功后将jar包发哦到程序setjar指定的位置
配置启动参数:
准备数据:

右击主类运行:


本地运行没有问题
2. 第二种运行方式,提交到集群运行,首先需要启动hadoop集群,hadoop集群基于这篇博客搭建的hadoop集群

创建测试目录及文件(命令最好手敲,复制的可能不能正常执行):
hadoop fs -mkdir -p /wordcount/input hadoop fs -put words.txt /wordcount/input

接下来修改驱动类:
package com.wx.mapreduce1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
//相当于一个yarn集群的客户端,在这里我们封装好mr的运行参数,指定jar包
//最后交给yarn
Configuration conf=new Configuration();
//是否运行在本地
//conf.set("mapreduce.framework.name", "local");
//本地运行mapreduce时输入的数据可以在本地也可以在hadoop上,看你怎么配置
//conf.set("fs.defaultFS", "hdfs://hadoop1:9000/");
//conf.set("fs.defaultFS", "file:///"); //默认就是从本地拿
//要想本地运行为集群模式,就要把程序提交到yarn中去运行,一下三个参数就要指定为集群上的值
/* conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.hostname", "hadoop1");
conf.set("fs.defaultFS", "hdfs://hadoop1:9000/");*/
//windows向linux集群提交,需要添加跨平台参数,打包到linux,则不需要添加
//conf.set("mapreduce.app-submission.cross-platform","true");
Job job =Job.getInstance(conf);
//指定本程序jar包所在的本地路径
job.setJarByClass(WordCountDriver.class); //hadoop -jar这个才能找到正确位置,这是打包上去用hadoop-jar运行
//job.setJar("/home/hadoop/wordcount.jar");//java -jar就要写死了让他去找jar包,这是打包上去用java -jar运行
//job.setJar("F:\\hadoopwordcount.jar"); //这是eclipse里面运行集群模式,指定jar包
//指定本业务要使用的mapper/reduces业务
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
//指定mapper输出数据kv的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定最终输出数据kv的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定job输入源文件的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将job中设置的相关参数,和job所用java类所在的jar包提交给yarn,让yarn去运行
//job.submit();
//Job运行是通过job.waitForCompletion(true),true表示将运行进度等信息及时输出给用户,
//false的话只是等待作业结束
//Job对象有两种状态:DEFINE和RUNNING,是通过JobState枚举类定义的
boolean re = job.waitForCompletion(true);
System.exit(re?0:1);
}
}
打包上传到任意一台机器都行:
运行报错:Unsupported major.minor version 52.0,
直译过来意思是:不支持version52.0,其中version 52.0是魔码的其中一个版本,他对应的是jdk1.8
所以异议过来就是:不支持jdk1.8
修改idea jdk的版本:

重新打包上传运行:
报错:输入目录已经存在,然后我删除了hdpdata,重新格式化hdfs,但是出现datanode无法启动的情况,
原因是clusterID不一致
删除tmp下的内容
从/home/hdp/hadoop/name/current/VERSION 获得clusterID
修改到
/home/hdp/hadoop/data/current/VERSION
修改保持一致,然后重启服务
运行仍然不成功,因为无法剔除多余的jar包,所以这种方式运行改用下面的maven项目完成。
3.第三种运行模式,本地平台向集群提交任务:修改驱动文件:

package com.wx.mapreduce1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
//相当于一个yarn集群的客户端,在这里我们封装好mr的运行参数,指定jar包
//最后交给yarn
Configuration conf=new Configuration();
//是否运行在本地
//conf.set("mapreduce.framework.name", "local");
//本地运行mapreduce时输入的数据可以在本地也可以在hadoop上,看你怎么配置
conf.set("fs.defaultFS", "hdfs://hadoop1:9000/");
//conf.set("fs.defaultFS", "file:///"); //默认就是从本地拿
//要想本地运行为集群模式,就要把程序提交到yarn中去运行,一下三个参数就要指定为集群上的值
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resourcemanager.hostname", "hadoop1");
conf.set("fs.defaultFS", "hdfs://hadoop1:9000/");
//windows向linux集群提交,需要添加跨平台参数,打包到linux,则不需要添加
conf.set("mapreduce.app-submission.cross-platform","true");
Job job =Job.getInstance(conf);
//指定本程序jar包所在的本地路径
job.setJarByClass(WordCountDriver.class); //hadoop -jar这个才能找到正确位置,这是打包上去用hadoop-jar运行
//job.setJar("/home/hadoop/wordcount.jar");//java -jar就要写死了让他去找jar包,这是打包上去用java -jar运行
job.setJar("F:\\hadoopwordcount.jar"); //这是eclipse里面运行集群模式,指定jar包
//指定本业务要使用的mapper/reduces业务
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
//指定mapper输出数据kv的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定最终输出数据kv的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定job输入源文件的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将job中设置的相关参数,和job所用java类所在的jar包提交给yarn,让yarn去运行
//job.submit();
//Job运行是通过job.waitForCompletion(true),true表示将运行进度等信息及时输出给用户,
//false的话只是等待作业结束
//Job对象有两种状态:DEFINE和RUNNING,是通过JobState枚举类定义的
boolean re = job.waitForCompletion(true);
System.exit(re?0:1);
}
}
报错:Exception message: /bin/bash: line 0: fg: no job control,这是因为运行平台不一致的原因,两种解决方式
要么在配置文件mapreduce-site.xml中添加:
<property>
<name>mapred.remote.os</name>
<value>Linux</value>
<description>Remote MapReduce framework's OS, can be either Linux or Windows</description>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>要么在代码中添加(当然选择这种方式):
//windows向linux集群提交,需要添加跨平台参数,打包到linux,则不需要添加
conf.set("mapreduce.app-submission.cross-platform","true");右击运行:

查看结果:

以上是新建java项目来运行mapreduce程序,下面主要是新建maven项目来运行mapreduce 程序,主要是为了让打包方便
首先还是本地想集群提交任务
java类和上面一样,配置也一样,唯一不同的是添加jar包改成添加依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.wx</groupId>
<artifactId>learnhadoop</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!--添加hadoop common依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.4</version>
</dependency>
<!--添加hadoop hdfs依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.4</version>
</dependency>
<!--添加hadoop client依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
<!--添加hadoop-core的依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-yarn-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>2.6.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.6.4</version>
</dependency>
</dependencies>
</project>运行:没有问题

接下来打包到集群上去运行:maven打包方便不用去剔除External Libraries下的包:
驱动类还是和上面一样:
运行命令:
hadoop jar learnhadoop-1.0-SNAPSHOT.jar com.wx.mapreduce1.WordCountDriver /wordcount/input /wordcount/output结果: