目录
类的例子
在这个程序中创建一个名为Cats的类。它有三个私人成员:姓名、品种、年龄。创建所有的集合和获取函数 以及 printInfo函数: setName,setBreed,setAge,getName,getBreed,getAge,printInfo。
我们先在创建头文件 main.hpp 作为我的类文件。代码如下:
#include<iostream>
using namespace std;
class Cat
{
string name;
string breed;
int age;
public:
void setName(string nameIn);
void setBreed(string breedIn);
void setAge(int ageIn);
string getName();
string getBreed();
int getAge();
void printInfo();
};
void Cat::setName(string nameIn)
{
name = nameIn;
}
void Cat::setBreed(string breedIn)
{
breed = breedIn;
}
void Cat::setAge(int ageIn)
{
age = ageIn;
}
string Cat::getName()
{
return name;
}
string Cat::getBreed()
{
return breed;
}
int Cat::getAge()
{
return age;
}
void Cat::printInfo()
{
cout<<name<<" "<<breed<<" "<<age;
}okay,现在我们可以使用这个类了,以下代码:
#include"main.hpp"
int main()
{
Cat cat1,cat2;
cat1.setName("Kimmy");
cat2.setName("Bobby");
cat1.setBreed("calico");
cat2.setBreed("main coon");
cat1.setAge(4);
cat2.setAge(1);
cat1.printInfo();
cout<<"\n";
cat2.printInfo();
cout<<"\n\n";
//Alternate printing method
cout<<cat1.getName()<<" "<<cat1.getBreed()<<" "<<cat1.getAge()<<"\n";
cout<<cat2.getName()<<" "<<cat2.getBreed()<<" "<<cat2.getAge();
return 0;
}运行结果:

构造函数(Constructors)
我们需要谈论一个特殊的函数成员,构造函数。构造函数(Destructors)是在我们创建类的新实例时执行的特殊函数。 它用于设置类的数据成员的初始值。
这时候你会问:为什么一定要用它来初始化变量呢??
在 C++ 程序中,变量在定义时可以初始化。如果不进行初始化,变量的初始值会是什么呢?对全局变量和局部变量来说,这个答案是不一样的。
1.未初始化的全部变量
全局变量在程序装入内存时就已经分配好了存储空间,程序运行期间其地址不变。对于程序员没有初始化的全局变量,程序启动时自动将其全部初始化为 0(即变量的每个比特都是 0)。
在大多数情况下,这是一种稳妥的做法。而且,将全局变量自动初始化为 0,是程序启动时的一次性工作,不会花费多少时间,所以大多数 C++ 编译器生成的程序,未初始化的全局变量的初始值都是全 0。2.未初始化的局部变量
对于局部变量,如果不进行初始化,那么它的初始值是随机的。局部变量定义在函数内部,其存储空间是动态分配在栈中的。函数被调用时,栈会分配一部分空间存放该函数中的局部变量(包括参数),这片新分配的存储空间中原来的内容是什么,局部变量的初始内容也就是什么,因此局部变量的初始值是不可预测的。函数调用结束后,局部变量占用的存储空间就被回收,以便分配给下一次函数调用中涉及的局部变量。
为什么不将局部变量自动初始化为全 0 呢? 因为一个函数的局部变量在内存中的地址,在每次函数被调用时,都可能不同,因此自动初始化的工作就不是一次性的,而是每次函数被调用时都要做,这会带来无谓的时间开销。当然,如果程序员在定义局部变量时将其初始化了,那么这个初始化的工作也是每次函数被调用时都要做的,但这是编程者要求做的,因而不会是无谓的。
初学者常因 “构造函数” 这个名称而认为构造函数负责为对象分配内存空间,其实并非如此。构造函数执行时,对象的内存空间已经分配好了,构造函数的作用是初始化这片空间。
为类编写构造函数是好的习惯,能够保证对象生成时总是有合理的值。例如,一个“雇员”对象的年龄不会是负的。
详细请点击这里。
例如,在我们的上面的例子的 Cats类 中,我们可能希望获得 猫的年龄 和 品种 的初始值。 如果我们设置初始值,我们不需要程序或用户设置每个值。
构造函数不返回值,包括void。
构造函数的声明是:
ClassName::ClassName();构造函数的定义是:
ClassName::ClassName()
{
dataMemberName1 = value;
dataMemberName2 = value;
...
}我们来看一个例子:
#include<iostream>
using namespace std;
//The cats class that we used earlier in the lesson.
class Cats
{
string name;
string breed;
int age;
public:
Cats(); //声明构造函数
void setName(string nameIn);
void setBreed(string breedIn);
void setAge(int ageIn);
string getName();
string getBreed();
int getAge();
void printInfo();
};
//defining the constructor
Cats::Cats()
{
cout<<"Assigning inital values in the constructor\n";
name = "Unknown";
breed = "Unknown"; //the initial value of the breed
age = 99; //the initial value of the age
}
void Cats::setName(string nameIn)
{
name = nameIn;
}
void Cats::setBreed(string breedIn)
{
breed = breedIn;
}
void Cats::setAge(int ageIn)
{
age = ageIn;
}
string Cats::getName()
{
return name;
}
string Cats::getBreed()
{
return breed;
}
int Cats::getAge()
{
return age;
}
void Cats::printInfo()
{
cout<<name<<" "<<breed<<" "<<age;
}
//+++++++
int main()
{
Cats cat1;
cout<<"Cat1 information: ";
cat1.printInfo();
return 0;
}运行结果:
![]()
析构函数(Destructors)
除了构造函数之外,C ++还有析构函数(Destructors)。
为什么叫做析构函数?作用?
答:构函数(Destructor) 与 构造函数相反,当对象脱离其作用域时(例如对象所在的函数已调用完毕),系统自动执行析构函数。析构函数往往用来做“清理善后” 的工作(例如在建立对象时用new开辟了一片内存空间,应在退出前在析构函数中用delete释放)。
析构函数是特殊的类函数,只要对象超出范围就会调用它们。 就像构造函数一样,自动调用析构函数。
- 析构函数不能:
- return a value - accept parameters - 析构函数必须与类名相同;
- 析构函数用 tilda(〜)符号标识;
- 无参数,无返回值;
- 一个类最多只有一个析构函数;
声明析构函数:
~className() //this is a destructor定义析构函数:
classname::~classname()
{
//tasks to be completed before going out of scope
}析构函数的一个更重要的任务是释放 由类构造函数 和 成员函数 分配的内存。我们将在内存分配文章中详细讨论这个问题。
让我们举个例子 来更深理解 析构函数:
#include<iostream>
class Test
{
int id;
public:
Test(int i)
{
id = i;
}
~Test()
{
std::cout<<"ID: "<<id<<" destruction function is invoked!"<< std::endl;
};
};
int main()
{
Test t0(0);//栈中分配
Test t1[3]{1,1,1};//栈中分配,数组型对象
Test *t2 = new Test(2);//堆中分配
delete t2;
Test *t3 = new Test[3]{3,3,3};//堆中分配
delete []t3;
std::cout<<"------End of Main-------"<< std::endl;
return 0;
}运行结果:
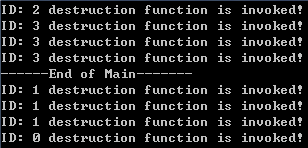
注意:destruction function is invoked! 意思是:调用销毁函数!还有代码写得不是很正规,因为这是为了教学的代码,请原谅!~
main函数 代码解析:
1。Test t0(0); 表示:调用类并新建一个名为t0的变量名,并输入id为0的值。这是栈中分配内存的。
2。Test t1[3]{1,1,1}; 表示:跟上面代码一样意思,只是输入的数据是数组。这也是栈里面分配内存的。
3。Test *t2 = new Test(2); 表示:这里是指针变量,所以它是在堆中分配内存的。
4。delete t2; 表示:释放 t2 这块的内存,所以我用删除这个值来做到这点。
结果分析:
1。代码1、2中都是在栈中分配内存的,在栈中内存由系统自动的去分配和释放,而使用 new 创建的指针对象是在堆中分配内存,当不需要该对象时,需要我们手动的去释放,否则会造成内存泄漏。
2。在上述程序中,t0 和 t1 都是栈中的对象,在程序结束时由系统来释放,因此出现在“----End of Main”之后。t2,t3是 new 出来的堆中对象,所以需要手动的delete释放,因此,结果显示ID:2和3的先被删除或者说释放内存,所以在结果显示在最前面。
3。在输出的结果中,"------End of Main-------"后面显示的信息,是在栈中自动释放的,为什么能够显示呢?这就是因为我们用了析构函数(~Test())。
4。另外有一点发现,就是栈中对象的释放顺序,是后定义的先释放,经过几次验证也如此,我想这恰好应征了栈的后进先出的特征。(栈,是一种数据结构,你可以想象它为一个电梯,最后面那个人进入电梯的,一定是先出的)
举例(正规的写法):
#include<iostream>
using namespace std;
class Dog
{
private:
int license;
public:
Dog();
Dog(int licenseIn);
void setLicense(int licenseIn);
int getLicense();
~Dog();
};
Dog::Dog()
{
license = 0;
}
Dog::~Dog()
{
cout<<"\nDeleting the dog";
}
Dog::Dog(int licenseIn)
{
license = licenseIn;
}
void Dog::setLicense(int licenseIn)
{
license = licenseIn;
}
int Dog::getLicense()
{
return license;
}上是头文件main.hpp。
#include "main.hpp"
int main()
{
Dog d2(666666);
cout<<d2.getLicense();
return 0;
}运行结果:
![]()
程序员之所以犯错误,不是因为他们不懂,而是因为他们自以为什么都懂。