版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/NockinOnHeavensDoor/article/details/84837977
kl散度意义:
-
In the context of machine learning,
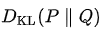
is often called the information gain achieved if Q is used instead of P. -
This reflects the asymmetry in Bayesian inference, which starts from a prior Q and updates to the posterior P.
-
公式:

证明:https://stats.stackexchange.com/questions/7440/kl-divergence-between-two-univariate-gaussians