转自:《编码的奥秘》 第二十章
数字计算机存储器按位存储,所以,需要在计算机上处理的信息必须按位的形式存储。我们已经知道如何用位来表示数和机器码,下一个问题是如何用它来表示文本。毕境世界上大量堆积的信息是文本形式的,就像装满图书馆的书、杂志和报纸。尽管我们最终要用计算机来存放声音、图像和电影信息,但我们还是以较容易的文本存放开始。
为了以数字形式表示文本,必须开发一些系统使得系统里的每一个字母有唯一的编码。文本中也存在数字和标点符号,所以也必须有它们的编码。简单地说,所有的字母、数字和符号都要编码,这样的系统叫作字符编码集,每一个编码叫作字符编码。
第一个问题是:这些编码需要多少位?这并不是容易回答的问题。
当考虑用位表示文本的时候,需要切合实际。我们习惯于看到书中、报刊、杂志上精美的文本格式,段落按照相同的间隔整齐地分成一行一行,但这些并不是文本的本质。当我们在杂志上看到一个小故事,几年后在一本书中又看到同样故事的时候,我们不会因为书中文本间距的不同而认为是不同的故事。
换句话说,不要以这种印刷成行列的二维格式来看待文本,应该把文本看成是一维的字母、数字和标点符号流,此外,也许还有额外的编码用来表示一段的结束和另一段的开始。
再来看看,如果在杂志上看到一个故事,后来又在书中看到同样的故事但字样有些不同,这是一个大问题吗?如果杂志上的写法为
![]()
而书中的写法为
![]()
这些差别难道是我们真正关心的吗?恐怕不是。印刷样式是微妙地影响了文本的观感,但故事本身并没有因为样式的改变而不同。样式可以经常修改,但不会带来什么影响。
接下来另外一个简化问题的方法是:用平版的文本。没有斜体,没有粗体,没有下划线,没有颜色,没有空心体,没有上下标,没有音调标记,没有 Å、 é 、 、 等符号,只有9 9 %英语文本里纯粹的拉丁字母。
在对摩尔斯电码和布莱叶盲文的早期研究中,可以看到如何将字母字符表示成二进制的形式。尽管这些系统在特定的场合应用地很好,但用到计算机里都有一些问题。例如:摩尔斯电码是宽度可变的编码:对常用的字符采用短编码,对不常用的字符采用长编码。这样的编码系统适用于电报,但对计算机来说却不合适。另外,摩尔斯电码对字母的大小写没有区分。
布莱叶盲文是宽度固定的编码,很适合计算机。每一个字符由 6位表示,也可以区分大小写,尽管它是用特殊的 e s c a p e码来区分的,该代码表明下一个字符为大写。这也就是说,每个首部字符需要两个代码而不是一个。数字用 s h i f t码表示,在这个特定的代码后紧跟的代码被看作表示数字,直到又一个 s h i f t码将其转换到字符状态。
我们的目标是开发一个字符编码集,使得像如下的句子![]()
可以用一串代码来表示,每一个代码具有一定的位数。一些代码用来表示字母,一些表示标点符号,一些表示数字。甚至有代码来表示字间的空格。上面的句子中有 1 8个字符(包括字间空格) ,这样一个句子的连续字符代码常称作文本串。
在文本串里,用代码来表示数字 (如2 7 )似乎很奇怪,因为前面许多章里已讲过用位来表示数字。我们可能会用简单的二进制数 1 0和111作为该句中 2和7的代码,但用在这里是不合适的。该句中,字符 2和7可像英文作品中出现的任何一种字符一样来看待 ,它们可能具有与它们的实际值毫不相干的字符代码。
也许最经济的字符编码是 5位编码,它首先用于 1 8 7 4年的电报机,是由法国电报服务公司职员 Emile Baudot 发明的。他的编码 1 8 7 7年被服务公司采纳,后来由 Donald Murray修改并在1 9 3 1 年被 C C I T T,即现在的国际电联 (ITU) 标准化。该编码的正式名称是国际电报字母表N O . 2或I TA - 2,在美国通常称为 B a u d o t,尽管更科学的叫法为 M u r r a y编码。
在2 0世纪, B a u d o t经常用于电传打字机。 B a u d o t电传打字机有一个键盘,除了只有 3 0个键和一个间隔棒外,有些像打字机。电传打字机的键实际上是转换器,它产生二进制代码并且通过电传打字机的输出电缆一位紧接一位地传送出去。电传打字机也有打印机制,从电传打字机的输入电缆输入的代码触发电磁铁在纸上打印出字符 。
由于B a u d o t是5位编码,所以总共只有 3 2个代码,这些代码的十六进制值范围从 0 0 h~1 F h。下表是 3 2个 代码所对应的字母表中的字符 :
代码 0 0 h没有指定。其余的 3 1 个代码中, 2 6个指定给字母表中的字符, 5个用斜体字或短语表示出来了。
代码0 4 h是空格代码,用来分隔不同的字;代码 0 2 h和0 8 h表示回车和换行。这些术语来自于电传打字机。当在电传打字机上打字并且到了一行的末尾时,按下一个杠杆或按钮来完成两件事情。第一,使打印头回到开始处,以便从纸的左边开始打印下一行,这是回车。第二,移动打印头紧接至刚完成的那一行的下一行,这是换行。在 B a u d o t中,独立的键产生这两个代码。打印的时候, B a u d o t电传打字机响应这两个代码,完成相应动作。
在B a u d o t系统里,如何表示数字和标点符号呢?这就是代码 1 B h的作用,在表中标识为数字转义。在数字转义代码之后,所有的代码序列被看作是数字或标点符号,直到遇到字符转义代码 ( 1 F h )再返回到字符状态。下表是数字和标点符号的代码。
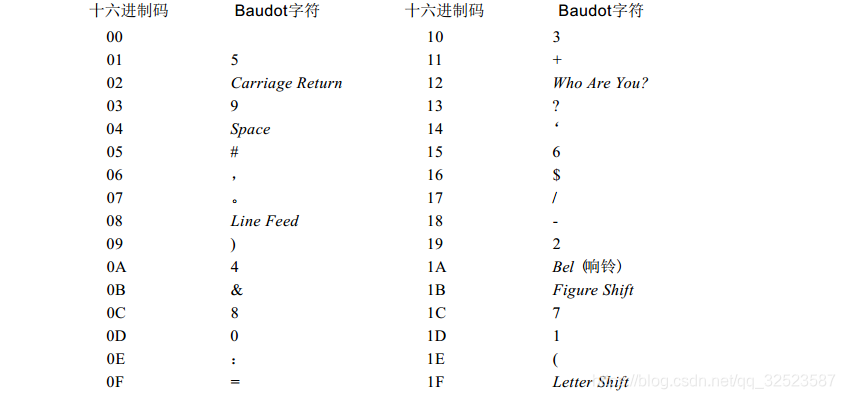
实际上, I T U没有定义代码 0 5 h、 0 B h和 1 6 h,而是保留为“国家使用”,这个表里列出的是美国的用法。这些代码在某些欧洲国家语言中用作重音符号。响铃代码用来敲响电传打字机上能听见的铃声;“ Who Are Yo u”代码激活一种机制,用它电传打字机能识别自己。
像摩尔斯电码一样,这 5位编码不能区别大、小写。语句![]()
由下面的十六进制数据流来表示:![]()
注意三个转义代码 : 1 B h在数字的前面, 1 F h在数字的后面,最后一部分之前又有 1 B h。该行代码用回车、换行代码来结束。
然而,如果一行两次传送该数据流到电传打印机,将会出现以下情形:
![]()
这是怎么回事?打印机接收到的上一行的最后一个转义代码是数字代码,所以第二行开始的代码被解释成数字。、
类似这样的问题是采用转义代码所产生的典型的令人烦恼的结果。尽管 B a u d o t是很经济的编码,但人们可能更想采用能唯一表示字符或标点符号且对大、小写进行区分的代码。
如果想确定比 B a u d o t更好的编码系统需要多少位,只需把各种符号加起来:大小写字母需5 2个代码, 0~9数字需 1 0个代码,这已经有 6 2个,加上一些标点符号,则超过了 6 4个代码,这意味着需要多于 6位的编码。但是距离 1 2 8个字符数,似乎还有足够的余地。如果超过 1 2 8个字符,则需要 8位编码。
所以答案应该是7。如果不用转换代码来区分大、小写,那么英文里应该用 7位来表示字符。
这些字符编码都是什么呢?当然,我们可以随心所欲地编码。如果打算自己制造计算机且计算机的每一个硬件都由自己制造,自己编程且不把自己所造的计算机去与任何其他计算机连接,则可以构造自己的编码,所要做的就是给每一个字符一个唯一的编码。
但是因为很少有独立制造和使用计算机这种情形发生,所以通常是大家遵循并使用同一编码。这样制造出来的计算机就可以与其他计算机兼容,并且可以交换文本信息。
我们可能也不应该随意编码,例如,当在计算机上处理文本时,如果字母表上的字符是按顺序进行编码的,则会带来很多好处,其码这样的顺序使得按字母排序和分类更容易一些。
幸运的是,我们已经有了这样一个标准,即美国信息交换标准代码,简写为 A S C I I码。它1 9 6 7年正式公布,此后一直是计算机工业界最为重要的标准。除了一个大的例外(在后面讲到),可以肯定的是,无论什么时候处理文本,总会以某种方式涉及到 A S C I I码。
A S C I I码是 7位编码,用二进制代码 0 0 0 0 0 0 0~111111 1 ,即十六进制代码 0 0 h~ 7 F h来表示。让我们来看 A S C I I码,但不要从最开始看,因为前 3 2个代码比其余代码理解起来要困难一些。从第二批的 3 2个代码开始讲起,它包括标点符号和 1 0个数字。下表列出了它们的十六进制代码及对应的字符:

注意2 0 h是空格符,用来分隔单词和句子。
接下来的 3 2个代码包括大写字母和一些附加的标点符号。除 @符号和下划线之外,这些符号在打字机上不经常出现,它们出现在标准的计算机键盘上:

接下来的3 2个字符包括所有小写字母和一些附加的标点符号,也是在打字机上不常出现的:
注意该表中少了与 7 F h对应的最后一个字符。如果你一直在统计,这三个表总共列出了 9 5个字符。因为 A S C I I码是7位编码,可以有 1 2 8个代码,所以还有 3 3个代码可用。下面简单地讲一下这些代码。

可以表示成 A S C I I码的十六进制形式![]()
注意除了字母代码以外,还有逗号(代码 2 C)、空格(代码 2 0)和感叹号(代码 2 1 )。下面是另一短句:![]()
用 A S C I I码表示为:![]()
注意句中数字 1 2表示成十六进制数 3 1 h和 3 2 h,分别是数字 1 和 2的A S C I I码。当数字 1 2作为文本流的一部分时,它不应该被表示成十六进制码 0 1 h和0 2 h,或者B C D码1 2 h,或者十六进制代码0 C h。这些代码在 A S C I I码里都表示的是其他意思。
ASCII码表示的大写字母与其对应的小写字母的ASCII码值相差20h,这使得编写某些程序代码更为容易,如:把一个字符串变成大写。假设在内存的某个区域存放有字符串,一个字节放一个字符。下面的8080子程序假设字符串的首地址存放在寄存器HL中;寄存器C存放有字符串的长度,即字符串中的字符个数:


从小写字母减去 2 0 h转换成大写字母的语句可以用下面的语句代替:![]()
A N I指令是一个“与”立即数的操作,它把累加器中的数值与 D F h(即二进制数 11 0 11111)执行按位“与”操作,即把两个数的对应位进行“与”操作“与”操作保留 A中的所有位,除了从左边数第3位被置成0。把这个位设置为0也即把A S C I I码表示的小写字母转换成大写字母。
上面列出的 9 5个代码也称作图形字符 ,因为它们可以显示出来。 A S C I I码还包括 3 3个控制字符,它们不能显示出来但表示执行某一特定功能。鉴于完整性,这里列出了 3 3个控制字符,即使它们很难理解也不要担心。在 A S C I I码公布以后,更多地是想把它们用在电传打字机上,现在许多代码已经很少见到了。

控制字符可以与图形字符混合使用来设置一些基本的文本格式。这很容易理解,想像一下诸如电传打字机或简单打印机之类的设备,它们对 A S C I I码流作出的响应是在纸上打印出字符。设备的打印头通过打印一个字符并向右移动一格来对 A S C I I码作出响应。上面这些很重要的控制字符就用来改变这种通常的动作。
例如:看以下的十六进制字符串![]()
0 9字符是一个水平制表符,简称 Ta b。假设打印页面上所有的水平字符位置是从 0开始, Ta b的作用是在下一个水平位置即 8的倍数处开始打印下一个字符,如下所示:![]()
这是保持字符按列对齐的简便方法。
换页符( 1 2 h)的作用是使打印机跳过当前页开始打印下一页。
退格符用来在一些旧的打印机上打印复合字符,例如,假设计算机要控制电传打字机以重音标记来打印小写字母 e,即è,可以通过用十六进制码 65 08 60来实现。
最重要的控制字符是回车和换行,它们与 B a u d o t码中的回车换行符意义相同。在打印机中,回车符使打印头移到打印页面的左边,换行符使打印头移到下一行,用两个代码通常表示从新的一行开始。单独使用回车符可以用来在一个已有的行上打印,单独使用换行符可以用来跳到当前位置的下一行而不移到左边。
尽管 A S C I I 码是计算机世界的主要标准,但在许多 I B M大型机系统上却没有采用。在S y s t e m / 3 6 0系统中, I B M研制了自己的 8位字符编码,即扩展的 B C D交换代码 E B C D I C。该编码是早期的 BCDIC 6 位编码的扩展,从 I B M穿孔卡片使用的代码演变而来。穿孔卡片可以存放8 0个文本字符,这种模式由 IBM 1928年首先引入并且用了 5 0多年。
当考察穿孔卡片与相关的 8位E B C D I C字符编码的关系时,需要记住的是,在若干种不同技术的支持下这种代码已经经历了好几代的演变。正因为如此,不要指望从中发现太多的逻辑性和一致性。
穿孔卡片中,字符编码由一列上穿出的一个或多个矩形孔的组合而形成,字符本身通常在接近卡片的上边沿处打印出来。下面的 1 0行由数字标识,分别是第 0行、第 1 行直到第 9行。在第0行之上没有数字的行为第 11 行,最上边的行为第 1 2行,没有第 1 0行。
以下是一些常用的 I B M穿孔卡片术语:行 0~ 9称作数字行或数字穿孔,行 11 和 1 2称作区域行或区域穿孔。有一些 I B M穿孔卡片也会带来混淆,把行 0和9看作是区域行而不是数字行。
一个8位E B C D I C字符编码由高半字节( 4位)与低半字节组成。低半字节是与字符的数字穿孔一致的 B C D码,高半字节是与区域穿孔一致的编码。回忆一下第 1 9章的 B C D编码标准,它是用二进制编码十进制数,即用 4位编码来代表十进制的 0~9。
对数字 0~ 9,没有区域穿孔,没有区域穿孔对应的高半字节是 1111 ,低半字节是数字穿孔的 B C D码。下面是 0~9的E B C D I C编码:

对大写字母,如果只有第 1 2行有穿孔,则用 11 0 0来标识;如果只有第 11 行有穿孔,则用11 0 1 来标识;如果只有第 0行有穿孔,则用 111 0来标识。大写字母的 E B C D I C编码为:
注意这些编码的编号次序。在一些场合,当用 E B C D I C文本编写程序的时候,这些次序有时还真令人头痛。
小写字母与大写字母的数字穿孔相同但区域穿孔不同。小写 a~i的第1 2行和第 0行有穿孔,相应的区域代码为 1 0 0 0; j~r的第1 2行和第 11 行有穿孔,区域代码为 1 0 0 1; s~z的第11 行和第0行有穿孔,区域代码为 1 0 1 0。小写字母的 E B C D I C编码为:

当然,标点符号和控制字符也有 E B C D I C编码,但对该编码系统的全面考察并不需要。
似乎I B M穿孔卡片上的每一列就足以提供 1 2位的编码信息,每个孔代表 1 位,是这样吗?果真如此的话,可以用穿孔卡片上每一列 1 2个位置中的 7个来表示 A S C I I码的字符代码。但是,实际上,这并不合适,太多的穿孔将会影响到卡片物理状态的平直。
E B C D I C中的许多 8位码没有定义,建议采用 A S C I I码的 7位编码是合理的。当 A S C I I码研制出来的时候,存储器非常昂贵,于是一些人感到 A S C I I码应该用 6位码并且采用转义字符来区分大小写用以节约存储器。这种观点没有被接受,相反,人们认为 A S C I I码应该是 8位编码,因为即使在当时人们也普遍认为计算机应该是按 8位存储,而不是 7位。当然, 8位字节现在是标准的。因此,尽管 A S C I I码在技术上是 7位编码,但它普遍是接 8位值来存储的。
字节与字符之间的等价关系的确很方便,我们只需简单地通过统计字符数就可以粗略估计一个文本文件所需要的存储空间。当然,用 K和 M来表示计算机存储空间用得更为广泛一些。
例如,传统的 8 . 5× 11英寸的双倍空隙打印页面有 1 英寸的页边空白和大约 2 7行的正文。每行约 6 . 5英寸宽,每英寸有 1 0个字符,这样一页共有 1 7 5 0个字节。单倍空隙打印页面大约是它的2倍,约 3 . 5 K B。
《NEW Yo r k e r》杂志每页有 3列,每列有 6 0行,每行大约有 4 0个字符,这样每页有 7 2 0 0个字符(或字节)。 《纽约时代》每页有 6列。如果页面都是文字而没有标题和图片(这是不常有的) ,则每列有 1 5 5行,每行大约有 3 5个字符,从而整个页面有 32 550个字符,即 3 2 K B。
当然,每本书的差别很大:
F. Scott Fitzgerald的 《The Great Gatsby》 大约300KB。
J. D. Salinger的 《Catcher in the Rye 》 大约400KB。
Mark Twain的《The Adventures of Huckleberry Finn》 大约540KB。
John Steinbeck 的《The Grapes of Wrath》 大约 1MB。
Herman Melville的《Moby Dick》 大约1.3MB。
Henry Fielding 的 《The History of Tom Jones》 大约 2.25MB。
Margaret Mitchell的 《 Gone With the Wind 》 大约 2.5MB。
Stephen King 的《 The Stand》 大约2.7MB。
Leo Tolstoy 的《 War and Peace 》 大约3.9MB。
Marcel Proust 的 《Remembrance of Things Post》 大约 7.7MB。
美国国会图书馆大约有 20 000万本书,总共有 2 0万亿字符,即 2 0 T B的文本数据。 (图书馆还有大量的照片和录音。 )
尽管 A S C I I码是计算机世界里最重要的标准,但它并不是完美的。 A S C I I码的最大问题在于它太倾向于美国!的确, A S C I I码即使对那些以英语为主要语言的国家也几乎是不合适的。尽管 A S C I I码包含有美元符号,但英镑符号呢?还有许多西欧国家语言中用到的重音符号呢?更不用说在欧洲一些国家里使用的非拉丁字母,包括希腊文、阿拉伯文、希伯来文和西里尔
文。此外,还有印度及东南亚国家用到的婆罗门教的手迹。而一个 7位编码又如何来处理成千上万的中文、日文、韩文笔画以及韩语音节?
在研究 A S C I I码的时候,也一直在考虑其他国家的需要 ,尽管没有充分考虑非拉丁字母。根据公开的 A S C I I码标准, 1 0个A S C I I码代码( 4 0 h、 5 B h、 5 C h、 5 D h、 5 E h、 6 0 h、 7 B h、 7 C h、7 D h和 7 E h)可用来重新定义而为某一国家使用。另外,如果需要,数字符号( #)可用英镑符号(£)替换,美元符号( $)可用通用货币符号(¤)替换。显而易见,只有使用包含这些替换符号的特定文本文档的所有人都知道这些变化的时候,替换符号才有意义。
由于许多计算机系统按 8位来存储字符,则可以设计扩展的 A S C I I码字符集来包含 2 5 6个字符而不仅仅是 1 2 8个。在这样的字符集里,代码 0 0 h~ 7 F h定义成与 A S C I I码一致;代码 8 0 h~F F h可定义成表示另外的字符。这种技术已被用来定义附加的字符代码,包含重音字母及非拉丁字母。作为例子,这里有一个 9 6个字符的 A S C I I码的扩展,称之为第 1 号拉丁字母表,定义的字符编码从 A 0 h~ F F h。在该表里,十六进制字符编码的高半字节由最高行给出,低半字节由左边列给出:

代码A 0 h对应的字符为非断开空格。通常计算机处理格式文本是按照行和段来编排的,每一行以空格符号断开,对应的 A S C I I码为2 0 h。代码 A0h 用来显示一个空格,但不能用来断开一行。非断开空格可以用在如“ WW II ”这样的文本中。代码 A D h定义成软连字符,该连字符用来分开一个字中间的音节,且只在需要连接被两行分开的一个单词时才使用。
遗憾的是,近几十年来出现了许多不同的 A S C I I 码的扩展,导致了混淆和不兼容性。A S C I I码通过扩展甚至可以编码中文、日文和韩文的笔画。有一个流行的编码叫作 S h i f t - J I S(日本工业标准) ,其代码 8 1 h~ 9 F h用来表示 2字节字符编码的起始字节。以这种方法, S h i f t J I S可编码约 6 0 0 0个额外字符。遗憾的是, S h i f t - J I S不是使用这种技术的唯一系统。在亚洲,还有三个很流行的双字节字符集。
双字节字符集有许多问题,不兼容性只是其中之一。另一个问题是,一些字符—特别是普通的 A S C I I码字符—是用1个字节编码来表示的,而成千上万的笔画则是由双字节编码来表示,从而导致使用这样的字符集很困难。
在假定会有一个特定的字符编码系统能适用于世界上所有语言的前提下, 1 9 8 8年,几个主要的计算机公司一起开始研究一种替换 A S C I I码的编码,称为 U n i c o d e。鉴于 A S C I I码是 7位编码, U n i c o d e采用 1 6位编码,每一个字符需要 2个字节。这意味着 U n i c o d e的字符编码范围从0 0 0 0 h~ F F F F h,可以表示 65 536个不同字符。对世界上所有可用计算机进行来通信的语言来说,有足够的扩展空间。
U n i c o d e编码不是从零开始的,开始的 1 2 8个字符编码 0 0 0 0 h~ 0 0 7 F h与A S C I I码字符一致。U n i c o d e编码 0 0 A 0 h~ 0 0 F F h也与前面讲到的对 A S C I I码扩展的第 1 号拉丁字母表一致。其他世界范围的标准也收编在 U n i c o d e中。
尽管 U n i c o d e对现有的字符编码做了明显改进,但并不能保证它能很快被人们接受。A S C I I码和无数的有缺陷的扩展 A S C I I码已经在计算机世界中占有一席之地,要把它们逐出计算机世界并不是件容易的事。
对U n i c o d e来说的一个实实在在的问题是,它改变了一个文本字符与 1 个字节存储器之间的等效关系。用 A S C I I码编码, 《 The Grapes of Wr a t h》 这本书的大小约为 1M 字节;而用U n i c o d e编码,约是 2 M B,这也算是采用 U n i c o d e编码付出的代价吧。