版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u014248127/article/details/84887304
这是关于VQA问题的第五篇系列文章。本篇文章将介绍论文:主要思想;模型方法;主要贡献。有兴趣可以查看原文:Ask, Attend and Answer: Exploring Question-Guided Spatial Attention for Visual Question Answering。
1,主要思想:
论文采用基于空间(图像)的记忆网络(记忆网络是NLP领域中的模型,用于处理逻辑推理的问题)。Spatial Memory Network把图像存区域当做记忆单元的内容,然后用问题去选择相关的区域回答问题。论文同时采用多次attention,模拟寻找答案的推理过程。
2模型:
模型的结构和记忆网络的结构很相似:End to End Memory Network
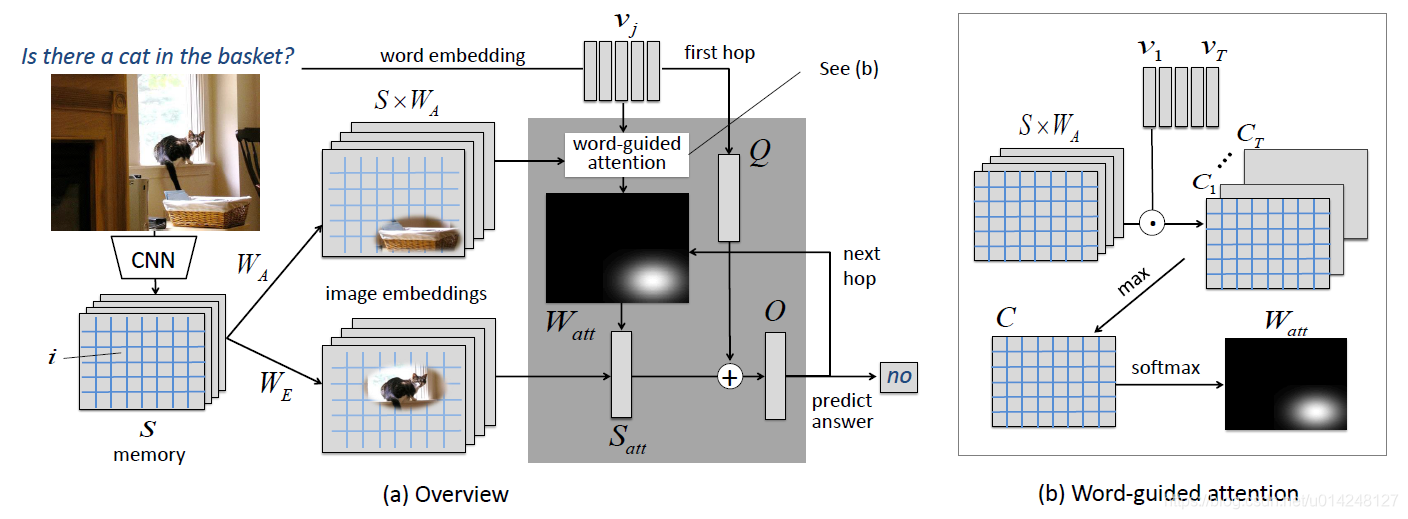
a.问题特征部分:
这里处理的很少,只是用词向量做embedding,得到句子的词向量矩阵。shape:(T,N)T是问题长度。
b.图像特征部分:
- 这里处理的也很少,用CNN提取各个区域的特征,GoogLeNet (inception 5b=output)。shape:(L,M)L是特征个数。
- 之后为了使得图像特征和问题特征维度一样,采用了两个矩阵进行变换,W_a,W_e。
c.Word Guided Spatial Attention in One-Hop Model(一次attention):
-
Word-guided attention:图b中,用单词词向量去计算与图像的相关性。计算过程就是选择关系最大的,然后用softmax进行归一化。(公式符号对应图中)
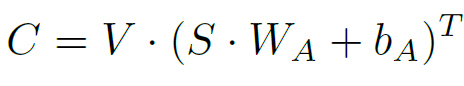
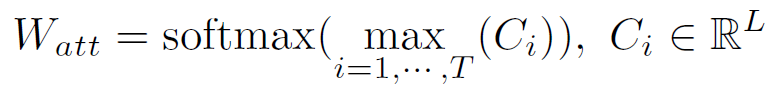
-
计算第一次attention的结果:如图a
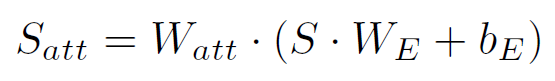
-
可以用这一次的attention的结果,加上问题进行预测了:如图a
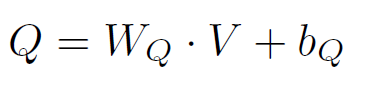
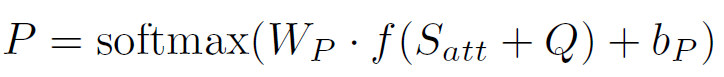
d.Spatial Attention in Two-Hop Model(多次attention,模拟推理)
-
计算第一次attention的结果,加上问题:如图a
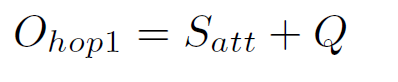
-
计算下一次attention的权重:如图a
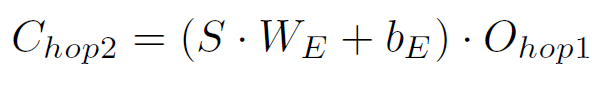
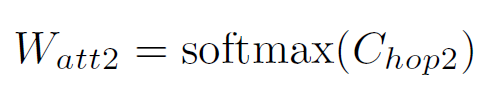
-
计算这一次attention的结果:
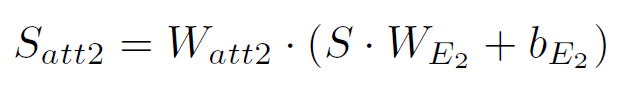
-
预测答案:
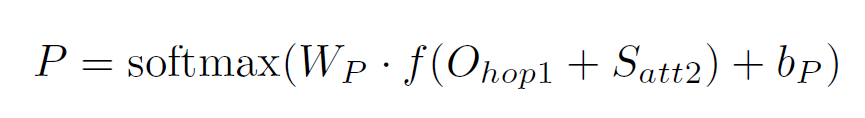
3,论文贡献:
- 提出使用Spatial Memory Network,模拟多次关注的寻找答案的推理过程。
- 在第一次attention时,提出了用每一个单词去计算与图像的相关性。从而实现第一次的相关性权重的计算。
- 实现了,多次attention,很好的结合的每次计算的结果用于答案的预测,从而实现模拟推理过程。